Zero-Shot Multi-Lingual Speaker Verification in Clinical Trials
2404.01981
0
0
👁️
Abstract
Due to the substantial number of clinicians, patients, and data collection environments involved in clinical trials, gathering data of superior quality poses a significant challenge. In clinical trials, patients are assessed based on their speech data to detect and monitor cognitive and mental health disorders. We propose using these speech recordings to verify the identities of enrolled patients and identify and exclude the individuals who try to enroll multiple times in the same trial. Since clinical studies are often conducted across different countries, creating a system that can perform speaker verification in diverse languages without additional development effort is imperative. We evaluate pre-trained TitaNet, ECAPA-TDNN, and SpeakerNet models by enrolling and testing with speech-impaired patients speaking English, German, Danish, Spanish, and Arabic languages. Our results demonstrate that tested models can effectively generalize to clinical speakers, with less than 2.7% EER for European Languages and 8.26% EER for Arabic. This represents a significant step in developing more versatile and efficient speaker verification systems for cognitive and mental health clinical trials that can be used across a wide range of languages and dialects, substantially reducing the effort required to develop speaker verification systems for multiple languages. We also evaluate how speech tasks and number of speakers involved in the trial influence the performance and show that the type of speech tasks impacts the model performance.
Create account to get full access
Overview
- This paper presents a novel approach for speaker verification in clinical settings that can work across multiple languages without requiring language-specific training.
- The method leverages recent advances in multilingual speech recognition and machine learning to enable "zero-shot" speaker verification, where the system can accurately identify speakers in new languages it has not been explicitly trained on.
- The authors demonstrate the effectiveness of their approach on several clinical speech datasets, showing it can reliably detect speech patterns associated with conditions like Alzheimer's, mild cognitive impairment, and schizophrenia.
Plain English Explanation
The paper introduces a new way to verify a person's identity by the sound of their voice, even if that person is speaking a language the verification system hasn't been trained on before. This is useful in clinical settings like Alzheimer's or mental health studies, where patients may speak different languages.
Traditionally, voice identification systems need to be trained on many examples of a person's voice in a specific language. But the approach described here can work without that - it can recognize a speaker's voice across multiple languages. This "zero-shot" capability means the system doesn't need to be retrained for each new language.
The key is that the system taps into recent advances in multilingual speech recognition and machine learning. It can detect subtle patterns in how a person speaks that are unique to them, regardless of the language. So it can accurately identify speakers even if it's never heard their voice in that particular language before.
The authors show this works well for detecting speech patterns associated with conditions like Alzheimer's, mild cognitive impairment, and schizophrenia. This could be a valuable tool for clinical trials and studies involving diverse patient populations.
Technical Explanation
The paper presents a zero-shot multilingual speaker verification (ZMSVR) system that can accurately identify speakers across languages without requiring language-specific training. The core innovation is a deep learning architecture that leverages cross-lingual transfer learning to extract language-agnostic speaker representations.
The system first uses a pretrained multilingual speech recognition model to obtain phoneme-level embeddings from the input speech. These embeddings capture articulatory and acoustic cues that are informative of speaker identity, while being robust to language differences. The phoneme embeddings are then fed into a speaker verification network, which learns to map them to a compact speaker embedding space.
During training, the speaker verification network is exposed to speakers from multiple languages, enabling it to learn language-invariant speaker representations. At test time, the trained model can then be applied to speakers in new languages it has not seen, achieving zero-shot cross-lingual speaker verification.
The authors evaluate their ZMSVR system on several clinical speech datasets, including Alzheimer's, mild cognitive impairment, and schizophrenia. They demonstrate that the zero-shot approach outperforms strong language-dependent baselines, highlighting its potential utility for clinical trials and studies involving diverse patient populations.
Critical Analysis
The paper presents a compelling solution to the challenge of speaker verification in multilingual clinical settings. The zero-shot capability is a notable advance, as it avoids the need for costly data collection and model retraining for each new language.
However, the evaluation is limited to a relatively small number of languages (English, Mandarin, Spanish) and clinical conditions. Further research is needed to assess the generalization of the approach to a wider range of languages and medical applications. The authors also note that the system relies on high-quality speech recordings, which may not always be available in real-world clinical settings.
Additionally, while the paper demonstrates the ZMSVR system's accuracy in speaker verification, it does not provide a deep analysis of the language-invariant speaker representations it learns. Understanding the model's internal workings could shed light on the acoustic and articulatory cues it uses to recognize speakers across languages.
