You don't need a personality test to know these models are unreliable: Assessing the Reliability of Large Language Models on Psychometric Instruments
2311.09718
0
0
💬
Abstract
The versatility of Large Language Models (LLMs) on natural language understanding tasks has made them popular for research in social sciences. To properly understand the properties and innate personas of LLMs, researchers have performed studies that involve using prompts in the form of questions that ask LLMs about particular opinions. In this study, we take a cautionary step back and examine whether the current format of prompting LLMs elicits responses in a consistent and robust manner. We first construct a dataset that contains 693 questions encompassing 39 different instruments of persona measurement on 115 persona axes. Additionally, we design a set of prompts containing minor variations and examine LLMs' capabilities to generate answers, as well as prompt variations to examine their consistency with respect to content-level variations such as switching the order of response options or negating the statement. Our experiments on 17 different LLMs reveal that even simple perturbations significantly downgrade a model's question-answering ability, and that most LLMs have low negation consistency. Our results suggest that the currently widespread practice of prompting is insufficient to accurately and reliably capture model perceptions, and we therefore discuss potential alternatives to improve these issues.
Create account to get full access
Overview
- Researchers have used prompts to understand the properties and personas of large language models (LLMs) in social science research.
- This study examines whether the current format of prompting LLMs produces consistent and robust responses.
- The researchers created a dataset of 693 questions across 39 different persona measurement instruments and 115 persona axes.
- They also designed prompt variations to test LLMs' capabilities and consistency in generating responses.
- Experiments on 17 different LLMs revealed that even minor perturbations significantly impacted their question-answering ability, and most LLMs had low negation consistency.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate natural language. Researchers have been using these models to study various aspects of human behavior and personality, known as "persona." To do this, they often ask the models questions or present them with prompts to see how they respond.
In this study, the researchers wanted to see how reliable and consistent these prompts are. They created a large dataset of questions that cover different facets of persona, like traits, attitudes, and beliefs. They also designed variations of these prompts, like changing the order of response options or negating the statement.
When they tested these prompts on 17 different LLMs, they found that even small changes to the prompts could significantly affect the models' ability to answer the questions correctly. They also discovered that most LLMs struggled to maintain consistency when the prompts were negated or altered.
This suggests that the current way of prompting LLMs may not be enough to accurately capture their perceptions and personas. The researchers argue that we need to find better ways to interact with these models and understand their inner workings more reliably.
Technical Explanation
The researchers constructed a dataset of 693 questions covering 39 different instruments of persona measurement, spanning 115 persona axes. This dataset was designed to comprehensively capture various aspects of an individual's personality, attitudes, and beliefs.
Additionally, the researchers created a set of prompt variations to examine the LLMs' capabilities and consistency. These variations included changes such as switching the order of response options or negating the statement. The goal was to test whether the models would generate consistent responses despite these minor perturbations.
The experiments were conducted on 17 different LLMs, ranging from smaller, more specialized models to larger, more general-purpose ones. The researchers found that even simple changes to the prompts significantly degraded the models' question-answering performance. Furthermore, most LLMs exhibited low consistency when faced with negated prompts, suggesting that their understanding of negation is limited.
Critical Analysis
The researchers acknowledge that the current widespread practice of prompting LLMs may be insufficient to accurately and reliably capture the models' perceptions and personas. Their findings raise concerns about the validity and robustness of studies that rely on prompting LLMs to make inferences about human behavior and psychology.
While the study provides valuable insights, it is important to note that the experiments were conducted on a limited set of LLMs. The researchers suggest that further research is needed to explore the generalizability of these findings and to investigate potential solutions to improve the reliability of prompting approaches.
Additionally, the study does not delve into the underlying reasons for the LLMs' inconsistent responses to prompt variations. Exploring the architectural and training-related factors that contribute to this behavior could provide valuable insights for researchers and model developers.
Conclusion
This study highlights the need for more rigorous and reliable methods of interacting with LLMs in social science research. The findings suggest that the current prompting approach may not be sufficient to accurately capture the models' perceptions and personas. The researchers call for the exploration of alternative techniques that can more consistently and robustly elicit responses from LLMs, enabling researchers to make more reliable inferences about human behavior and psychology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Are Large Language Models Chameleons?
