Learning from One and Only One Shot
2201.08815
0
0
🏷️
Abstract
Humans can generalize from only a few examples and from little pretraining on similar tasks. Yet, machine learning (ML) typically requires large data to learn or pre-learn to transfer. Motivated by nativism and artificial general intelligence, we directly model human-innate priors in abstract visual tasks such as character and doodle recognition. This yields a white-box model that learns general-appearance similarity by mimicking how humans naturally ``distort'' an object at first sight. Using just nearest-neighbor classification on this cognitively-inspired similarity space, we achieve human-level recognition with only $1$--$10$ examples per class and no pretraining. This differs from few-shot learning that uses massive pretraining. In the tiny-data regime of MNIST, EMNIST, Omniglot, and QuickDraw benchmarks, we outperform both modern neural networks and classical ML. For unsupervised learning, by learning the non-Euclidean, general-appearance similarity space in a $k$-means style, we achieve multifarious visual realizations of abstract concepts by generating human-intuitive archetypes as cluster centroids.
Create account to get full access
Overview
- Humans can generalize from just a few examples, while machine learning (ML) typically requires large datasets to learn or transfer from similar tasks.
- This research directly models human-innate priors in abstract visual tasks like character and doodle recognition, creating a "white-box" model that mimics how humans naturally perceive general-appearance similarity.
- Using just nearest-neighbor classification on this cognitively-inspired similarity space, the model achieves human-level recognition with only 1-10 examples per class and no pretraining, outperforming modern neural networks and classical ML in the tiny-data regime.
- For unsupervised learning, the model learns a non-Euclidean, general-appearance similarity space, generating human-intuitive archetypes as cluster centroids.
Plain English Explanation
Humans are remarkably good at recognizing and learning new things from just a few examples, even with little prior training on similar tasks. In contrast, machine learning systems typically require large datasets and extensive pretraining to achieve comparable performance.
Inspired by the concept of innate human knowledge and the goal of artificial general intelligence, this research proposes a new model that directly captures the "priors" or preexisting knowledge that humans use when perceiving and learning abstract visual tasks, such as recognizing characters or simple doodles.
The key idea is to create a "white-box" model that mimics how humans naturally "distort" or perceive the general appearance of an object at first glance. By learning this cognitively-inspired similarity space, the model can achieve human-level recognition accuracy using just 1-10 examples per class, without any pretraining on related tasks.
This is a stark contrast to few-shot learning approaches that rely on massive pretraining. In benchmarks on small datasets like MNIST, EMNIST, Omniglot, and QuickDraw, the model outperforms both modern neural networks and classical machine learning techniques.
The model's ability to learn a non-Euclidean, general-appearance similarity space also allows it to perform unsupervised learning. By applying a k-means-style clustering algorithm, the model can generate human-intuitive "archetypes" or centroids that capture the essence of abstract visual concepts.
Technical Explanation
The key technical innovation of this research is the direct modeling of human-innate priors for abstract visual tasks. The authors create a "white-box" model that learns a cognitively-inspired similarity space, where the perceived similarity between objects reflects how humans naturally "distort" them at first glance.
To achieve this, the model first learns a transformation that maps raw image data into this general-appearance similarity space. This is done by training the model to predict human-provided similarity judgments on pairs of objects. The resulting similarity space is non-Euclidean, capturing the holistic, gestalt-like way humans perceive visual similarity.
With this similarity space in hand, the researchers then use simple nearest-neighbor classification to achieve human-level recognition accuracy on benchmark tasks like character and doodle recognition. Crucially, this is done with just 1-10 examples per class, without any pretraining on related tasks, in stark contrast to few-shot learning approaches.
In the unsupervised setting, the model learns the general-appearance similarity space using a k-means-style clustering algorithm. The resulting cluster centroids serve as "archetypes" that capture the essence of abstract visual concepts in a way that aligns with human intuition.
Critical Analysis
The researchers make a compelling case for the value of directly modeling human-innate priors in machine learning, as opposed to relying on massive pretraining or complex architectures. Their approach of learning a cognitively-inspired similarity space is a promising step towards bridging the gap between human and machine learning.
However, the paper does not address several important questions:
- How generalizable is this approach? The experiments are limited to relatively simple visual tasks; can the model scale to more complex real-world problems?