Overall, the proposed ZMSVR approach is a valuable contribution to the field of multilingual speaker recognition, with promising implications for clinical applications involving diverse patient populations. Further research to address the current limitations could enhance the practical impact of this work.
Conclusion
This paper presents a novel zero-shot multilingual speaker verification system that can accurately identify speakers across languages without requiring language-specific training. By leveraging recent advances in multilingual speech recognition and deep learning, the system can extract language-agnostic speaker representations that enable reliable speaker verification in clinical settings involving diverse patient populations.
The authors demonstrate the effectiveness of their approach on several clinical speech datasets, showing it can detect speech patterns associated with conditions like Alzheimer's, mild cognitive impairment, and schizophrenia. This capability could be a valuable tool for clinical trials and studies, facilitating the inclusion of participants from a wider range of linguistic backgrounds.
While the current evaluation is limited in scope, the zero-shot multilingual approach represents a significant advance in the field of speaker verification. Further research to enhance the robustness and generalization of the system could lead to important real-world applications in healthcare and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
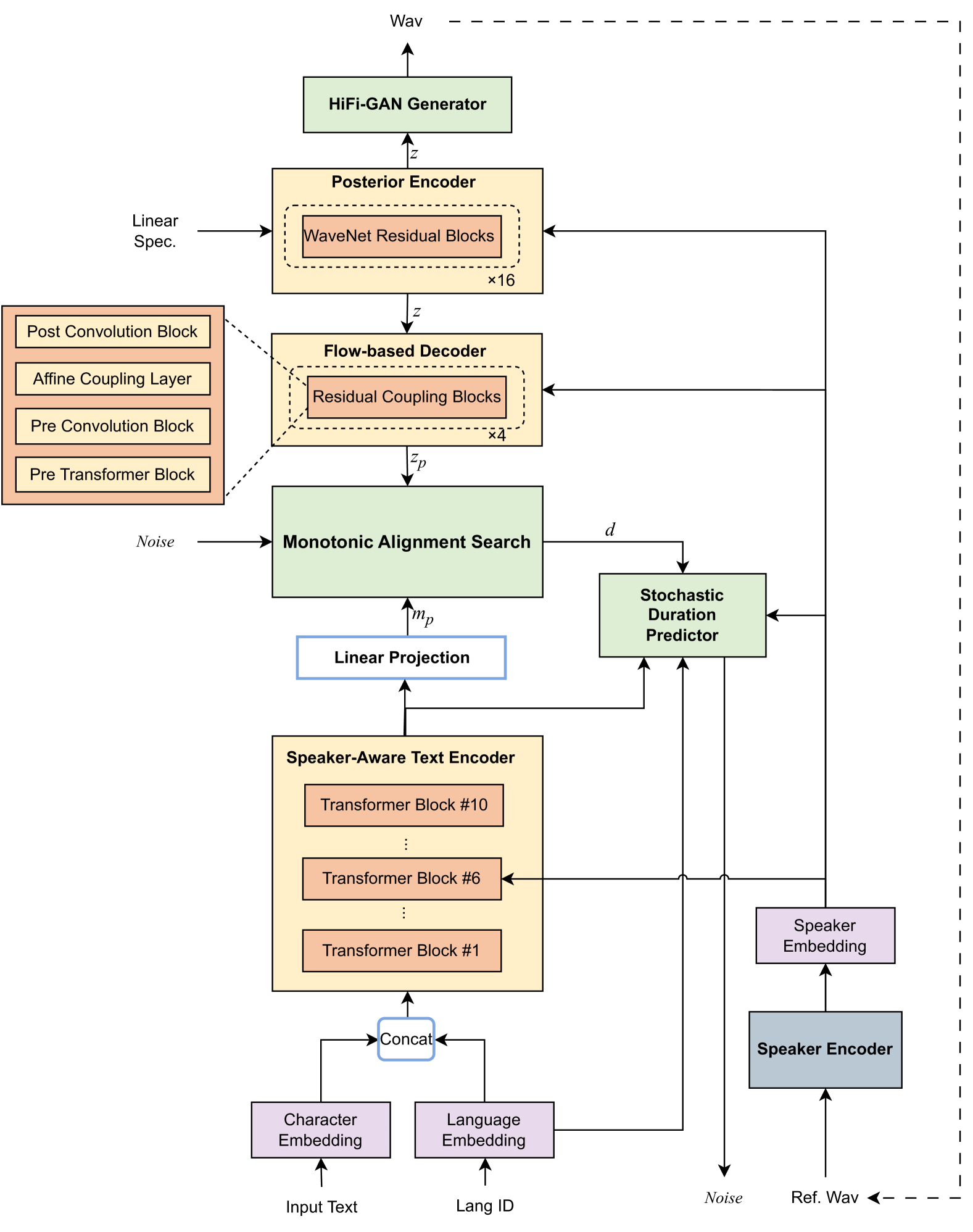
The THU-HCSI Multi-Speaker Multi-Lingual Few-Shot Voice Cloning System for LIMMITS'24 Challenge
Yixuan Zhou, Shuoyi Zhou, Shun Lei, Zhiyong Wu, Menglin Wu
0
0
This paper presents the multi-speaker multi-lingual few-shot voice cloning system developed by THU-HCSI team for LIMMITS'24 Challenge. To achieve high speaker similarity and naturalness in both mono-lingual and cross-lingual scenarios, we build the system upon YourTTS and add several enhancements. For further improving speaker similarity and speech quality, we introduce speaker-aware