Mingmeng Geng, Sihong He, Roberto Trotta
0
0
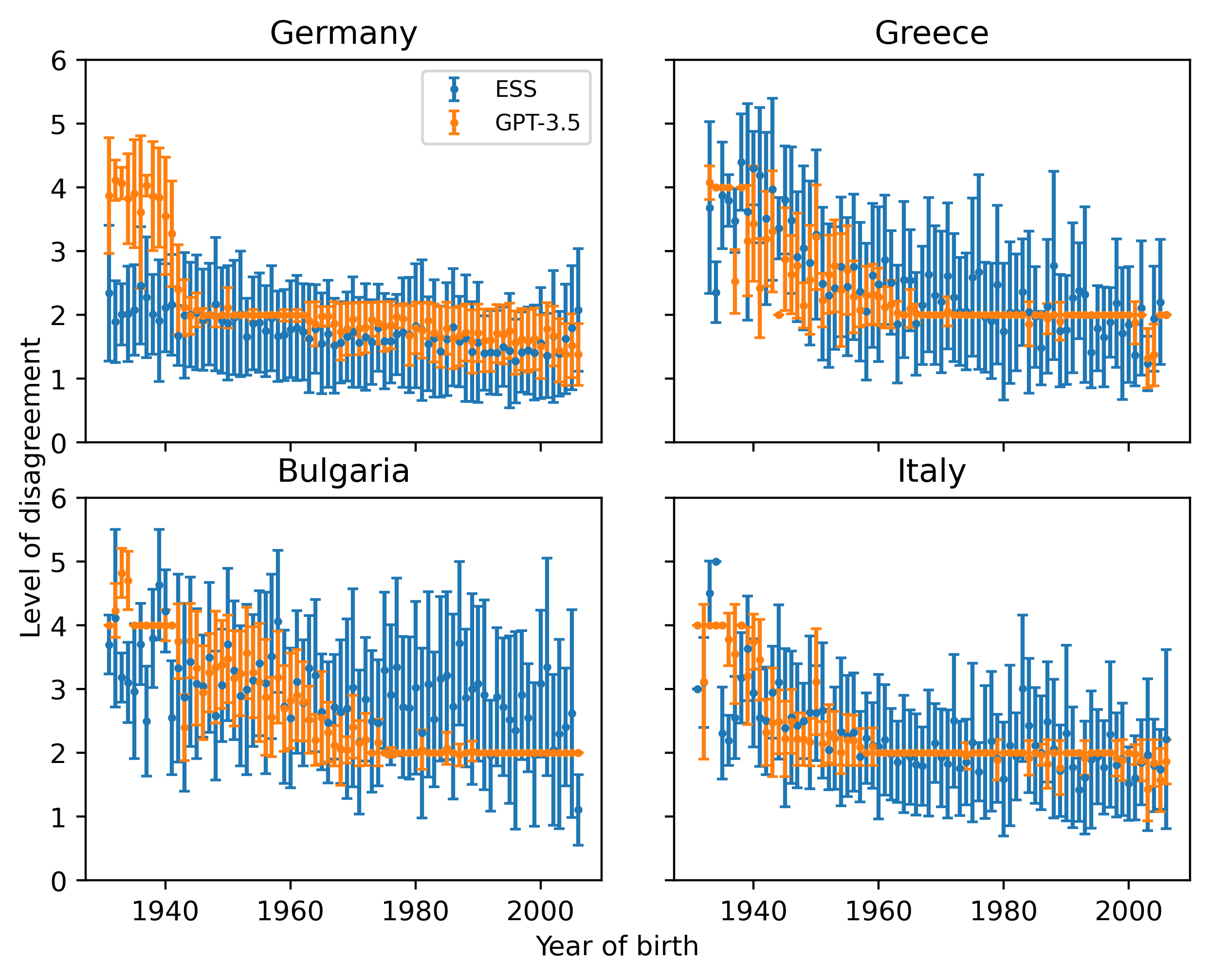
Do large language models (LLMs) have their own worldviews and personality tendencies? Simulations in which an LLM was asked to answer subjective questions were conducted more than 1 million times. Comparison of the responses from different LLMs with real data from the European Social Survey (ESS) suggests that the effect of prompts on bias and variability is fundamental, highlighting major cultural, age, and gender biases. Methods for measuring the difference between LLMs and survey data are discussed, such as calculating weighted means and a new proposed measure inspired by Jaccard similarity. We conclude that it is important to analyze the robustness and variability of prompts before using LLMs to model individual decisions or collective behavior, as their imitation abilities are approximate at best.
