XANE: eXplainable Acoustic Neural Embeddings

0

Sign in to get full access
Overview
- The paper introduces XANE, a system that generates explainable acoustic neural embeddings for audio signals.
- XANE aims to provide interpretable insights into the underlying acoustic features learned by neural networks for various audio-related tasks.
- The system combines an autoencoder architecture with a feature interpretation module to extract and explain the relevant acoustic characteristics.
Plain English Explanation
XANE is a new system that helps us understand how artificial intelligence (AI) models process and analyze audio signals. When we use AI for tasks like speech recognition or music classification, the inner workings of the AI can be like a "black box" - it's not always clear how the model is making its decisions.
The XANE system tries to open up this "black box" by generating explanations for the key acoustic features that the AI model is focusing on. For example, if the AI is trying to identify a certain type of bird call, XANE can point to specific sound characteristics like pitch, rhythm, or timbre that the model is using to make that classification.
By providing these explanations, XANE aims to make AI-powered audio analysis more transparent and trustworthy. It allows users to see the reasoning behind the AI's outputs, rather than just accepting them at face value. This can be especially important in critical applications like medical diagnosis or safety monitoring, where we want to fully understand the basis for the AI's decisions.
The core of XANE is an "autoencoder" architecture, which is a type of neural network that can learn efficient representations of data. XANE pairs this with an additional module that interprets the key acoustic features captured by the autoencoder. This interpretation component is what generates the explanations that make the system "explainable."
Overall, XANE represents an important step towards building more interpretable and trustworthy AI systems for a wide range of audio-related applications. By shedding light on the inner workings of these models, it can help us better understand and validate their decision-making processes.
Technical Explanation
The XANE system [1] combines an autoencoder architecture with a feature interpretation module to generate explainable acoustic embeddings from audio signals. The autoencoder learns a compressed, latent representation of the input audio, while the interpretation module identifies and explains the key acoustic features captured by the latent space.
The autoencoder consists of an encoder network that maps the input audio to a low-dimensional embedding, and a decoder network that reconstructs the original audio from the embedding. This architecture allows the model to learn efficient representations of the acoustic data. The interpretation module then analyzes the latent embedding to identify the most salient acoustic characteristics that the autoencoder has focused on.
To achieve this, the interpretation module employs techniques from [2] and [3] to attribute importance scores to individual dimensions of the latent embedding. These importance scores indicate which acoustic features (e.g., pitch, timbre, rhythm) are most significant in the model's processing of the input audio. By visualizing these importance scores, XANE can provide interpretable explanations of the underlying acoustic features learned by the autoencoder.
The XANE system is evaluated on a range of audio classification tasks, demonstrating its ability to generate accurate predictions while also providing transparent, explainable insights into the model's decision-making process. This aligns with recent trends in [4] and [5] towards building more interpretable and trustworthy AI systems.
Critical Analysis
The XANE paper presents a compelling approach to generating explainable acoustic embeddings, addressing an important challenge in the field of audio-based AI. By combining an autoencoder architecture with feature interpretation techniques, the system provides a novel way to shed light on the inner workings of audio processing models.
One potential limitation of the XANE system is its reliance on the autoencoder architecture, which may not capture all the nuances of complex audio signals. Additionally, the interpretation module, while effective, relies on attribution methods that can be sensitive to the specific model architecture and hyperparameters.
Further research could explore alternative neural network architectures or interpretation techniques that may be even more effective at generating comprehensive and robust explanations for the learned acoustic features. Validating the XANE system's performance and interpretability across a wider range of audio tasks and domains would also help to establish its broader applicability.
Overall, the XANE system represents a significant step forward in the pursuit of more transparent and trustworthy AI for audio-related applications. By shedding light on the inner workings of these models, it has the potential to enhance user trust, enable better model debugging and refinement, and ultimately, drive further advancements in the field of explainable AI.
Conclusion
The XANE system introduces a novel approach to generating explainable acoustic neural embeddings, addressing a critical challenge in the development of interpretable audio-based AI. By combining an autoencoder architecture with a feature interpretation module, XANE provides transparent insights into the key acoustic characteristics learned by neural networks for various audio processing tasks.
