xLSTM: Extended Long Short-Term Memory
2405.04517
195
0
🏷️
Abstract
In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerous deep learning success stories, in particular they constituted the first Large Language Models (LLMs). However, the advent of the Transformer technology with parallelizable self-attention at its core marked the dawn of a new era, outpacing LSTMs at scale. We now raise a simple question: How far do we get in language modeling when scaling LSTMs to billions of parameters, leveraging the latest techniques from modern LLMs, but mitigating known limitations of LSTMs? Firstly, we introduce exponential gating with appropriate normalization and stabilization techniques. Secondly, we modify the LSTM memory structure, obtaining: (i) sLSTM with a scalar memory, a scalar update, and new memory mixing, (ii) mLSTM that is fully parallelizable with a matrix memory and a covariance update rule. Integrating these LSTM extensions into residual block backbones yields xLSTM blocks that are then residually stacked into xLSTM architectures. Exponential gating and modified memory structures boost xLSTM capabilities to perform favorably when compared to state-of-the-art Transformers and State Space Models, both in performance and scaling.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Long Short-Term Memory (LSTM) networks have been a central idea in deep learning since the 1990s.
- LSTMs have contributed to numerous deep learning successes, including the first Large Language Models (LLMs).
- Transformers, with their parallelizable self-attention, have recently outpaced LSTMs at scale.
- This research explores how far LSTMs can go when scaled to billions of parameters and combined with modern LLM techniques.
Plain English Explanation
LSTMs are a type of neural network that were first introduced in the 1990s. They have been very successful in many deep learning applications, including helping to create the first large language models used for tasks like generating human-like text. However, a newer type of network called a Transformer has recently been shown to work even better, especially when scaled up to very large sizes.
This research asks: Can we take LSTMs, make them much bigger, and combine them with the latest techniques from large language models, to see how well they can perform compared to Transformers? The key ideas are:
- Using a new type of "exponential gating" to help the LSTM network learn better.
- Changing the internal structure of the LSTM to make it more efficient and parallelizable.
By incorporating these LSTM extensions, the researchers were able to create "xLSTM" models that performed well compared to state-of-the-art Transformers and other advanced models, both in terms of performance and how easily they can be scaled up.
Technical Explanation
The paper introduces two main technical innovations to enhance LSTM performance:
-
Exponential Gating: The researchers replace the standard LSTM gating mechanism with an "exponential gating" approach, which uses appropriate normalization and stabilization techniques to improve learning.
-
Modified Memory Structure: The paper proposes two new LSTM variants:
These LSTM extensions are then integrated into "xLSTM" residual block architectures, which are stacked to create the final xLSTM models. The researchers find that the xLSTM models can perform on par with state-of-the-art Transformers and State Space Models, both in terms of performance and scalability.
Critical Analysis
The paper presents a thorough exploration of enhancing LSTM performance through architectural modifications. The proposed xLSTM models demonstrate promising results, suggesting that LSTMs can still be competitive with more recent Transformer-based approaches when scaled up and combined with modern techniques.
However, the paper does not delve deeply into the broader implications or potential limitations of the xLSTM approach. For example, it would be valuable to understand the computational and memory efficiency of the xLSTM models compared to Transformers, as well as their performance on a wider range of tasks beyond language modeling.
Additionally, the paper does not address potential issues around the interpretability or explainability of the xLSTM models, which could be an important consideration for certain applications. Further research in these areas could help provide a more comprehensive understanding of the strengths and weaknesses of the xLSTM approach.
Conclusion
This research demonstrates that LSTMs can still be a viable and competitive option for large-scale language modeling, even in the era of Transformers. By introducing exponential gating and modified memory structures, the researchers were able to create xLSTM models that perform on par with state-of-the-art Transformer and State Space models.
