Xmodel-VLM: A Simple Baseline for Multimodal Vision Language Model

0
Sign in to get full access
Overview
- Presents a simple baseline for multimodal vision-language models called Xmodel-VLM
- Evaluates the performance of Xmodel-VLM on various vision-language tasks
- Demonstrates the potential of a simple model to serve as a strong starting point for more advanced vision-language research
Plain English Explanation
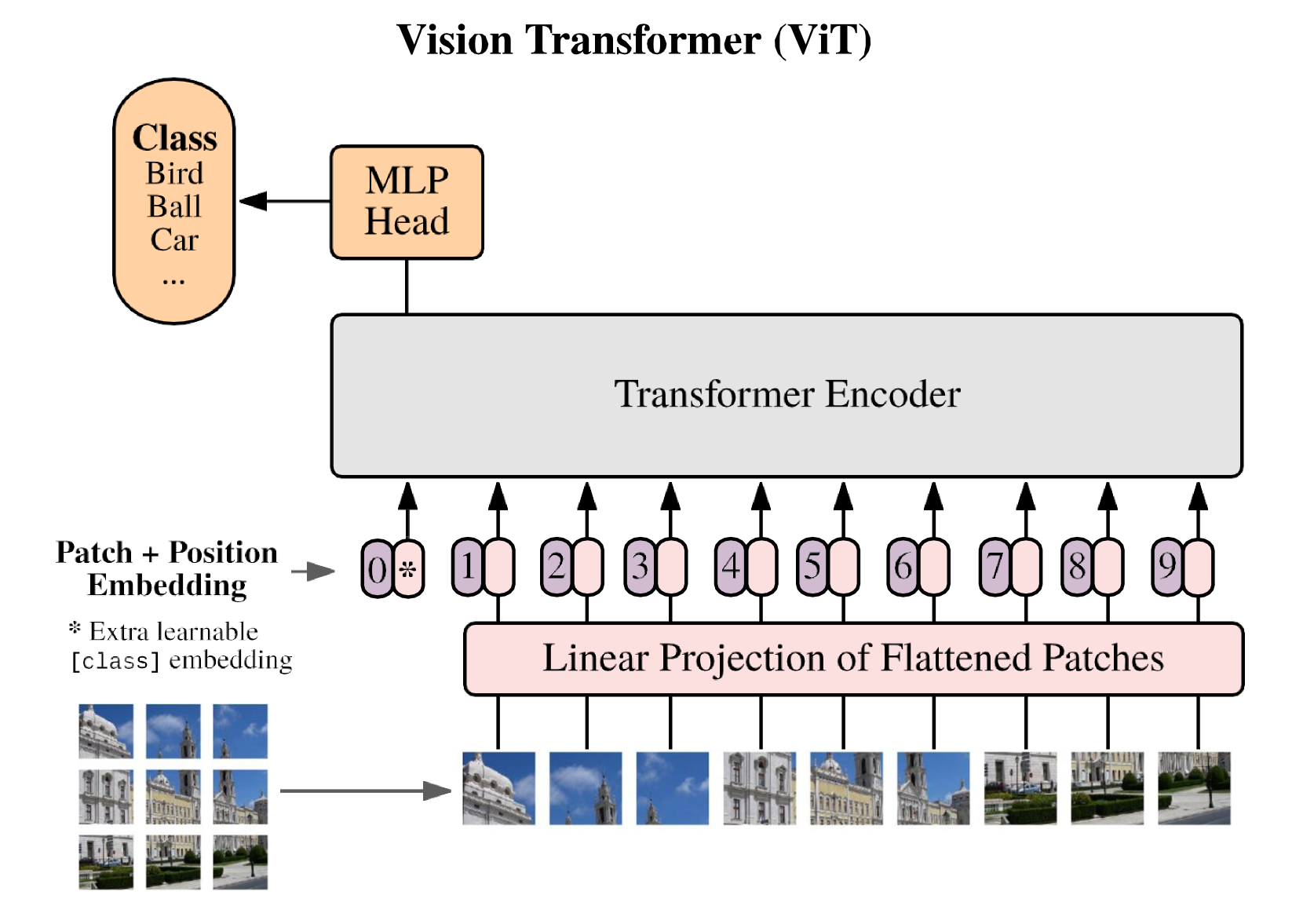
The paper introduces a basic model called Xmodel-VLM that can handle both visual and textual information. This type of "multimodal" model is useful for tasks that involve understanding the relationship between images and text, such as image captioning or visual question answering.
The key idea behind Xmodel-VLM is to take a pre-trained language model, like BERT, and combine it with a pre-trained visual model, like ResNet. By leveraging these pre-trained components, the authors create a simple yet powerful multimodal model that can be trained more efficiently than building everything from scratch.
The researchers evaluate Xmodel-VLM on a variety of vision-language tasks, and find that it performs surprisingly well, often matching or exceeding the performance of more complex state-of-the-art models. This suggests that a simple baseline like Xmodel-VLM can serve as a strong starting point for further research in this area.
Technical Explanation
The key components of Xmodel-VLM are:
-
Visual Encoder: The authors use a pre-trained ResNet model to encode visual inputs into a compact representation.
-
Text Encoder: They use a pre-trained BERT model to encode textual inputs.
-
Multimodal Fusion: The visual and textual representations are then combined using a simple concatenation operation, and passed through additional neural network layers to produce the final output.
The authors evaluate Xmodel-VLM on a range of vision-language tasks, including:
- Image Captioning: Generating textual descriptions of images.
- Visual Question Answering: Answering questions about the content of images.
- Referring Expression Comprehension: Identifying the image region referred to by a textual description.
Surprisingly, the researchers find that Xmodel-VLM often performs on par with or better than more complex state-of-the-art vision-language models, such as LXMERT, ViLT, and UNITER.
Critical Analysis
The paper demonstrates the potential of a simple baseline model to serve as a strong starting point for more advanced vision-language research. However, the authors acknowledge several limitations of Xmodel-VLM:
-
Limited Multimodal Interaction: The simple concatenation-based fusion method may not fully capture the complex interactions between visual and textual information.
-
Task-Specific Fine-Tuning: The model still requires task-specific fine-tuning to achieve good performance on specific vision-language tasks.
-
Scalability Concerns: As the size and complexity of the pre-trained components increase, the training and inference costs of Xmodel-VLM may also grow, limiting its scalability.
Future research could explore more sophisticated multimodal fusion techniques, as well as ways to make the model more scalable and generalizable across a wider range of vision-language tasks. Additionally, the authors could delve deeper into the strengths and weaknesses of Xmodel-VLM compared to more complex state-of-the-art models.
Conclusion
The paper presents a simple yet effective baseline for multimodal vision-language models, called Xmodel-VLM. The key innovation is the use of pre-trained visual and textual encoders, which allows Xmodel-VLM to achieve strong performance on a variety of vision-language tasks with a relatively simple architecture.
The success of this basic model highlights the potential for simple baselines to serve as a foundation for more advanced research in the field of multimodal learning. By understanding the capabilities and limitations of such baselines, researchers can develop more sophisticated vision-language models that build upon these foundations and push the boundaries of what is possible in this rapidly evolving area of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Xmodel-VLM: A Simple Baseline for Multimodal Vision Language Model
Wanting Xu, Yang Liu, Langping He, Xucheng Huang, Ling Jiang
We introduce Xmodel-VLM, a cutting-edge multimodal vision language model. It is designed for efficient deployment on consumer GPU servers. Our work directly confronts a pivotal industry issue by grappling with the prohibitive service costs that hinder the broad adoption of large-scale multimodal systems. Through rigorous training, we have developed a 1B-scale language model from the ground up, employing the LLaVA paradigm for modal alignment. The result, which we call Xmodel-VLM, is a lightweight yet powerful multimodal vision language model. Extensive testing across numerous classic multimodal benchmarks has revealed that despite its smaller size and faster execution, Xmodel-VLM delivers performance comparable to that of larger models. Our model checkpoints and code are publicly available on GitHub at https://github.com/XiaoduoAILab/XmodelVLM.
Read more6/21/2024

