Zero, Finite, and Infinite Belief History of Theory of Mind Reasoning in Large Language Models

0

Sign in to get full access
Overview
- This paper investigates the ability of large language models (LLMs) to reason about the beliefs of themselves and others, a key aspect of human-level theory of mind.
- The researchers tested LLMs on a variety of tasks that assess different levels of theory of mind reasoning, from simple false belief tests to more complex scenarios involving recursive beliefs.
- They found that LLMs can demonstrate adult-level performance on many theory of mind tasks, suggesting these models have developed sophisticated reasoning capabilities.
- However, the models also exhibited some limitations, such as difficulty with certain types of recursive reasoning and potential biases in their belief representations.
Plain English Explanation
The paper explores how well large language models (LLMs) - the powerful AI systems that can understand and generate human-like text - can reason about the beliefs and mental states of themselves and others. This ability, known as "theory of mind," is a key part of human-level intelligence and social interaction.
The researchers put LLMs through a variety of tests to assess their theory of mind capabilities. These ranged from simple "false belief" tasks, where the model has to understand that someone else might have a belief that differs from reality, to more complex scenarios involving multiple nested beliefs (e.g., "I think they believe that I know they are lying").
Surprisingly, the LLMs were able to perform at an adult human level on many of these tasks, suggesting they have developed quite sophisticated reasoning skills. This is an important finding, as it shows these AI systems are not just good at processing language, but can also engage in the type of subtle, context-dependent thinking that is central to human social intelligence.
However, the models were not perfect. They struggled with certain types of recursive reasoning, and the researchers also found hints that the LLMs might have some biases or limitations in how they represent and reason about beliefs. More research is needed to fully understand the strengths and weaknesses of LLMs when it comes to theory of mind.
Overall, this work provides valuable insights into the current state of AI reasoning capabilities and opens up important questions about the development of human-like intelligence in machines. As AI models advance, understanding their theory of mind abilities will be crucial for ensuring they can interact with humans in safe and beneficial ways.
Technical Explanation
The paper investigates the ability of large language models (LLMs) to reason about the beliefs of themselves and others, a key aspect of human-level theory of mind reasoning.
The researchers evaluated LLMs on a suite of tasks from the OpenToM benchmark, which assesses theory of mind abilities at different levels of complexity. This includes simple false belief tests, as well as more advanced scenarios involving recursive beliefs (e.g., "I think they believe that I know they are lying").
Surprisingly, the LLMs were able to demonstrate adult-level performance on many of these theory of mind tasks, suggesting they have developed sophisticated reasoning capabilities that go beyond just language processing. The researchers also tested the models on the NegotiationToM benchmark, which involves more naturalistic, interactive theory of mind scenarios, and found similar results.
However, the LLMs did exhibit some limitations. They struggled with certain types of recursive reasoning, and the researchers also found indications that the models might have biases or inconsistencies in how they represent and reason about beliefs.
Critical Analysis
The paper provides valuable insights into the current state of theory of mind reasoning in LLMs, but also highlights important caveats and areas for further research.
One key limitation is that the tasks used to evaluate the models, while widely used in theory of mind research, may not fully capture the nuance and complexity of real-world social cognition. The researchers acknowledge that more naturalistic, interactive test scenarios are needed to fully understand the models' capabilities.
Additionally, the study does not explore how the LLMs' theory of mind reasoning is affected by factors like the specific training data, model architecture, or fine-tuning process used. Further research is needed to understand the underlying mechanisms and potential biases in how these models represent and reason about beliefs.
It is also important to consider the potential risks and ethical implications as AI systems with theory of mind abilities become more advanced. Careful consideration must be given to ensuring these capabilities are developed and deployed in ways that are safe and beneficial for humans.
Conclusion
This paper makes an important contribution to our understanding of the theory of mind reasoning capabilities of large language models. The finding that LLMs can demonstrate adult-level performance on many theory of mind tasks is a significant milestone in the development of human-like AI reasoning.
However, the research also highlights the need for continued exploration of the strengths, limitations, and potential biases of these models when it comes to reasoning about beliefs and mental states. As AI technology advances, understanding and responsibly shaping the theory of mind abilities of these systems will be crucial for ensuring they can interact with humans in safe and beneficial ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Zero, Finite, and Infinite Belief History of Theory of Mind Reasoning in Large Language Models
Weizhi Tang, Vaishak Belle
Large Language Models (LLMs) have recently shown a promise and emergence of Theory of Mind (ToM) ability and even outperform humans in certain ToM tasks. To evaluate and extend the boundaries of the ToM reasoning ability of LLMs, we propose a novel concept, taxonomy, and framework, the ToM reasoning with Zero, Finite, and Infinite Belief History and develop a multi-round text-based game, called $textit{Pick the Right Stuff}$, as a benchmark. We have evaluated six LLMs with this game and found their performance on Zero Belief History is consistently better than on Finite Belief History. In addition, we have found two of the models with small parameter sizes outperform all the evaluated models with large parameter sizes. We expect this work to pave the way for future ToM benchmark development and also for the promotion and development of more complex AI agents or systems which are required to be equipped with more complex ToM reasoning ability.
Read more6/10/2024