While the paper focuses primarily on the technical details of the xLSTM architecture, the results suggest that LSTMs may still have untapped potential in deep learning, especially when combined with modern techniques and scaled to large sizes. This work could inspire further research into enhancing LSTM performance and exploring its continued relevance in the rapidly evolving field of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
StableSSM: Alleviating the Curse of Memory in State-space Models through Stable Reparameterization
Shida Wang, Qianxiao Li
0
0
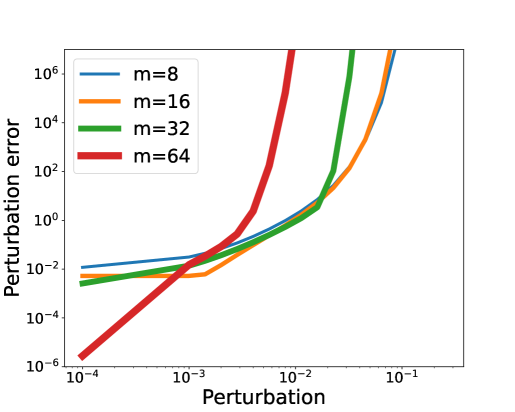
In this paper, we investigate the long-term memory learning capabilities of state-space models (SSMs) from the perspective of parameterization. We prove that state-space models without any reparameterization exhibit a memory limitation similar to that of traditional RNNs: the target relationships that can be stably approximated by state-space models must have an exponential decaying memory. Our analysis identifies this ``curse of memory'' as a result of the recurrent weights converging to a stability boundary, suggesting that a reparameterization technique can be effective. To this end, we introduce a class of reparameterization techniques for SSMs that effectively lift its memory limitations. Besides improving approximation capabilities, we further illustrate that a principled choice of reparameterization scheme can also enhance optimization stability. We validate our findings using synthetic datasets, language models and image classifications.
5/3/2024
🎲
Rewiring the Transformer with Depth-Wise LSTMs
Hongfei Xu, Yang Song, Qiuhui Liu, Josef van Genabith, Deyi Xiong
0
0
Stacking non-linear layers allows deep neural networks to model complicated functions, and including residual connections in Transformer layers is beneficial for convergence and performance. However, residual connections may make the model forget distant layers and fail to fuse information from previous layers effectively. Selectively managing the representation aggregation of Transformer layers may lead to better performance. In this paper, we present a Transformer with depth-wise LSTMs connecting cascading Transformer layers and sub-layers. We show that layer