0
NVLM: Open Frontier-Class Multimodal LLMs
Wenliang Dai, Nayeon Lee, Boxin Wang, Zhuoling Yang, Zihan Liu, Jon Barker, Tuomas Rintamaki, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping
We introduce NVLM 1.0, a family of frontier-class multimodal large language models (LLMs) that achieve state-of-the-art results on vision-language tasks, rivaling the leading proprietary models (e.g., GPT-4o) and open-access models (e.g., Llama 3-V 405B and InternVL 2). Remarkably, NVLM 1.0 shows improved text-only performance over its LLM backbone after multimodal training. In terms of model design, we perform a comprehensive comparison between decoder-only multimodal LLMs (e.g., LLaVA) and cross-attention-based models (e.g., Flamingo). Based on the strengths and weaknesses of both approaches, we propose a novel architecture that enhances both training efficiency and multimodal reasoning capabilities. Furthermore, we introduce a 1-D tile-tagging design for tile-based dynamic high-resolution images, which significantly boosts performance on multimodal reasoning and OCR-related tasks. Regarding training data, we meticulously curate and provide detailed information on our multimodal pretraining and supervised fine-tuning datasets. Our findings indicate that dataset quality and task diversity are more important than scale, even during the pretraining phase, across all architectures. Notably, we develop production-grade multimodality for the NVLM-1.0 models, enabling them to excel in vision-language tasks while maintaining and even improving text-only performance compared to their LLM backbones. To achieve this, we craft and integrate a high-quality text-only dataset into multimodal training, alongside a substantial amount of multimodal math and reasoning data, leading to enhanced math and coding capabilities across modalities. To advance research in the field, we are releasing the model weights and will open-source the code for the community: https://nvlm-project.github.io/.
Read more9/18/2024

0
Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
Read more4/16/2024
💬
0
MammothModa: Multi-Modal Large Language Model
Qi She, Junwen Pan, Xin Wan, Rui Zhang, Dawei Lu, Kai Huang
In this report, we introduce MammothModa, yet another multi-modal large language model (MLLM) designed to achieve state-of-the-art performance starting from an elementary baseline. We focus on three key design insights: (i) Integrating Visual Capabilities while Maintaining Complex Language Understanding: In addition to the vision encoder, we incorporated the Visual Attention Experts into the LLM to enhance its visual capabilities. (ii) Extending Context Window for High-Resolution and Long-Duration Visual Feature: We explore the Visual Merger Module to effectively reduce the token number of high-resolution images and incorporated frame position ids to avoid position interpolation. (iii) High-Quality Bilingual Datasets: We meticulously curated and filtered a high-quality bilingual multimodal dataset to reduce visual hallucinations. With above recipe we build MammothModa that consistently outperforms the state-of-the-art models, e.g., LLaVA-series, across main real-world visual language benchmarks without bells and whistles.
Read more6/27/2024