0
Language Models Represent Beliefs of Self and Others
Wentao Zhu, Zhining Zhang, Yizhou Wang
Understanding and attributing mental states, known as Theory of Mind (ToM), emerges as a fundamental capability for human social reasoning. While Large Language Models (LLMs) appear to possess certain ToM abilities, the mechanisms underlying these capabilities remain elusive. In this study, we discover that it is possible to linearly decode the belief status from the perspectives of various agents through neural activations of language models, indicating the existence of internal representations of self and others' beliefs. By manipulating these representations, we observe dramatic changes in the models' ToM performance, underscoring their pivotal role in the social reasoning process. Additionally, our findings extend to diverse social reasoning tasks that involve different causal inference patterns, suggesting the potential generalizability of these representations.
Read more5/31/2024

0
LLMs achieve adult human performance on higher-order theory of mind tasks
Winnie Street, John Oliver Siy, Geoff Keeling, Adrien Baranes, Benjamin Barnett, Michael McKibben, Tatenda Kanyere, Alison Lentz, Blaise Aguera y Arcas, Robin I. M. Dunbar
This paper examines the extent to which large language models (LLMs) have developed higher-order theory of mind (ToM); the human ability to reason about multiple mental and emotional states in a recursive manner (e.g. I think that you believe that she knows). This paper builds on prior work by introducing a handwritten test suite -- Multi-Order Theory of Mind Q&A -- and using it to compare the performance of five LLMs to a newly gathered adult human benchmark. We find that GPT-4 and Flan-PaLM reach adult-level and near adult-level performance on ToM tasks overall, and that GPT-4 exceeds adult performance on 6th order inferences. Our results suggest that there is an interplay between model size and finetuning for the realisation of ToM abilities, and that the best-performing LLMs have developed a generalised capacity for ToM. Given the role that higher-order ToM plays in a wide range of cooperative and competitive human behaviours, these findings have significant implications for user-facing LLM applications.
Read more6/3/2024
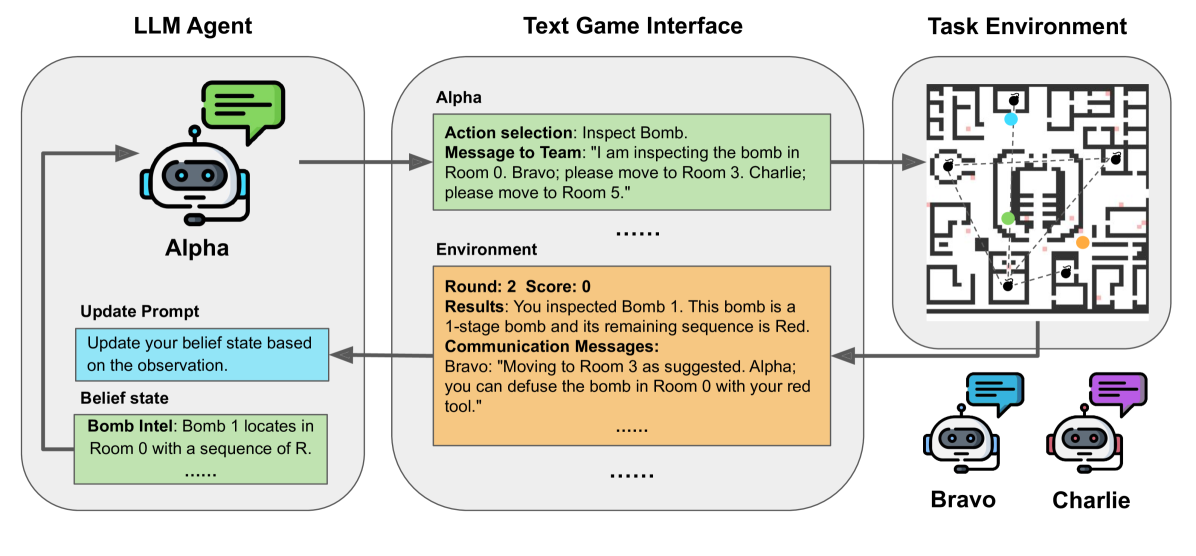
0
Theory of Mind for Multi-Agent Collaboration via Large Language Models
Huao Li, Yu Quan Chong, Simon Stepputtis, Joseph Campbell, Dana Hughes, Michael Lewis, Katia Sycara
While Large Language Models (LLMs) have demonstrated impressive accomplishments in both reasoning and planning, their abilities in multi-agent collaborations remains largely unexplored. This study evaluates LLM-based agents in a multi-agent cooperative text game with Theory of Mind (ToM) inference tasks, comparing their performance with Multi-Agent Reinforcement Learning (MARL) and planning-based baselines. We observed evidence of emergent collaborative behaviors and high-order Theory of Mind capabilities among LLM-based agents. Our results reveal limitations in LLM-based agents' planning optimization due to systematic failures in managing long-horizon contexts and hallucination about the task state. We explore the use of explicit belief state representations to mitigate these issues, finding that it enhances task performance and the accuracy of ToM inferences for LLM-based agents.
Read more6/28/2024