You Only Learn One Query: Learning Unified Human Query for Single-Stage Multi-Person Multi-Task Human-Centric Perception

0

Sign in to get full access
Overview
- This paper presents a novel approach for single-stage multi-person multi-task human-centric perception, called UniHead.
- The key idea is to learn a unified human query that can be used to perform various human-centric perception tasks in a single stage.
- The authors demonstrate the effectiveness of UniHead on several human-centric perception tasks, including CAPHuman, Unified Framework for Human-Centric Point Cloud Video, and UniParser.
Plain English Explanation
The paper presents a new way to tackle different tasks related to understanding humans in images and videos, such as detecting and tracking people, estimating their poses, and segmenting their body parts. Instead of using separate models for each task, the researchers developed a single model that can perform all these tasks at once.
The key innovation is the "unified human query" - a representation that the model learns to use to identify and understand people in the scene. This unified query allows the model to efficiently extract all the relevant information about each person in a single pass, without the need for multiple specialized models.
By using this unified approach, the model can perform tasks like people detection, pose estimation, and body part segmentation simultaneously, rather than requiring separate models for each task. This makes the system more efficient and easier to deploy in real-world applications.
The researchers demonstrate the effectiveness of their UniHead approach on several existing human-centric perception datasets and tasks, showing that it can match or outperform specialized models while being more computationally efficient.
Technical Explanation
The key technical contribution of this paper is the UniHead architecture, which learns a unified human query that can be used to perform various human-centric perception tasks in a single stage.
The UniHead model takes an input image or video frame and produces a set of outputs, each corresponding to a different human-centric perception task. This includes detecting the bounding boxes of people in the scene, estimating their 3D poses, and segmenting their body parts.
The core of the UniHead architecture is a shared backbone network that extracts visual features from the input. On top of this backbone, the model has a series of "heads" - specialized output modules - that use the shared features to produce the task-specific outputs.
The key innovation is that all these heads share a common "human query" - a learned representation that encodes the essential information needed to identify and understand people in the scene. This unified query is passed to each of the task-specific heads, allowing them to efficiently extract the relevant information for their respective tasks.
By learning this shared human query, the UniHead model can perform all the human-centric perception tasks in a single stage, without the need for separate models or complex multi-stage pipelines. This makes the system more efficient and easier to deploy in real-world applications.
The authors evaluate UniHead on several benchmark datasets, including CAPHuman, Unified Framework for Human-Centric Point Cloud Video, and UniParser. They show that UniHead can match or outperform specialized models on these tasks, while being more computationally efficient.
Critical Analysis
The UniHead approach presented in this paper is a promising step towards more efficient and unified human-centric perception systems. By learning a shared human query representation, the model can perform multiple tasks simultaneously, reducing the complexity and computational requirements compared to traditional multi-stage pipelines.
However, the paper does not address several potential limitations and areas for further research. For example, it is not clear how UniHead would scale to large and crowded scenes with many people, or how it would handle occlusions and complex interactions between individuals.
Additionally, the paper focuses on standard benchmark datasets, but it would be interesting to see how UniHead performs on more diverse and challenging real-world scenarios, such as in-the-wild videos or images with complex backgrounds and lighting conditions.
Further research could also explore ways to make the UniHead architecture more flexible and adaptable, allowing it to be easily fine-tuned or extended to new human-centric perception tasks without requiring a complete retraining of the model.
Overall, the UniHead approach represents an important step forward in the field of human-centric perception, and the authors have made a valuable contribution by demonstrating the potential of learning a unified human query for efficient multi-task inference. However, there are still opportunities for further refinement and exploration to address the limitations and expand the capabilities of this approach.
Conclusion
This paper presents UniHead, a novel approach for single-stage multi-person multi-task human-centric perception. The key idea is to learn a unified human query that can be used to perform various human-centric perception tasks in a single stage, making the system more efficient and easier to deploy.
The authors demonstrate the effectiveness of UniHead on several benchmark datasets, showing that it can match or outperform specialized models while being more computationally efficient. This work represents an important step forward in the field of human-centric perception, and the unified query approach has the potential to enable more robust and versatile human understanding systems for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
You Only Learn One Query: Learning Unified Human Query for Single-Stage Multi-Person Multi-Task Human-Centric Perception
Sheng Jin, Shuhuai Li, Tong Li, Wentao Liu, Chen Qian, Ping Luo
Human-centric perception (e.g. detection, segmentation, pose estimation, and attribute analysis) is a long-standing problem for computer vision. This paper introduces a unified and versatile framework (HQNet) for single-stage multi-person multi-task human-centric perception (HCP). Our approach centers on learning a unified human query representation, denoted as Human Query, which captures intricate instance-level features for individual persons and disentangles complex multi-person scenarios. Although different HCP tasks have been well-studied individually, single-stage multi-task learning of HCP tasks has not been fully exploited in the literature due to the absence of a comprehensive benchmark dataset. To address this gap, we propose COCO-UniHuman benchmark to enable model development and comprehensive evaluation. Experimental results demonstrate the proposed method's state-of-the-art performance among multi-task HCP models and its competitive performance compared to task-specific HCP models. Moreover, our experiments underscore Human Query's adaptability to new HCP tasks, thus demonstrating its robust generalization capability. Codes and data are available at https://github.com/lishuhuai527/COCO-UniHuman.
Read more7/16/2024

