xLAM: A Family of Large Action Models to Empower AI Agent Systems

0
🤖
Sign in to get full access
Overview
- Researchers are exploring the use of large language models (LLMs) to power autonomous agents.
- Developing specialized models for agent tasks is challenging due to a lack of high-quality datasets and standardized protocols.
- The authors introduce and release xLAM, a series of large action models designed for AI agent tasks.
Plain English Explanation
The paper discusses the development of xLAM, a set of powerful AI models designed to control autonomous agents. Autonomous agents are computer programs that can perform tasks on their own, without direct human control. The researchers wanted to create models that could help these agents perform a wide variety of tasks more effectively.
One of the main challenges is that there isn't a lot of high-quality data available for training models specifically for agent tasks. The researchers worked to unify, expand, and synthesize diverse datasets to train their models, which they call the xLAM series. These models come in different sizes, from 1 billion to 8x22 billion parameters, and use different architectural approaches.
Through extensive testing, the researchers found that the xLAM models consistently outperformed other state-of-the-art language models, including GPT-4 and Claude-3, on a variety of benchmarks for evaluating an agent's capabilities. This suggests the xLAM models could be very useful for powering autonomous agents that need to perform complex tasks in diverse environments.
Technical Explanation
The paper introduces the xLAM series, a set of large action models designed for AI agent tasks. The researchers developed a scalable and flexible pipeline to unify, augment, and synthesize diverse datasets, which was used to train five xLAM models with both dense and mixture-of-expert architectures, ranging from 1 billion to 8x22 billion parameters.
The researchers evaluated the xLAM models on multiple agent ability benchmarks and found that they consistently outperformed other state-of-the-art language models, including securing the 1st position on the Berkeley Function-Calling Leaderboard and outperforming GPT-4 and Claude-3 in terms of tool use.
Critical Analysis
The paper provides a promising approach to developing specialized models for autonomous agent tasks, which is an important area of research. However, the authors do not discuss any potential limitations or caveats of their work. For example, it would be helpful to understand the specific datasets used, how they were synthesized, and any biases or gaps in the training data that could affect the models' performance in real-world scenarios.
Additionally, the paper does not address potential ethical concerns around the use of powerful AI agents, such as issues of transparency, accountability, and the potential for misuse. As these models become more capable, it will be crucial to consider their societal implications and ensure they are developed and deployed responsibly.
Conclusion
The xLAM series represents a significant advancement in the development of specialized models for autonomous agent tasks. By unifying and expanding diverse datasets, the researchers have created a set of powerful models that consistently outperform other state-of-the-art language models on a variety of benchmarks. This work has the potential to accelerate progress in the field of autonomous agents and democratize access to high-performance models for these tasks. However, further research is needed to address potential limitations and ethical considerations as these models become more capable and widely adopted.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
xLAM: A Family of Large Action Models to Empower AI Agent Systems
Jianguo Zhang, Tian Lan, Ming Zhu, Zuxin Liu, Thai Hoang, Shirley Kokane, Weiran Yao, Juntao Tan, Akshara Prabhakar, Haolin Chen, Zhiwei Liu, Yihao Feng, Tulika Awalgaonkar, Rithesh Murthy, Eric Hu, Zeyuan Chen, Ran Xu, Juan Carlos Niebles, Shelby Heinecke, Huan Wang, Silvio Savarese, Caiming Xiong
Autonomous agents powered by large language models (LLMs) have attracted significant research interest. However, the open-source community faces many challenges in developing specialized models for agent tasks, driven by the scarcity of high-quality agent datasets and the absence of standard protocols in this area. We introduce and publicly release xLAM, a series of large action models designed for AI agent tasks. The xLAM series includes five models with both dense and mixture-of-expert architectures, ranging from 1B to 8x22B parameters, trained using a scalable, flexible pipeline that unifies, augments, and synthesizes diverse datasets to enhance AI agents' generalizability and performance across varied environments. Our experimental results demonstrate that xLAM consistently delivers exceptional performance across multiple agent ability benchmarks, notably securing the 1st position on the Berkeley Function-Calling Leaderboard, outperforming GPT-4, Claude-3, and many other models in terms of tool use. By releasing the xLAM series, we aim to advance the performance of open-source LLMs for autonomous AI agents, potentially accelerating progress and democratizing access to high-performance models for agent tasks. Models are available at https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4
Read more9/6/2024
📈
0
LAMBDA: A Large Model Based Data Agent
Maojun Sun, Ruijian Han, Binyan Jiang, Houduo Qi, Defeng Sun, Yancheng Yuan, Jian Huang
We introduce LArge Model Based Data Agent (LAMBDA), a novel open-source, code-free multi-agent data analysis system that leverages the power of large models. LAMBDA is designed to address data analysis challenges in complex data-driven applications through innovatively designed data agents that operate iteratively and generatively using natural language. At the core of LAMBDA are two key agent roles: the programmer and the inspector, which are engineered to work together seamlessly. Specifically, the programmer generates code based on the user's instructions and domain-specific knowledge, enhanced by advanced models. Meanwhile, the inspector debugs the code when necessary. To ensure robustness and handle adverse scenarios, LAMBDA features a user interface that allows direct user intervention in the operational loop. Additionally, LAMBDA can flexibly integrate external models and algorithms through our proposed Knowledge Integration Mechanism, catering to the needs of customized data analysis. LAMBDA has demonstrated strong performance on various data analysis tasks. It has the potential to enhance data analysis paradigms by seamlessly integrating human and artificial intelligence, making it more accessible, effective, and efficient for users from diverse backgrounds. The strong performance of LAMBDA in solving data analysis problems is demonstrated using real-world data examples. Videos of several case studies are available at https://xxxlambda.github.io/lambda_webpage.
