Zero-shot generalization across architectures for visual classification
2402.14095
0
0

Abstract
Generalization to unseen data is a key desideratum for deep networks, but its relation to classification accuracy is unclear. Using a minimalist vision dataset and a measure of generalizability, we show that popular networks, from deep convolutional networks (CNNs) to transformers, vary in their power to extrapolate to unseen classes both across layers and across architectures. Accuracy is not a good predictor of generalizability, and generalization varies non-monotonically with layer depth.
Create account to get full access
Overview
- The paper investigates the ability of different neural network architectures to generalize visual classification tasks in a zero-shot setting.
- The researchers compared the performance of various models, including convolutional neural networks (CNNs) and vision transformers, on unseen datasets and tasks.
- The goal was to understand how well these models can adapt to new visual domains without additional training.
Plain English Explanation
The researchers in this study wanted to see how well different types of artificial intelligence (AI) models can learn to classify images without being specifically trained on those images. This is known as "zero-shot" learning, where the models have to generalize their knowledge to new situations.
The researchers looked at several popular AI models, like convolutional neural networks (CNNs) and vision transformers. CNNs are good at processing visual information, while transformers are a more recent type of model that can handle complex patterns. The researchers tested these models on new image datasets and tasks that they hadn't been trained on before.
The key question the researchers wanted to answer was: How well can these AI models adapt to new visual domains without needing to be retrained? This is an important capability, as it could allow AI systems to be more flexible and useful in the real world, where they often encounter new types of information.
Technical Explanation
The researchers conducted experiments to evaluate the zero-shot generalization capabilities of different neural network architectures for visual classification tasks. They compared the performance of convolutional neural networks (CNNs) and vision transformers on unseen datasets and tasks.
The core idea was to assess how well these models can adapt to new visual domains without any additional training. The researchers used a variety of standard computer vision datasets, including ImageNet, CIFAR-10, and others, to evaluate the models' ability to generalize. They also tested the models on novel tasks, such as classifying images from different camera perspectives or resolutions.
The results showed that while CNNs and vision transformers both exhibited strong zero-shot performance, there were notable differences in their generalization capabilities. The vision transformers demonstrated more robust and consistent performance across the diverse test scenarios, suggesting they may have a higher capacity for adapting to new visual data.
The researchers hypothesized that the inherent structural differences between CNNs and transformers, such as the transformer's attention mechanism and global receptive field, could contribute to these observed generalization advantages. They also discussed potential implications for the design of future AI systems that need to operate in unconstrained, real-world environments.
Critical Analysis
The paper provides valuable insights into the zero-shot generalization capabilities of different neural network architectures, which is an important topic for the development of robust and adaptable AI systems. The researchers' comparative analysis of CNNs and vision transformers is well-designed and the results offer meaningful contributions to the ongoing discussion around the generalization properties of these models.
However, the paper also acknowledges several limitations and caveats that warrant further exploration. For example, the researchers note that the performance differences between the architectures may be influenced by factors like dataset bias, model size, and training procedures. Investigating these confounding variables in more depth could yield additional insights.
Additionally, the paper does not delve into the potential reasons behind the observed generalization differences between CNNs and transformers. While the researchers offer some hypotheses, a more in-depth analysis of the underlying mechanisms and architectural properties that enable superior zero-shot performance could strengthen the study's impact.
Future research could also explore the generalization capabilities of these models in more diverse and challenging task domains, such as multi-modal learning or few-shot adaptation. Expanding the scope of the evaluation could provide a more comprehensive understanding of the strengths and limitations of each architecture.
Conclusion
This study presents an important contribution to the understanding of zero-shot generalization in visual classification tasks. By comparing the performance of convolutional neural networks and vision transformers, the researchers have uncovered notable differences in the models' ability to adapt to new visual domains without additional training.
The findings suggest that the architectural properties of transformers, such as their attention mechanism and global receptive field, may confer advantages in terms of zero-shot adaptation. These insights could inform the design of future AI systems that need to operate in unconstrained, real-world environments, where the ability to generalize is crucial.
While the paper identifies several areas for further research, it provides a solid foundation for understanding the generalization capabilities of these state-of-the-art neural network architectures. As the field of AI continues to evolve, studies like this will play a vital role in shaping the development of more robust and adaptable machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
A separability-based approach to quantifying generalization: which layer is best?