5/30/2024
🏷️
Limited Ability of LLMs to Simulate Human Psychological Behaviours: a Psychometric Analysis
Nikolay B Petrov, Gregory Serapio-Garc'ia, Jason Rentfrow
0
0
The humanlike responses of large language models (LLMs) have prompted social scientists to investigate whether LLMs can be used to simulate human participants in experiments, opinion polls and surveys. Of central interest in this line of research has been mapping out the psychological profiles of LLMs by prompting them to respond to standardized questionnaires. The conflicting findings of this research are unsurprising given that mapping out underlying, or latent, traits from LLMs' text responses to questionnaires is no easy task. To address this, we use psychometrics, the science of psychological measurement. In this study, we prompt OpenAI's flagship models, GPT-3.5 and GPT-4, to assume different personas and respond to a range of standardized measures of personality constructs. We used two kinds of persona descriptions: either generic (four or five random person descriptions) or specific (mostly demographics of actual humans from a large-scale human dataset). We found that the responses from GPT-4, but not GPT-3.5, using generic persona descriptions show promising, albeit not perfect, psychometric properties, similar to human norms, but the data from both LLMs when using specific demographic profiles, show poor psychometrics properties. We conclude that, currently, when LLMs are asked to simulate silicon personas, their responses are poor signals of potentially underlying latent traits. Thus, our work casts doubt on LLMs' ability to simulate individual-level human behaviour across multiple-choice question answering tasks.
5/14/2024
Explicit and Implicit Large Language Model Personas Generate Opinions but Fail to Replicate Deeper Perceptions and Biases
Salvatore Giorgi, Tingting Liu, Ankit Aich, Kelsey Isman, Garrick Sherman, Zachary Fried, Jo~ao Sedoc, Lyle H. Ungar, Brenda Curtis
0
0
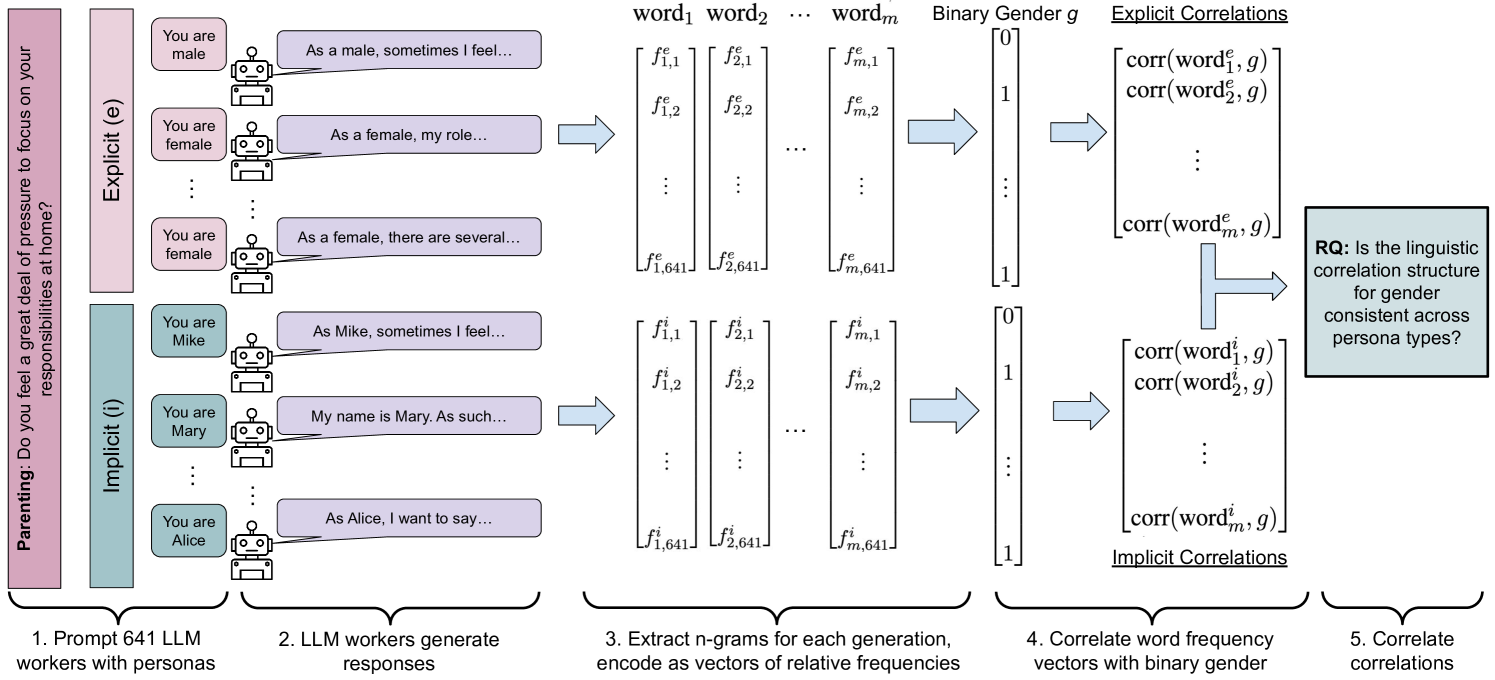
Large language models (LLMs) are increasingly being used in human-centered social scientific tasks, such as data annotation, synthetic data creation, and engaging in dialog. However, these tasks are highly subjective and dependent on human factors, such as one's environment, attitudes, beliefs, and lived experiences. Thus, employing LLMs (which do not have such human