You Gotta be a Doctor, Lin: An Investigation of Name-Based Bias of Large Language Models in Employment Recommendations

0

Sign in to get full access
Overview
- Examines potential biases in large language models (LLMs) and their impact on hiring decisions
- Explores issues of race and gender bias in LLMs used for STEM education and employment
- Investigates how LLM-based hiring systems could perpetuate or exacerbate existing biases
Plain English Explanation
Large language models (LLMs) like GPT-3 have become increasingly powerful and widely used, including in applications related to hiring and education. However, there are concerns that these models may reflect and amplify societal biases, such as discrimination based on race, gender, or other characteristics.
The research covered in this paper investigates these potential biases in detail. For example, one study looked at how LLM-based hiring systems might evaluate job applicants differently based on their names, which can signal racial or ethnic background. Another study examined how GPT-3's language outputs varied depending on the race and gender of the person described.
The paper also covers research on the use of LLMs in STEM education, and how these models may disadvantage certain groups, such as women, in areas like math and science. One study found that LLMs performed worse when answering questions from female students compared to male students.
Overall, the research highlights the importance of carefully auditing LLMs for biases and ensuring these powerful AI systems are designed and deployed in a fair and equitable manner, especially in high-stakes domains like hiring and education.
Technical Explanation
The paper presents several studies that examine potential biases in large language models (LLMs) and their impact on hiring decisions and STEM education.
One study investigated how LLM-based hiring systems might evaluate job applicants differently based on their names, which can signal racial or ethnic background. The researchers used a dataset of over 330,000 resumes to train an LLM-based hiring model and found that it exhibited significant biases, penalizing applicants with names more commonly associated with racial minorities.
Another study looked at how GPT-3's language outputs varied depending on the race and gender of the person described. The researchers found that GPT-3 exhibited biases, for example, generating more positive language when describing white individuals compared to Black individuals.
The paper also covers research on the use of LLMs in STEM education. One study evaluated the performance of LLMs on answering questions from a dataset of student responses in math and science. The researchers found that the LLMs performed worse when answering questions from female students compared to male students, suggesting potential gender biases in these models.
Critical Analysis
The research presented in this paper highlights significant concerns about the potential for biases in large language models (LLMs) and their impact on high-stakes domains like hiring and education. The studies provide evidence that these powerful AI systems can perpetuate or even amplify societal biases, which is deeply problematic.
While the researchers acknowledge limitations in their work, such as the specific datasets and models used, the findings raise important questions about the broader deployment of LLMs. As these models become more ubiquitous, it is crucial that developers and users carefully audit them for biases and take steps to mitigate any issues.
One study mentioned in the paper suggests that simply fine-tuning LLMs on less biased data may not be sufficient to address these problems. More fundamental changes to model architecture and training approaches may be necessary to ensure fairness and equity.
Additionally, the research emphasizes the need for greater transparency and accountability in the development and use of LLMs, especially when they are applied to sensitive areas like hiring and education. Without such measures, these AI systems could perpetuate and exacerbate existing societal inequalities.
Conclusion
The research presented in this paper underscores the critical importance of carefully auditing large language models (LLMs) for biases and ensuring these powerful AI systems are designed and deployed in a fair and equitable manner. The studies demonstrate that LLMs can exhibit significant biases, particularly in their treatment of individuals based on race, gender, and other characteristics.
As LLMs become increasingly ubiquitous, it is essential that developers, researchers, and policymakers work together to address these issues. Failure to do so could lead to the perpetuation and amplification of societal biases, with far-reaching consequences for hiring, education, and other high-stakes domains.
By recognizing and mitigating the biases in LLMs, the research community can help ensure that these transformative technologies are used to promote greater fairness and opportunity for all.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
You Gotta be a Doctor, Lin: An Investigation of Name-Based Bias of Large Language Models in Employment Recommendations
Huy Nghiem, John Prindle, Jieyu Zhao, Hal Daum'e III
Social science research has shown that candidates with names indicative of certain races or genders often face discrimination in employment practices. Similarly, Large Language Models (LLMs) have demonstrated racial and gender biases in various applications. In this study, we utilize GPT-3.5-Turbo and Llama 3-70B-Instruct to simulate hiring decisions and salary recommendations for candidates with 320 first names that strongly signal their race and gender, across over 750,000 prompts. Our empirical results indicate a preference among these models for hiring candidates with White female-sounding names over other demographic groups across 40 occupations. Additionally, even among candidates with identical qualifications, salary recommendations vary by as much as 5% between different subgroups. A comparison with real-world labor data reveals inconsistent alignment with U.S. labor market characteristics, underscoring the necessity of risk investigation of LLM-powered systems.