Luciano Dyballa, Evan Gerritz, Steven W. Zucker
0
0
Generalization to unseen data remains poorly understood for deep learning classification and foundation models. How can one assess the ability of networks to adapt to new or extended versions of their input space in the spirit of few-shot learning, out-of-distribution generalization, and domain adaptation? Which layers of a network are likely to generalize best? We provide a new method for evaluating the capacity of networks to represent a sampled domain, regardless of whether the network has been trained on all classes in the domain. Our approach is the following: after fine-tuning state-of-the-art pre-trained models for visual classification on a particular domain, we assess their performance on data from related but distinct variations in that domain. Generalization power is quantified as a function of the latent embeddings of unseen data from intermediate layers for both unsupervised and supervised settings. Working throughout all stages of the network, we find that (i) high classification accuracy does not imply high generalizability; and (ii) deeper layers in a model do not always generalize the best, which has implications for pruning. Since the trends observed across datasets are largely consistent, we conclude that our approach reveals (a function of) the intrinsic capacity of the different layers of a model to generalize.
5/6/2024
🛸
Multi-Scale and Multi-Layer Contrastive Learning for Domain Generalization
Aristotelis Ballas, Christos Diou
0
0
During the past decade, deep neural networks have led to fast-paced progress and significant achievements in computer vision problems, for both academia and industry. Yet despite their success, state-of-the-art image classification approaches fail to generalize well in previously unseen visual contexts, as required by many real-world applications. In this paper, we focus on this domain generalization (DG) problem and argue that the generalization ability of deep convolutional neural networks can be improved by taking advantage of multi-layer and multi-scaled representations of the network. We introduce a framework that aims at improving domain generalization of image classifiers by combining both low-level and high-level features at multiple scales, enabling the network to implicitly disentangle representations in its latent space and learn domain-invariant attributes of the depicted objects. Additionally, to further facilitate robust representation learning, we propose a novel objective function, inspired by contrastive learning, which aims at constraining the extracted representations to remain invariant under distribution shifts. We demonstrate the effectiveness of our method by evaluating on the domain generalization datasets of PACS, VLCS, Office-Home and NICO. Through extensive experimentation, we show that our model is able to surpass the performance of previous DG methods and consistently produce competitive and state-of-the-art results in all datasets