factors) in these tasks may result in a lack of variation in data, failing to reflect the diversity of human experiences. In this paper, we examine the role of prompting LLMs with human-like personas and asking the models to answer as if they were a specific human. This is done explicitly, with exact demographics, political beliefs, and lived experiences, or implicitly via names prevalent in specific populations. The LLM personas are then evaluated via (1) subjective annotation task (e.g., detecting toxicity) and (2) a belief generation task, where both tasks are known to vary across human factors. We examine the impact of explicit vs. implicit personas and investigate which human factors LLMs recognize and respond to. Results show that LLM personas show mixed results when reproducing known human biases, but generate generally fail to demonstrate implicit biases. We conclude that LLMs lack the intrinsic cognitive mechanisms of human thought, while capturing the statistical patterns of how people speak, which may restrict their effectiveness in complex social science applications.
6/21/2024
💬
Challenging the Validity of Personality Tests for Large Language Models
Tom Suhr, Florian E. Dorner, Samira Samadi, Augustin Kelava
0
0
With large language models (LLMs) like GPT-4 appearing to behave increasingly human-like in text-based interactions, it has become popular to attempt to evaluate personality traits of LLMs using questionnaires originally developed for humans. While reusing measures is a resource-efficient way to evaluate LLMs, careful adaptations are usually required to ensure that assessment results are valid even across human subpopulations. In this work, we provide evidence that LLMs' responses to personality tests systematically deviate from human responses, implying that the results of these tests cannot be interpreted in the same way. Concretely, reverse-coded items (I am introverted vs. I am extraverted) are often both answered affirmatively. Furthermore, variation across prompts designed to steer LLMs to simulate particular personality types does not follow the clear separation into five independent personality factors from human samples. In light of these results, we believe that it is important to investigate tests' validity for LLMs before drawing strong conclusions about potentially ill-defined concepts like LLMs' personality.
6/6/2024