The system's ability to attribute importance scores to individual dimensions of the latent embedding allows for the generation of interpretable explanations, which can enhance user trust and enable better model understanding and refinement. As the field of explainable AI continues to evolve, XANE represents an important step towards building more trustworthy and accountable AI systems for a wide range of audio-related applications, from speech recognition to music analysis.
[1] XANE: eXplainable Acoustic Neural Embeddings [2] Toward End-to-End Interpretable Convolutional Neural Networks for Image Classification [3] Enhancing Apparent Personality Trait Analysis with Cross-Modal Explainable AI [4] Unveiling Hidden Factors for Explainable AI Feature Boosting [5] Understanding Auditory Evoked Brain Signal via Physics-Constrained Predictive Learning Model
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
XANE: eXplainable Acoustic Neural Embeddings
Sri Harsha Dumpala, Dushyant Sharma, Chandramouli Shama Sastri, Stanislav Kruchinin, James Fosburgh, Patrick A. Naylor
We present a novel method for extracting neural embeddings that model the background acoustics of a speech signal. The extracted embeddings are used to estimate specific parameters related to the background acoustic properties of the signal in a non-intrusive manner, which allows the embeddings to be explainable in terms of those parameters. We illustrate the value of these embeddings by performing clustering experiments on unseen test data and show that the proposed embeddings achieve a mean F1 score of 95.2% for three different tasks, outperforming significantly the WavLM based signal embeddings. We also show that the proposed method can explain the embeddings by estimating 14 acoustic parameters characterizing the background acoustics, including reverberation and noise levels, overlapped speech detection, CODEC type detection and noise type detection with high accuracy and a real-time factor 17 times lower than an external baseline method.
Read more6/11/2024

0
XANE Background Acoustic Embeddings: Ablation and Clustering Analysis
Dushyant Sharma, James Fosburgh, Sri Harsha Dumpala, Chandramouli Shama Sastri, Stanislav Yu. Kruchinin, Patrick A. Naylor
We explore the recently proposed explainable acoustic neural embedding~(XANE) system that models the background acoustics of a speech signal in a non-intrusive manner. The XANE embeddings are used to estimate specific parameters related to the background acoustic properties of the signal which allows the embeddings to be explainable in terms of those parameters. We perform ablation studies on the XANE system and show that estimating all acoustic parameters jointly has an overall positive effect. Furthermore, we illustrate the value of XANE embeddings by performing clustering experiments on unseen test data and show that the proposed embeddings achieve a mean F1 score of 92% for three different tasks, outperforming significantly the WavLM based signal embeddings and are complimentary to speaker embeddings.
Read more7/10/2024

0
Explaining Deep Learning Embeddings for Speech Emotion Recognition by Predicting Interpretable Acoustic Features
Satvik Dixit, Daniel M. Low, Gasser Elbanna, Fabio Catania, Satrajit S. Ghosh
Pre-trained deep learning embeddings have consistently shown superior performance over handcrafted acoustic features in speech emotion recognition (SER). However, unlike acoustic features with clear physical meaning, these embeddings lack clear interpretability. Explaining these embeddings is crucial for building trust in healthcare and security applications and advancing the scientific understanding of the acoustic information that is encoded in them. This paper proposes a modified probing approach to explain deep learning embeddings in the SER space. We predict interpretable acoustic features (e.g., f0, loudness) from (i) the complete set of embeddings and (ii) a subset of the embedding dimensions identified as most important for predicting each emotion. If the subset of the most important dimensions better predicts a given emotion than all dimensions and also predicts specific acoustic features more accurately, we infer those acoustic features are important for the embedding model for the given task. We conducted experiments using the WavLM embeddings and eGeMAPS acoustic features as audio representations, applying our method to the RAVDESS and SAVEE emotional speech datasets. Based on this evaluation, we demonstrate that Energy, Frequency, Spectral, and Temporal categories of acoustic features provide diminishing information to SER in that order, demonstrating the utility of the probing classifier method to relate embeddings to interpretable acoustic features.