5/13/2024
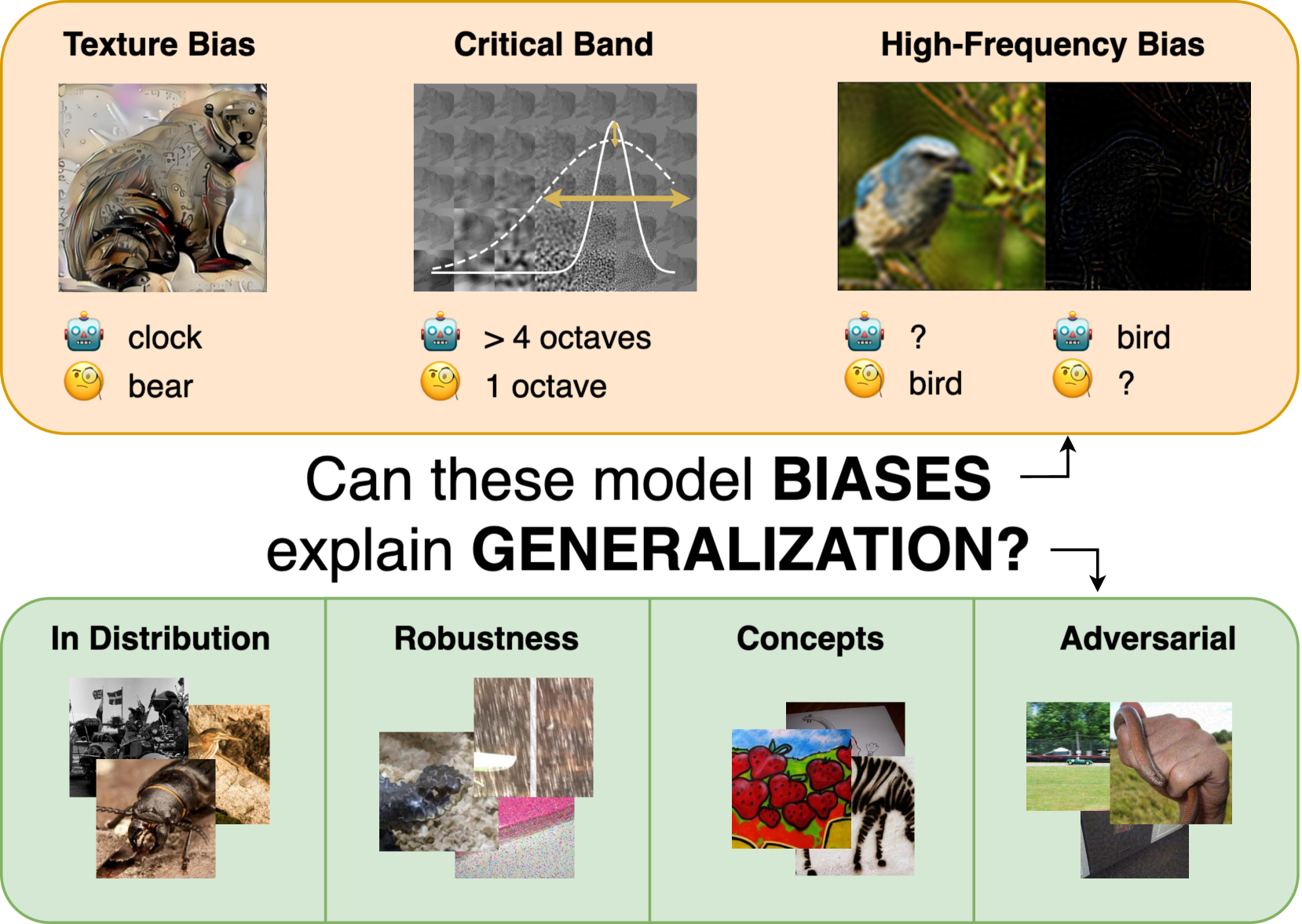
Can Biases in ImageNet Models Explain Generalization?
Paul Gavrikov, Janis Keuper
0
0
The robust generalization of models to rare, in-distribution (ID) samples drawn from the long tail of the training distribution and to out-of-training-distribution (OOD) samples is one of the major challenges of current deep learning methods. For image classification, this manifests in the existence of adversarial attacks, the performance drops on distorted images, and a lack of generalization to concepts such as sketches. The current understanding of generalization in neural networks is very limited, but some biases that differentiate models from human vision have been identified and might be causing these limitations. Consequently, several attempts with varying success have been made to reduce these biases during training to improve generalization. We take a step back and sanity-check these attempts. Fixing the architecture to the well-established ResNet-50, we perform a large-scale study on 48 ImageNet models obtained via different training methods to understand how and if these biases - including shape bias, spectral biases, and critical bands - interact with generalization. Our extensive study results reveal that contrary to previous findings, these biases are insufficient to accurately predict the generalization of a model holistically. We provide access to all checkpoints and evaluation code at https://github.com/paulgavrikov/biases_vs_generalization
4/3/2024
🏷️
Learning from One and Only One Shot
Haizi Yu, Igor Mineyev, Lav R. Varshney, James A. Evans
0
0
Humans can generalize from only a few examples and from little pretraining on similar tasks. Yet, machine learning (ML) typically requires large data to learn or pre-learn to transfer. Motivated by nativism and artificial general intelligence, we directly model human-innate priors in abstract visual tasks such as character and doodle recognition. This yields a white-box model that learns general-appearance similarity by mimicking how humans naturally ``distort'' an object at first sight. Using just nearest-neighbor classification on this cognitively-inspired similarity space, we achieve human-level recognition with only $1$--$10$ examples per class and no pretraining. This differs from few-shot learning that uses massive pretraining. In the tiny-data regime of MNIST, EMNIST, Omniglot, and QuickDraw benchmarks, we outperform both modern neural networks and classical ML. For unsupervised learning, by learning the non-Euclidean, general-appearance similarity space in a $k$-means style, we achieve multifarious visual realizations of abstract concepts by generating human-intuitive archetypes as cluster centroids.
5/22/2024