- What are the underlying mechanisms that allow the model to learn such effective similarity spaces from limited data? Further analysis may yield insights into human perception and cognition.
- How does the model's performance compare to one-shot learning approaches, which aim to achieve similar data efficiency through different means?
Ultimately, this research represents an important step towards more human-like machine learning, but significant challenges remain in extending these ideas to broader, more practical applications.
Conclusion
This research proposes a novel approach to machine learning that directly models human-innate priors for abstract visual tasks. By learning a cognitively-inspired similarity space, the model can achieve human-level recognition accuracy with just 1-10 examples per class, without any pretraining.
The model's ability to learn effective representations from limited data, as well as its capacity to generate human-intuitive "archetypes" in unsupervised learning, suggests that this line of research may hold the key to bridging the gap between human and machine learning. While further work is needed to scale this approach to more complex problems, the principles demonstrated in this paper could have far-reaching implications for the future of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
Like Humans to Few-Shot Learning through Knowledge Permeation of Vision and Text
Yuyu Jia, Qing Zhou, Wei Huang, Junyu Gao, Qi Wang
0
0
Few-shot learning aims to generalize the recognizer from seen categories to an entirely novel scenario. With only a few support samples, several advanced methods initially introduce class names as prior knowledge for identifying novel classes. However, obstacles still impede achieving a comprehensive understanding of how to harness the mutual advantages of visual and textual knowledge. In this paper, we propose a coherent Bidirectional Knowledge Permeation strategy called BiKop, which is grounded in a human intuition: A class name description offers a general representation, whereas an image captures the specificity of individuals. BiKop primarily establishes a hierarchical joint general-specific representation through bidirectional knowledge permeation. On the other hand, considering the bias of joint representation towards the base set, we disentangle base-class-relevant semantics during training, thereby alleviating the suppression of potential novel-class-relevant information. Experiments on four challenging benchmarks demonstrate the remarkable superiority of BiKop. Our code will be publicly available.
5/24/2024
Many-Shot In-Context Learning
Rishabh Agarwal, Avi Singh, Lei M. Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D. Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, Hugo Larochelle
0
0
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
5/24/2024
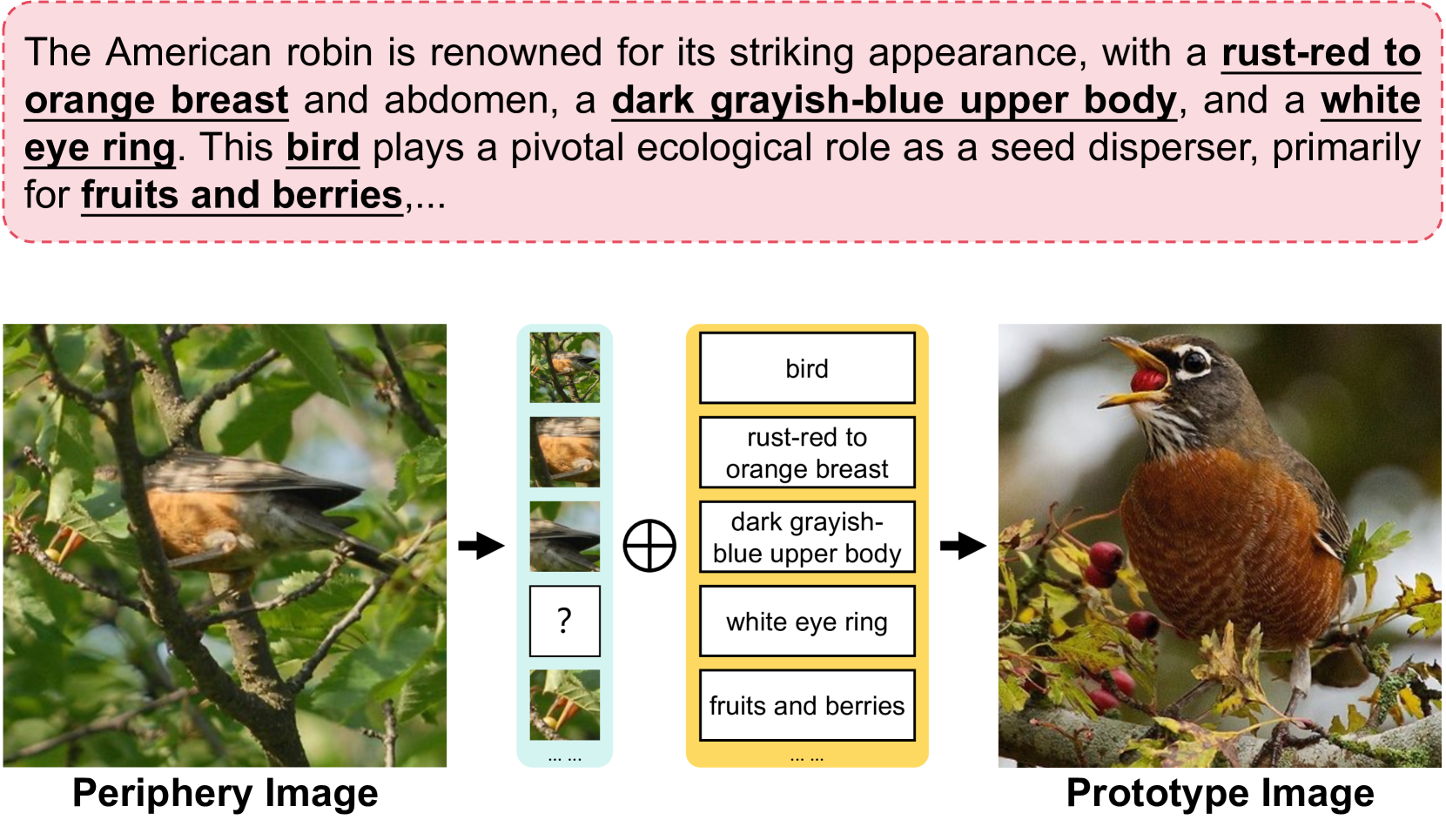