normalization and feed-forward computation within a Transformer layer can be absorbed into depth-wise LSTMs connecting pure Transformer attention layers. Our experiments with the 6-layer Transformer show significant BLEU improvements in both WMT 14 English-German / French tasks and the OPUS-100 many-to-many multilingual NMT task, and our deep Transformer experiments demonstrate the effectiveness of depth-wise LSTM on the convergence and performance of deep Transformers.
4/5/2024
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
0
0
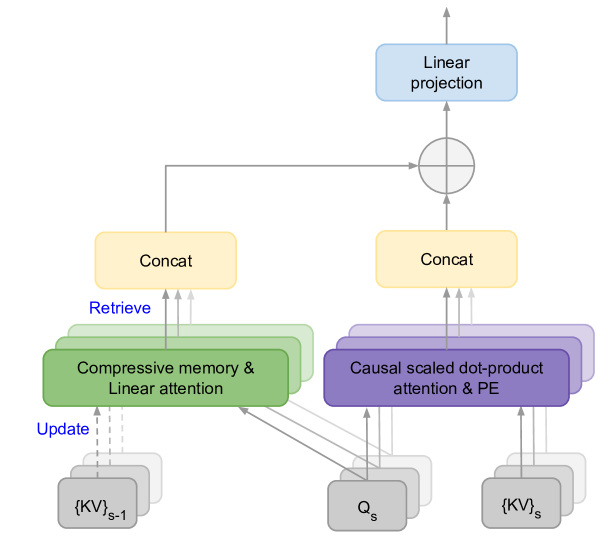
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
4/11/2024
HMT: Hierarchical Memory Transformer for Long Context Language Processing
Zifan He, Zongyue Qin, Neha Prakriya, Yizhou Sun, Jason Cong
0
0
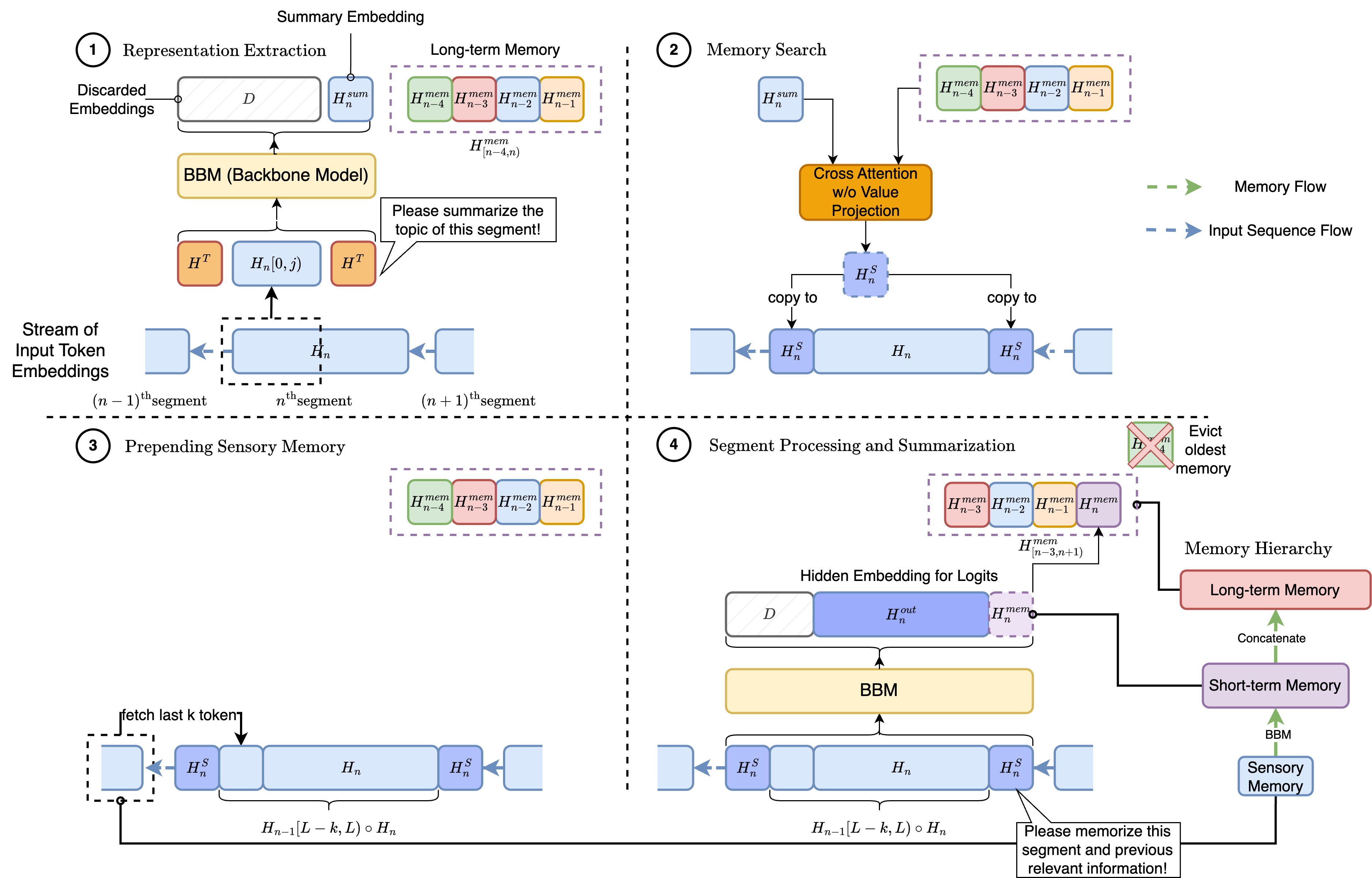
Transformer-based large language models (LLM) have been widely used in language processing applications. However, most of them restrict the context window that permits the model to attend to every token in the inputs. Previous works in recurrent models can memorize past tokens to enable unlimited context and maintain effectiveness. However, they have flat memory architectures, which have limitations in selecting and filtering information. Since humans are good at learning and self-adjustment, we speculate that imitating brain memory hierarchy is beneficial for model memorization. We propose the Hierarchical Memory Transformer (HMT), a novel framework that enables and improves models' long-context processing ability by imitating human memorization behavior. Leveraging memory-augmented segment-level recurrence, we organize the memory hierarchy by preserving tokens from early input token segments, passing memory embeddings along the sequence, and recalling relevant information from history. Evaluating general language modeling (Wikitext-103, PG-19) and question-answering tasks (PubMedQA), we show that HMT steadily improves the long-context processing ability of context-constrained and long-context models. With an additional 0.5% - 2% of parameters, HMT can easily plug in and augment future LLMs to handle long context effectively. Our code is open-sourced on Github: https://github.com/OswaldHe/HMT-pytorch.
5/15/2024