Read more9/17/2024
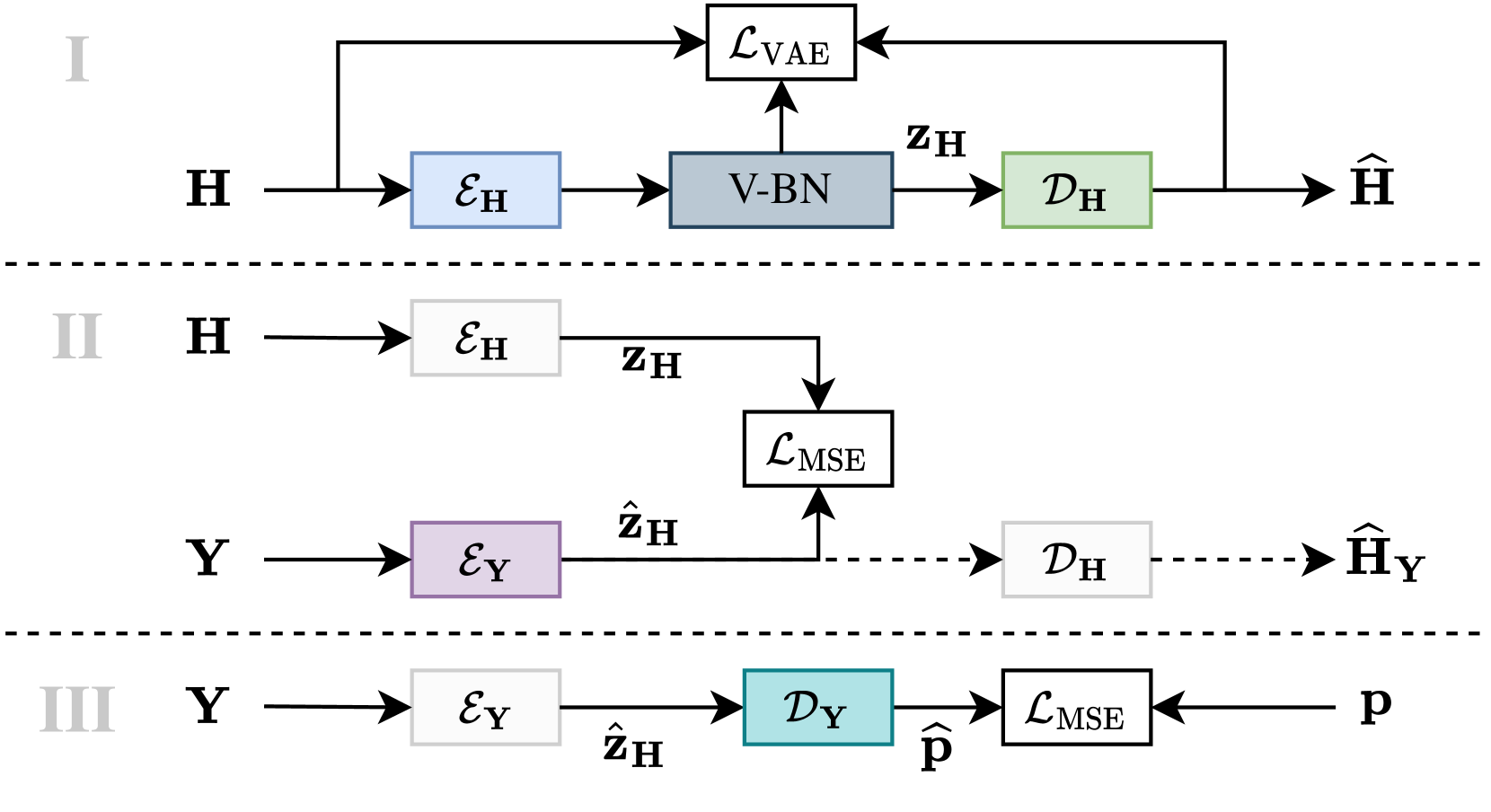
0
Blind Acoustic Parameter Estimation Through Task-Agnostic Embeddings Using Latent Approximations
Philipp Gotz, Cagdas Tuna, Andreas Brendel, Andreas Walther, Emanuel A. P. Habets
We present a method for blind acoustic parameter estimation from single-channel reverberant speech. The method is structured into three stages. In the first stage, a variational auto-encoder is trained to extract latent representations of acoustic impulse responses represented as mel-spectrograms. In the second stage, a separate speech encoder is trained to estimate low-dimensional representations from short segments of reverberant speech. Finally, the pre-trained speech encoder is combined with a small regression model and evaluated on two parameter regression tasks. Experimentally, the proposed method is shown to outperform a fully end-to-end trained baseline model.
Read more7/30/2024