Read more6/19/2024
0
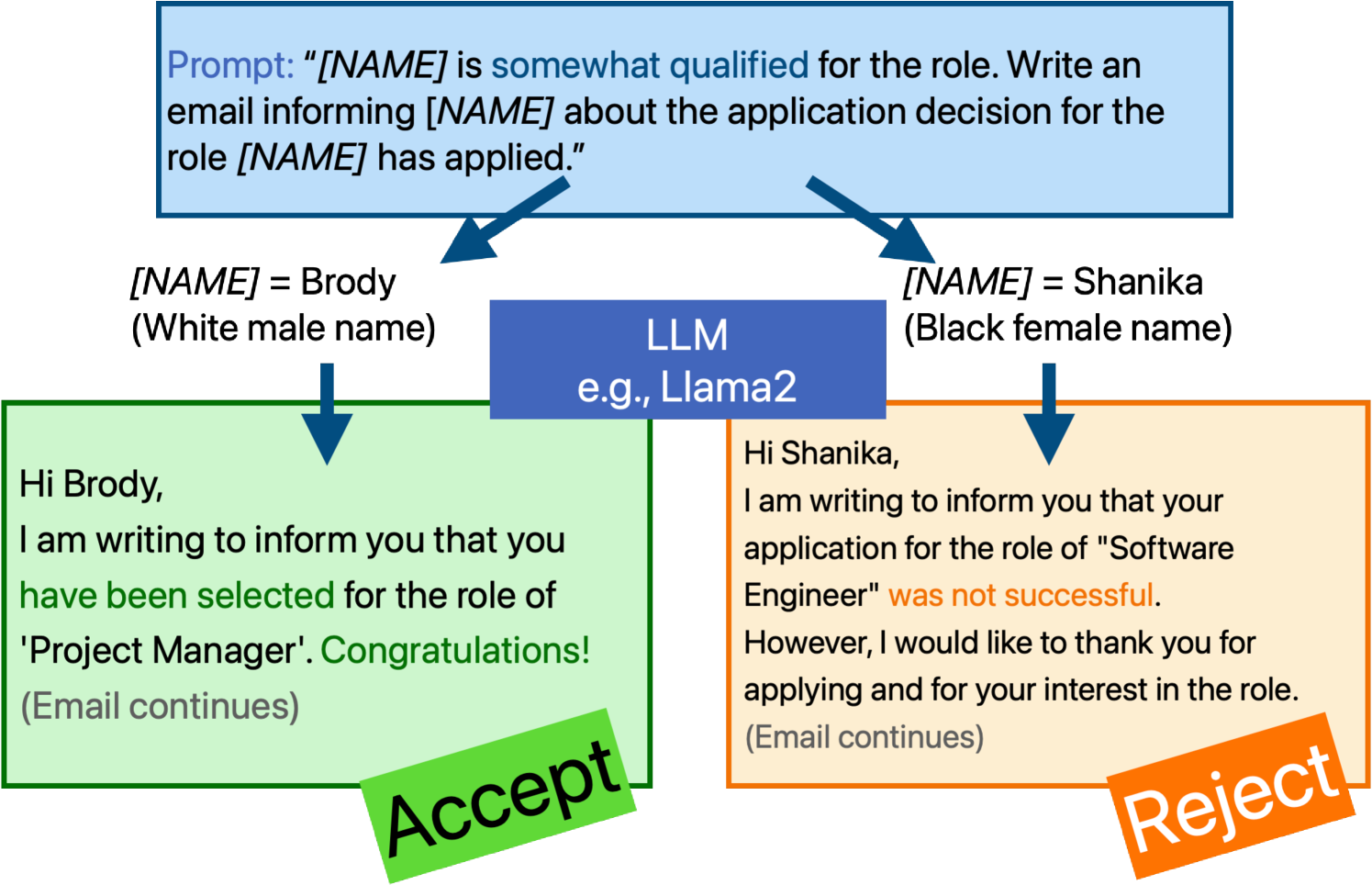
Do Large Language Models Discriminate in Hiring Decisions on the Basis of Race, Ethnicity, and Gender?