0
UniHead: Unifying Multi-Perception for Detection Heads
Hantao Zhou, Rui Yang, Yachao Zhang, Haoran Duan, Yawen Huang, Runze Hu, Xiu Li, Yefeng Zheng
The detection head constitutes a pivotal component within object detectors, tasked with executing both classification and localization functions. Regrettably, the commonly used parallel head often lacks omni perceptual capabilities, such as deformation perception, global perception and cross-task perception. Despite numerous methods attempting to enhance these abilities from a single aspect, achieving a comprehensive and unified solution remains a significant challenge. In response to this challenge, we develop an innovative detection head, termed UniHead, to unify three perceptual abilities simultaneously. More precisely, our approach (1) introduces deformation perception, enabling the model to adaptively sample object features; (2) proposes a Dual-axial Aggregation Transformer (DAT) to adeptly model long-range dependencies, thereby achieving global perception; and (3) devises a Cross-task Interaction Transformer (CIT) that facilitates interaction between the classification and localization branches, thus aligning the two tasks. As a plug-and-play method, the proposed UniHead can be conveniently integrated with existing detectors. Extensive experiments on the COCO dataset demonstrate that our UniHead can bring significant improvements to many detectors. For instance, the UniHead can obtain +2.7 AP gains in RetinaNet, +2.9 AP gains in FreeAnchor, and +2.1 AP gains in GFL. The code is available at https://github.com/zht8506/UniHead.
Read more6/11/2024
🧠
0
CapHuman: Capture Your Moments in Parallel Universes
Chao Liang, Fan Ma, Linchao Zhu, Yingying Deng, Yi Yang
We concentrate on a novel human-centric image synthesis task, that is, given only one reference facial photograph, it is expected to generate specific individual images with diverse head positions, poses, facial expressions, and illuminations in different contexts. To accomplish this goal, we argue that our generative model should be capable of the following favorable characteristics: (1) a strong visual and semantic understanding of our world and human society for basic object and human image generation. (2) generalizable identity preservation ability. (3) flexible and fine-grained head control. Recently, large pre-trained text-to-image diffusion models have shown remarkable results, serving as a powerful generative foundation. As a basis, we aim to unleash the above two capabilities of the pre-trained model. In this work, we present a new framework named CapHuman. We embrace the encode then learn to align paradigm, which enables generalizable identity preservation for new individuals without cumbersome tuning at inference. CapHuman encodes identity features and then learns to align them into the latent space. Moreover, we introduce the 3D facial prior to equip our model with control over the human head in a flexible and 3D-consistent manner. Extensive qualitative and quantitative analyses demonstrate our CapHuman can produce well-identity-preserved, photo-realistic, and high-fidelity portraits with content-rich representations and various head renditions, superior to established baselines. Code and checkpoint will be released at https://github.com/VamosC/CapHuman.
Read more5/20/2024
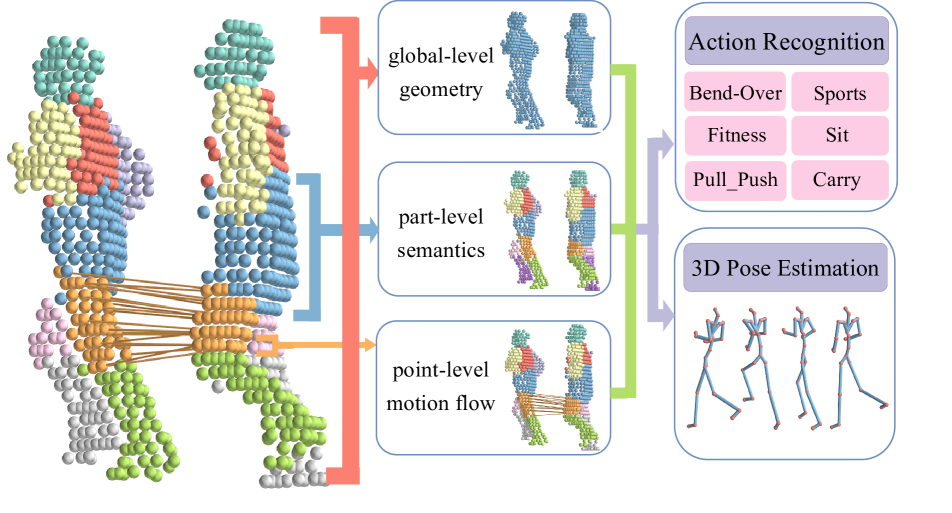
0
A Unified Framework for Human-centric Point Cloud Video Understanding
Yiteng Xu, Kecheng Ye, Xiao Han, Yiming Ren, Xinge Zhu, Yuexin Ma
Human-centric Point Cloud Video Understanding (PVU) is an emerging field focused on extracting and interpreting human-related features from sequences of human point clouds, further advancing downstream human-centric tasks and applications. Previous works usually focus on tackling one specific task and rely on huge labeled data, which has poor generalization capability. Considering that human has specific characteristics, including the structural semantics of human body and the dynamics of human motions, we propose a unified framework to make full use of the prior knowledge and explore the inherent features in the data itself for generalized human-centric point cloud video understanding. Extensive experiments demonstrate that our method achieves state-of-the-art performance on various human-related tasks, including action recognition and 3D pose estimation. All datasets and code will be released soon.
Read more4/1/2024