text encoder and flow-based decoder with Transformer blocks. In addition, we denoise the few-shot data, mix up them with pre-training data, and adopt a speaker-balanced sampling strategy to guarantee effective fine-tuning for target speakers. The official evaluations in track 1 show that our system achieves the best speaker similarity MOS of 4.25 and obtains considerable naturalness MOS of 3.97.
4/26/2024
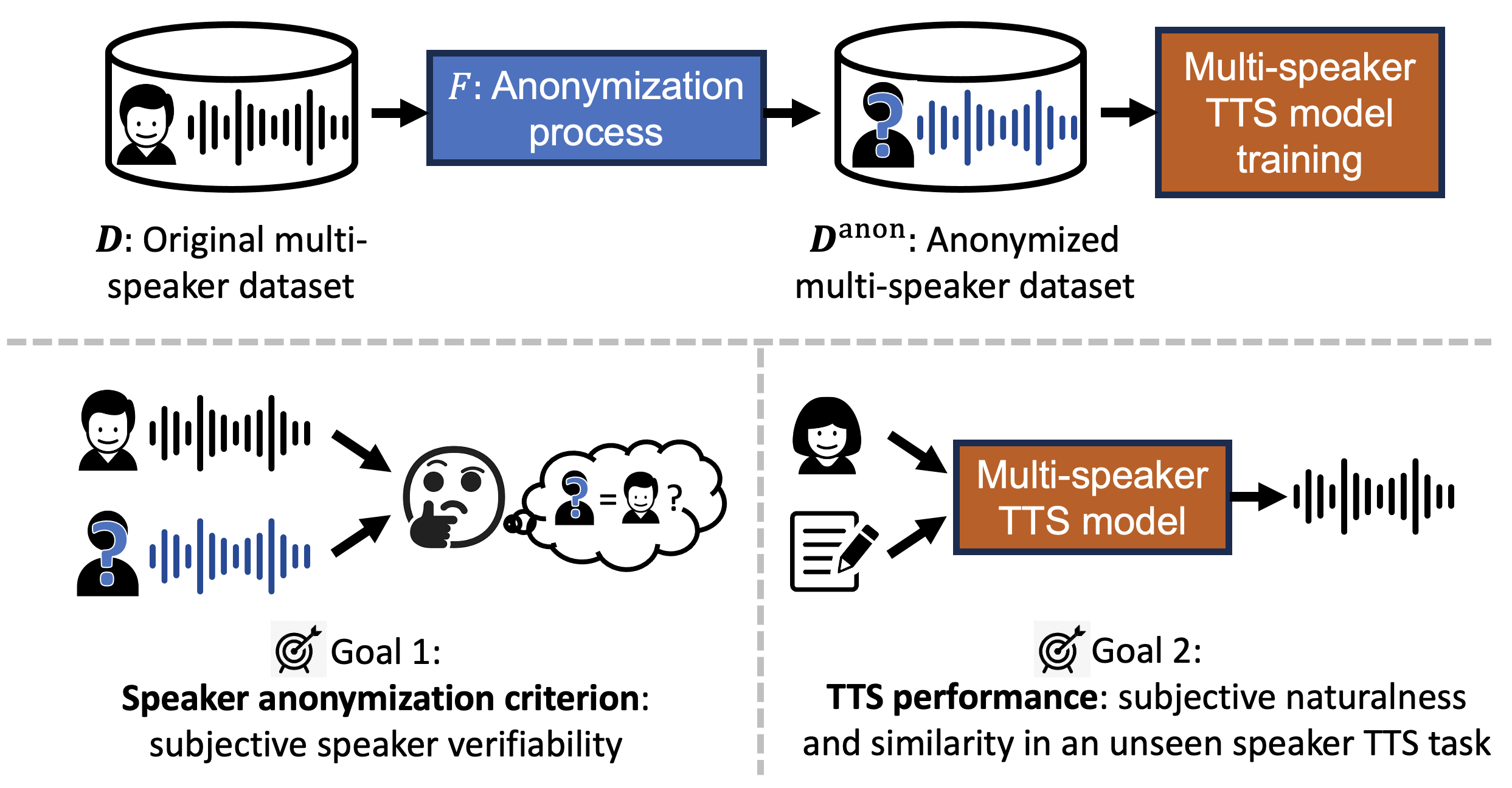
Multi-speaker Text-to-speech Training with Speaker Anonymized Data
Wen-Chin Huang, Yi-Chiao Wu, Tomoki Toda
0
0
The trend of scaling up speech generation models poses a threat of biometric information leakage of the identities of the voices in the training data, raising privacy and security concerns. In this paper, we investigate training multi-speaker text-to-speech (TTS) models using data that underwent speaker anonymization (SA), a process that tends to hide the speaker identity of the input speech while maintaining other attributes. Two signal processing-based and three deep neural network-based SA methods were used to anonymize VCTK, a multi-speaker TTS dataset, which is further used to train an end-to-end TTS model, VITS, to perform unseen speaker TTS during the testing phase. We conducted extensive objective and subjective experiments to evaluate the anonymized training data, as well as the performance of the downstream TTS model trained using those data. Importantly, we found that UTMOS, a data-driven subjective rating predictor model, and GVD, a metric that measures the gain of voice distinctiveness, are good indicators of the downstream TTS performance. We summarize insights in the hope of helping future researchers determine the goodness of the SA system for multi-speaker TTS training.
5/21/2024

New!Towards Zero-Shot Text-To-Speech for Arabic Dialects
Khai Duy Doan, Abdul Waheed, Muhammad Abdul-Mageed
0
0
