You Only Train Once: A Unified Framework for Both Full-Reference and No-Reference Image Quality Assessment

0
🖼️
Sign in to get full access
Overview
- Proposes a unified framework for both full reference (FR) and no reference (NR) image quality assessment (IQA) tasks
- Employs an encoder to extract multi-level features and a Hierarchical Attention (HA) module to model spatial distortions at each stage
- Introduces a Semantic Distortion Aware (SDA) module to examine feature correlations between shallow and deep layers of the encoder
- Outperforms existing models on both FR and NR IQA tasks when trained independently, and further enhances performance when trained jointly
Plain English Explanation
Evaluating the quality of images is an important task, known as image quality assessment (IQA). Humans can seamlessly transition between two types of IQA: full reference (FR), where a high-quality reference image is available, and no reference (NR), where no reference is provided. However, existing IQA models are constrained to either FR or NR tasks, requiring two distinct systems.
To address this, the proposed approach aims to unify FR and NR IQA under a single framework. It first uses an encoder to extract multi-level features from input images. Then, a Hierarchical Attention (HA) module is used as a universal adapter for both FR and NR inputs to model spatial distortions at each encoder stage. Additionally, a Semantic Distortion Aware (SDA) module is introduced to examine feature correlations between shallow and deep layers of the encoder, as different distortions can affect image semantics differently.
By adopting HA and SDA, the proposed network can effectively perform both FR and NR IQA. When trained independently on NR or FR IQA tasks, it outperforms existing models and achieves state-of-the-art performance. Moreover, when trained jointly on NR and FR IQA tasks, it further enhances the performance of NR IQA while achieving on-par performance with the state-of-the-art in FR IQA. This means that the model can be trained once to perform both IQA tasks, greatly improving its versatility.
Technical Explanation
The proposed approach first employs an encoder to extract multi-level features from input images. This allows the model to capture information at different levels of abstraction, which is crucial for understanding complex image distortions.
Next, the Hierarchical Attention (HA) module is introduced as a universal adapter for both FR and NR inputs. The HA module models the spatial distortions at each encoder stage, enabling the model to effectively handle both types of IQA tasks.
Furthermore, the Semantic Distortion Aware (SDA) module is proposed to examine the feature correlations between shallow and deep layers of the encoder. This is important because different distortions can contaminate encoder stages and damage image semantic meaning in different ways. The SDA module helps the model understand these complex relationships, which is crucial for accurately assessing image quality.
By combining the HA and SDA modules, the proposed network can effectively perform both FR and NR IQA tasks. When trained independently on either NR or FR IQA tasks, the model outperforms existing state-of-the-art approaches. Moreover, when trained jointly on both NR and FR IQA tasks, the model further enhances its performance on NR IQA while maintaining state-of-the-art results on FR IQA. This demonstrates the versatility and effectiveness of the proposed unified framework.
Critical Analysis
The paper presents a promising approach to unifying FR and NR IQA tasks, which addresses an important limitation of existing models. The use of the HA and SDA modules is well-justified and the experimental results demonstrate the effectiveness of the proposed approach.
However, the paper does not discuss the potential computational complexity or inference time of the unified model, which could be a concern for real-world applications. Additionally, the paper does not explore the model's robustness to different types of image distortions or its performance on diverse datasets.
Further research could investigate the scalability of the unified framework, its generalization to a wider range of IQA tasks, and its practical implications for various image-related applications. Exploring the interpretability of the HA and SDA modules could also provide valuable insights into the model's decision-making process and help identify areas for improvement.
Conclusion
The proposed unified framework for FR and NR IQA tasks represents a significant advancement in the field. By employing an encoder, a Hierarchical Attention module, and a Semantic Distortion Aware module, the model can effectively handle both types of IQA tasks, outperforming existing state-of-the-art approaches.