Read more9/17/2024
0
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
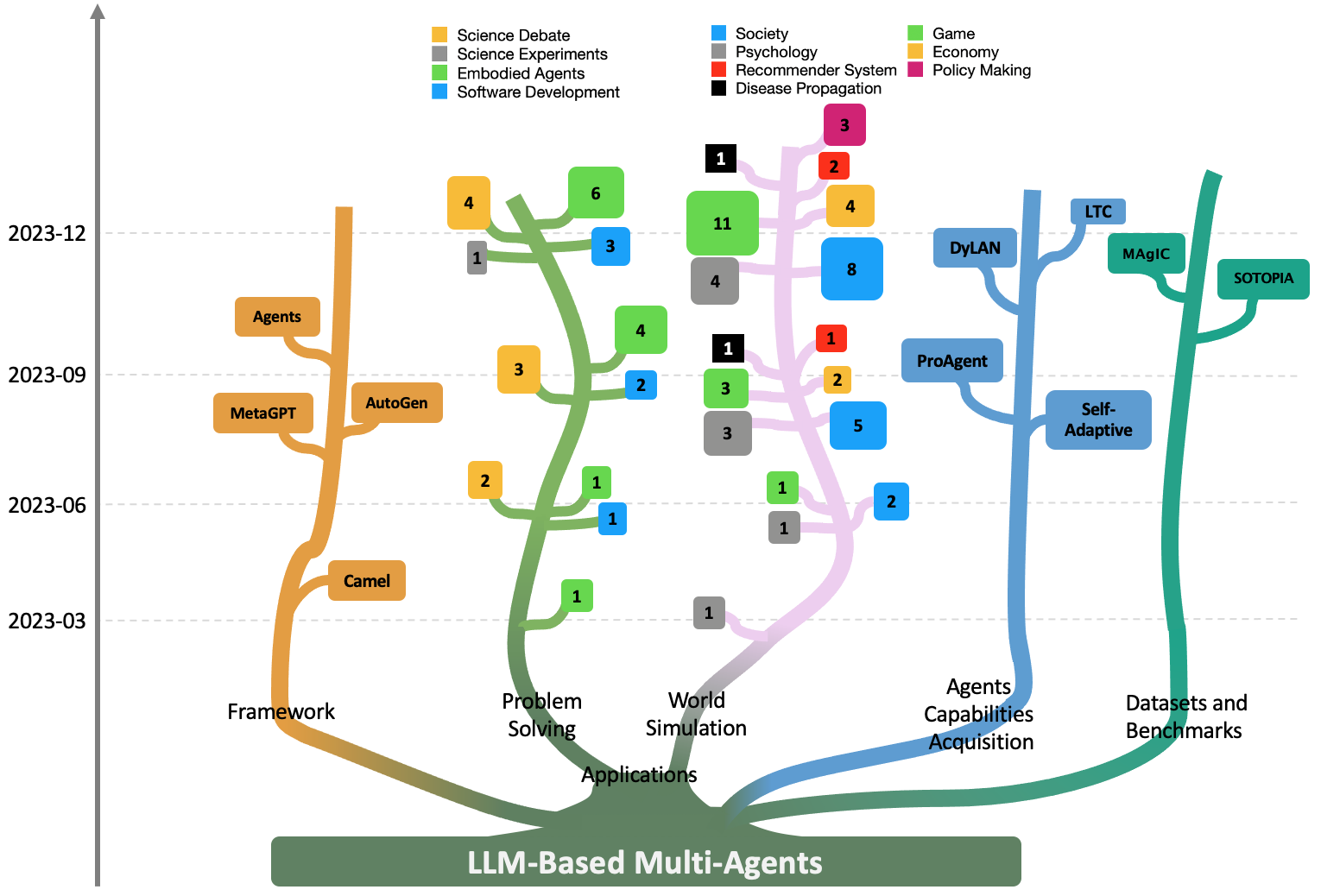
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, Xiangliang Zhang
Large Language Models (LLMs) have achieved remarkable success across a wide array of tasks. Due to the impressive planning and reasoning abilities of LLMs, they have been used as autonomous agents to do many tasks automatically. Recently, based on the development of using one LLM as a single planning or decision-making agent, LLM-based multi-agent systems have achieved considerable progress in complex problem-solving and world simulation. To provide the community with an overview of this dynamic field, we present this survey to offer an in-depth discussion on the essential aspects of multi-agent systems based on LLMs, as well as the challenges. Our goal is for readers to gain substantial insights on the following questions: What domains and environments do LLM-based multi-agents simulate? How are these agents profiled and how do they communicate? What mechanisms contribute to the growth of agents' capacities? For those interested in delving into this field of study, we also summarize the commonly used datasets or benchmarks for them to have convenient access. To keep researchers updated on the latest studies, we maintain an open-source GitHub repository, dedicated to outlining the research on LLM-based multi-agent systems.