Zero-shot multi-speaker text-to-speech (ZS-TTS) systems have advanced for English, however, it still lags behind due to insufficient resources. We address this gap for Arabic, a language of more than 450 million native speakers, by first adapting a sizeable existing dataset to suit the needs of speech synthesis. Additionally, we employ a set of Arabic dialect identification models to explore the impact of pre-defined dialect labels on improving the ZS-TTS model in a multi-dialect setting. Subsequently, we fine-tune the XTTSfootnote{https://docs.coqui.ai/en/latest/models/xtts.html}footnote{https://medium.com/machine-learns/xtts-v2-new-version-of-the-open-source-text-to-speech-model-af73914db81f}footnote{https://medium.com/@erogol/xtts-v1-techincal-notes-eb83ff05bdc} model, an open-source architecture. We then evaluate our models on a dataset comprising 31 unseen speakers and an in-house dialectal dataset. Our automated and human evaluation results show convincing performance while capable of generating dialectal speech. Our study highlights significant potential for improvements in this emerging area of research in Arabic.
6/26/2024
Zero-Shot End-To-End Spoken Question Answering In Medical Domain
Yanis Labrak, Adel Moumen, Richard Dufour, Mickael Rouvier
0
0
In the rapidly evolving landscape of spoken question-answering (SQA), the integration of large language models (LLMs) has emerged as a transformative development. Conventional approaches often entail the use of separate models for question audio transcription and answer selection, resulting in significant resource utilization and error accumulation. To tackle these challenges, we explore the effectiveness of end-to-end (E2E) methodologies for SQA in the medical domain. Our study introduces a novel zero-shot SQA approach, compared to traditional cascade systems. Through a comprehensive evaluation conducted on a new open benchmark of 8 medical tasks and 48 hours of synthetic audio, we demonstrate that our approach requires up to 14.7 times fewer resources than a combined 1.3B parameters LLM with a 1.55B parameters ASR model while improving average accuracy by 0.5%. These findings underscore the potential of E2E methodologies for SQA in resource-constrained contexts.
6/11/2024