Simple Semantic-Aided Few-Shot Learning
Hai Zhang, Junzhe Xu, Shanlin Jiang, Zhenan He
0
0
Learning from a limited amount of data, namely Few-Shot Learning, stands out as a challenging computer vision task. Several works exploit semantics and design complicated semantic fusion mechanisms to compensate for rare representative features within restricted data. However, relying on naive semantics such as class names introduces biases due to their brevity, while acquiring extensive semantics from external knowledge takes a huge time and effort. This limitation severely constrains the potential of semantics in Few-Shot Learning. In this paper, we design an automatic way called Semantic Evolution to generate high-quality semantics. The incorporation of high-quality semantics alleviates the need for complex network structures and learning algorithms used in previous works. Hence, we employ a simple two-layer network termed Semantic Alignment Network to transform semantics and visual features into robust class prototypes with rich discriminative features for few-shot classification. The experimental results show our framework outperforms all previous methods on six benchmarks, demonstrating a simple network with high-quality semantics can beat intricate multi-modal modules on few-shot classification tasks. Code is available at https://github.com/zhangdoudou123/SemFew.
4/10/2024
🛠️
What Makes Good Few-shot Examples for Vision-Language Models?
Zhaojun Guo, Jinghui Lu, Xuejing Liu, Rui Zhao, ZhenXing Qian, Fei Tan
0
0
Despite the notable advancements achieved by leveraging pre-trained vision-language (VL) models through few-shot tuning for downstream tasks, our detailed empirical study highlights a significant dependence of few-shot learning outcomes on the careful selection of training examples - a facet that has been previously overlooked in research. In this study, we delve into devising more effective strategies for the meticulous selection of few-shot training examples, as opposed to relying on random sampling, to enhance the potential of existing few-shot prompt learning methodologies. To achieve this, we assess the effectiveness of various Active Learning (AL) techniques for instance selection, such as Entropy and Margin of Confidence, within the context of few-shot training. Furthermore, we introduce two innovative selection methods - Representativeness (REPRE) and Gaussian Monte Carlo (Montecarlo) - designed to proactively pinpoint informative examples for labeling in relation to pre-trained VL models. Our findings demonstrate that both REPRE and Montecarlo significantly surpass both random selection and AL-based strategies in few-shot training scenarios. The research also underscores that these instance selection methods are model-agnostic, offering a versatile enhancement to a wide array of few-shot training methodologies.
5/24/2024