The ability to train a single model for both FR and NR IQA tasks greatly improves the model's versatility and practical applicability. This research paves the way for more robust and efficient image quality assessment systems, with potential impact on a wide range of image-related applications, such as image compression, restoration, and enhancement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
You Only Train Once: A Unified Framework for Both Full-Reference and No-Reference Image Quality Assessment
Yi Ke Yun, Weisi Lin
Although recent efforts in image quality assessment (IQA) have achieved promising performance, there still exists a considerable gap compared to the human visual system (HVS). One significant disparity lies in humans' seamless transition between full reference (FR) and no reference (NR) tasks, whereas existing models are constrained to either FR or NR tasks. This disparity implies the necessity of designing two distinct systems, thereby greatly diminishing the model's versatility. Therefore, our focus lies in unifying FR and NR IQA under a single framework. Specifically, we first employ an encoder to extract multi-level features from input images. Then a Hierarchical Attention (HA) module is proposed as a universal adapter for both FR and NR inputs to model the spatial distortion at each encoder stage. Furthermore, considering that different distortions contaminate encoder stages and damage image semantic meaning differently, a Semantic Distortion Aware (SDA) module is proposed to examine feature correlations between shallow and deep layers of the encoder. By adopting HA and SDA, the proposed network can effectively perform both FR and NR IQA. When our proposed model is independently trained on NR or FR IQA tasks, it outperforms existing models and achieves state-of-the-art performance. Moreover, when trained jointly on NR and FR IQA tasks, it further enhances the performance of NR IQA while achieving on-par performance in the state-of-the-art FR IQA. You only train once to perform both IQA tasks. Code will be released at: https://github.com/BarCodeReader/YOTO.
Read more4/9/2024
0
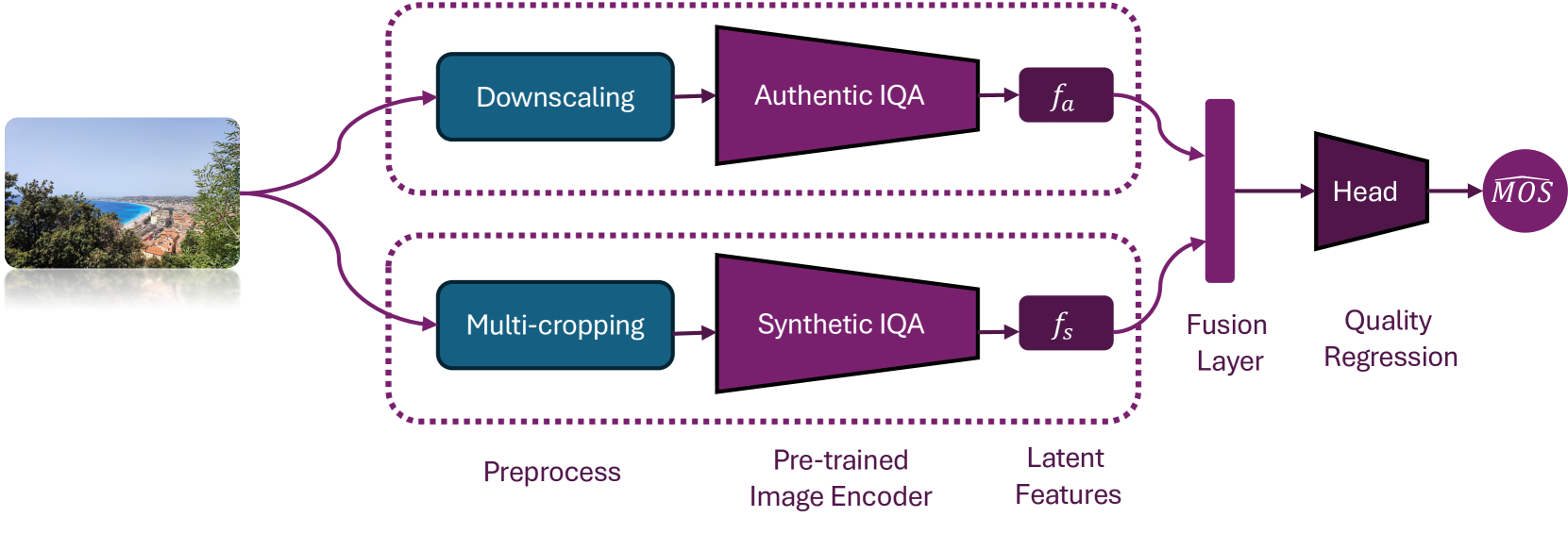
LAR-IQA: A Lightweight, Accurate, and Robust No-Reference Image Quality Assessment Model
Nasim Jamshidi Avanaki, Abhijay Ghildyal, Nabajeet Barman, Saman Zadtootaghaj
Recent advancements in the field of No-Reference Image Quality Assessment (NR-IQA) using deep learning techniques demonstrate high performance across multiple open-source datasets. However, such models are typically very large and complex making them not so suitable for real-world deployment, especially on resource- and battery-constrained mobile devices. To address this limitation, we propose a compact, lightweight NR-IQA model that achieves state-of-the-art (SOTA) performance on ECCV AIM UHD-IQA challenge validation and test datasets while being also nearly 5.7 times faster than the fastest SOTA model. Our model features a dual-branch architecture, with each branch separately trained on synthetically and authentically distorted images which enhances the model's generalizability across