Read more4/22/2024
0
A Survey on Large Language Model-Based Game Agents
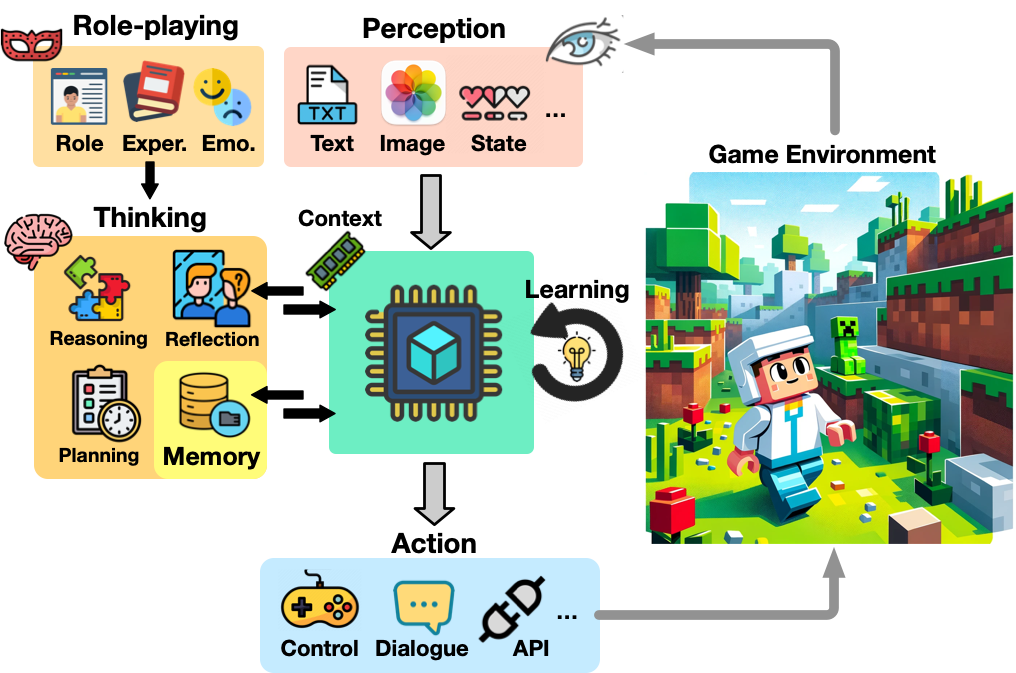
Sihao Hu, Tiansheng Huang, Fatih Ilhan, Selim Tekin, Gaowen Liu, Ramana Kompella, Ling Liu
The development of game agents holds a critical role in advancing towards Artificial General Intelligence (AGI). The progress of LLMs and their multimodal counterparts (MLLMs) offers an unprecedented opportunity to evolve and empower game agents with human-like decision-making capabilities in complex computer game environments. This paper provides a comprehensive overview of LLM-based game agents from a holistic viewpoint. First, we introduce the conceptual architecture of LLM-based game agents, centered around six essential functional components: perception, memory, thinking, role-playing, action, and learning. Second, we survey existing representative LLM-based game agents documented in the literature with respect to methodologies and adaptation agility across six genres of games, including adventure, communication, competition, cooperation, simulation, and crafting & exploration games. Finally, we present an outlook of future research and development directions in this burgeoning field. A curated list of relevant papers is maintained and made accessible at: https://github.com/git-disl/awesome-LLM-game-agent-papers.
Read more4/3/2024