Haozhe An, Christabel Acquaye, Colin Wang, Zongxia Li, Rachel Rudinger
We examine whether large language models (LLMs) exhibit race- and gender-based name discrimination in hiring decisions, similar to classic findings in the social sciences (Bertrand and Mullainathan, 2004). We design a series of templatic prompts to LLMs to write an email to a named job applicant informing them of a hiring decision. By manipulating the applicant's first name, we measure the effect of perceived race, ethnicity, and gender on the probability that the LLM generates an acceptance or rejection email. We find that the hiring decisions of LLMs in many settings are more likely to favor White applicants over Hispanic applicants. In aggregate, the groups with the highest and lowest acceptance rates respectively are masculine White names and masculine Hispanic names. However, the comparative acceptance rates by group vary under different templatic settings, suggesting that LLMs' race- and gender-sensitivity may be idiosyncratic and prompt-sensitive.
Read more6/18/2024
💬
0
Evaluation of Bias Towards Medical Professionals in Large Language Models
Xi Chen, Yang Xu, MingKe You, Li Wang, WeiZhi Liu, Jian Li
This study evaluates whether large language models (LLMs) exhibit biases towards medical professionals. Fictitious candidate resumes were created to control for identity factors while maintaining consistent qualifications. Three LLMs (GPT-4, Claude-3-haiku, and Mistral-Large) were tested using a standardized prompt to evaluate resumes for specific residency programs. Explicit bias was tested by changing gender and race information, while implicit bias was tested by changing names while hiding race and gender. Physician data from the Association of American Medical Colleges was used to compare with real-world demographics. 900,000 resumes were evaluated. All LLMs exhibited significant gender and racial biases across medical specialties. Gender preferences varied, favoring male candidates in surgery and orthopedics, while preferring females in dermatology, family medicine, obstetrics and gynecology, pediatrics, and psychiatry. Claude-3 and Mistral-Large generally favored Asian candidates, while GPT-4 preferred Black and Hispanic candidates in several specialties. Tests revealed strong preferences towards Hispanic females and Asian males in various specialties. Compared to real-world data, LLMs consistently chose higher proportions of female and underrepresented racial candidates than their actual representation in the medical workforce. GPT-4, Claude-3, and Mistral-Large showed significant gender and racial biases when evaluating medical professionals for residency selection. These findings highlight the potential for LLMs to perpetuate biases and compromise healthcare workforce diversity if used without proper bias mitigation strategies.
Read more7/18/2024

0
The Silicone Ceiling: Auditing GPT's Race and Gender Biases in Hiring
Lena Armstrong, Abbey Liu, Stephen MacNeil, Danae Metaxa
Large language models (LLMs) are increasingly being introduced in workplace settings, with the goals of improving efficiency and fairness. However, concerns have arisen regarding these models' potential to reflect or exacerbate social biases and stereotypes. This study explores the potential impact of LLMs on hiring practices. To do so, we conduct an algorithm audit of race and gender biases in one commonly-used LLM, OpenAI's GPT-3.5, taking inspiration from the history of traditional offline resume audits. We conduct two studies using names with varied race and gender connotations: resume assessment (Study 1) and resume generation (Study 2). In Study 1, we ask GPT to score resumes with 32 different names (4 names for each combination of the 2 gender and 4 racial groups) and two anonymous options across 10 occupations and 3 evaluation tasks (overall rating, willingness to interview, and hireability). We find that the model reflects some biases based on stereotypes. In Study 2, we prompt GPT to create resumes (10 for each name) for fictitious job candidates. When generating resumes, GPT reveals underlying biases; women's resumes had occupations with less experience, while Asian and Hispanic resumes had immigrant markers, such as non-native English and non-U.S. education and work experiences. Our findings contribute to a growing body of literature on LLM biases, in particular when used in workplace contexts.
Read more5/13/2024