different distortion types. To improve robustness under diverse real-world visual conditions, we additionally incorporate multiple color spaces during the training process. We also demonstrate the higher accuracy of recently proposed Kolmogorov-Arnold Networks (KANs) for final quality regression as compared to the conventional Multi-Layer Perceptrons (MLPs). Our evaluation considering various open-source datasets highlights the practical, high-accuracy, and robust performance of our proposed lightweight model. Code: https://github.com/nasimjamshidi/LAR-IQA.
Read more9/9/2024
🤷
0
Cross-IQA: Unsupervised Learning for Image Quality Assessment
Zhen Zhang
Automatic perception of image quality is a challenging problem that impacts billions of Internet and social media users daily. To advance research in this field, we propose a no-reference image quality assessment (NR-IQA) method termed Cross-IQA based on vision transformer(ViT) model. The proposed Cross-IQA method can learn image quality features from unlabeled image data. We construct the pretext task of synthesized image reconstruction to unsupervised extract the image quality information based ViT block. The pretrained encoder of Cross-IQA is used to fine-tune a linear regression model for score prediction. Experimental results show that Cross-IQA can achieve state-of-the-art performance in assessing the low-frequency degradation information (e.g., color change, blurring, etc.) of images compared with the classical full-reference IQA and NR-IQA under the same datasets.
Read more5/8/2024

0
Adaptive Feature Selection for No-Reference Image Quality Assessment by Mitigating Semantic Noise Sensitivity
Xudong Li, Timin Gao, Runze Hu, Yan Zhang, Shengchuan Zhang, Xiawu Zheng, Jingyuan Zheng, Yunhang Shen, Ke Li, Yutao Liu, Pingyang Dai, Rongrong Ji
The current state-of-the-art No-Reference Image Quality Assessment (NR-IQA) methods typically rely on feature extraction from upstream semantic backbone networks, assuming that all extracted features are relevant. However, we make a key observation that not all features are beneficial, and some may even be harmful, necessitating careful selection. Empirically, we find that many image pairs with small feature spatial distances can have vastly different quality scores, indicating that the extracted features may contain a significant amount of quality-irrelevant noise. To address this issue, we propose a Quality-Aware Feature Matching IQA Metric (QFM-IQM) that employs an adversarial perspective to remove harmful semantic noise features from the upstream task. Specifically, QFM-IQM enhances the semantic noise distinguish capabilities by matching image pairs with similar quality scores but varying semantic features as adversarial semantic noise and adaptively adjusting the upstream task's features by reducing sensitivity to adversarial noise perturbation. Furthermore, we utilize a distillation framework to expand the dataset and improve the model's generalization ability. Our approach achieves superior performance to the state-of-the-art NR-IQA methods on eight standard IQA datasets.
Read more5/28/2024