Towards Zero-Shot Text-To-Speech for Arabic Dialects
2406.16751
0
0

Abstract
Zero-shot multi-speaker text-to-speech (ZS-TTS) systems have advanced for English, however, it still lags behind due to insufficient resources. We address this gap for Arabic, a language of more than 450 million native speakers, by first adapting a sizeable existing dataset to suit the needs of speech synthesis. Additionally, we employ a set of Arabic dialect identification models to explore the impact of pre-defined dialect labels on improving the ZS-TTS model in a multi-dialect setting. Subsequently, we fine-tune the XTTSfootnote{https://docs.coqui.ai/en/latest/models/xtts.html}footnote{https://medium.com/machine-learns/xtts-v2-new-version-of-the-open-source-text-to-speech-model-af73914db81f}footnote{https://medium.com/@erogol/xtts-v1-techincal-notes-eb83ff05bdc} model, an open-source architecture. We then evaluate our models on a dataset comprising 31 unseen speakers and an in-house dialectal dataset. Our automated and human evaluation results show convincing performance while capable of generating dialectal speech. Our study highlights significant potential for improvements in this emerging area of research in Arabic.
Create account to get full access
Overview
- This paper proposes a novel zero-shot text-to-speech (TTS) model called XTTS that can generate high-quality speech in multiple Arabic dialects without requiring dialect-specific training data.
- The model leverages a massively multilingual TTS framework and meta-learning techniques to enable rapid adaptation to new dialects.
- The authors demonstrate the effectiveness of XTTS on several benchmark datasets, showing it can outperform prior state-of-the-art zero-shot TTS approaches for Arabic.
Plain English Explanation
The paper describes a new AI system called XTTS that can generate natural-sounding speech in different Arabic dialects, even if it hasn't been specifically trained on that dialect before. This is known as "zero-shot" learning, where the system can adapt to new tasks or languages without requiring dedicated training data.
The key idea behind XTTS is that it builds on a large, multilingual TTS model that has been trained on many languages and dialects. Then, the researchers use a special "meta-learning" technique to help the model quickly adapt and generate high-quality speech in new dialects it hasn't seen before. This allows the model to be applied flexibly to a wide range of Arabic dialects, without the need to collect and train on dialect-specific data for each one.
The researchers test XTTS on several standard benchmarks for Arabic TTS, and show that it outperforms previous zero-shot approaches. This suggests the model is an effective way to enable multilingual TTS capabilities without the usual challenges of data collection and dialect-specific training.
Technical Explanation
The XTTS model builds upon prior work in massively multilingual TTS and meta-learning for TTS to enable zero-shot adaptation to new Arabic dialects.
The core architecture consists of a multilingual encoder-decoder model trained on a diverse set of languages and dialects. This provides a strong starting point for adapting to new target dialects. The researchers then apply meta-learning techniques, specifically MAML, to enable rapid fine-tuning of the model on limited data from the target dialect.
Through extensive experiments, the authors demonstrate that XTTS can outperform prior state-of-the-art zero-shot Arabic TTS approaches by a significant margin, achieving high subjective and objective quality scores. This highlights the effectiveness of the multilingual and meta-learning components in enabling robust zero-shot adaptation.
Critical Analysis
The paper provides a compelling solution to the challenge of enabling TTS capabilities across diverse Arabic dialects without the need for dialect-specific training data. The XTTS model leverages relevant prior research in multilingual TTS and meta-learning to achieve strong zero-shot performance.
One potential limitation is the reliance on a fixed set of target dialects during meta-training. While the model can adapt to new dialects, the performance may be constrained by the diversity of dialects seen during training. Expanding the set of meta-training dialects could further improve the model's zero-shot capabilities.
Additionally, the authors note that the current version of XTTS does not explicitly model speaker identity, which could limit its flexibility in applications that require personalized voices. Incorporating speaker adaptation techniques could be an area for future work.
Overall, the XTTS model represents a significant advancement in zero-shot TTS for Arabic, with promising implications for enabling multilingual speech technology in resource-constrained settings.
Conclusion
The Towards Zero-Shot Text-To-Speech for Arabic Dialects paper introduces a novel zero-shot TTS model called XTTS that can generate high-quality speech in multiple Arabic dialects without requiring dialect-specific training data. By leveraging a massively multilingual TTS framework and meta-learning techniques, XTTS demonstrates state-of-the-art performance on several Arabic TTS benchmarks.
This research highlights the potential of zero-shot learning to enable flexible and scalable speech technology, particularly in multilingual settings where data collection and model training can be challenging. The XTTS model represents an important step forward in making speech synthesis more accessible and applicable across diverse languages and dialects.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model
Edresson Casanova, Kelly Davis, Eren Golge, Gorkem Goknar, Iulian Gulea, Logan Hart, Aya Aljafari, Joshua Meyer, Reuben Morais, Samuel Olayemi, Julian Weber
0
0
Most Zero-shot Multi-speaker TTS (ZS-TTS) systems support only a single language. Although models like YourTTS, VALL-E X, Mega-TTS 2, and Voicebox explored Multilingual ZS-TTS they are limited to just a few high/medium resource languages, limiting the applications of these models in most of the low/medium resource languages. In this paper, we aim to alleviate this issue by proposing and making publicly available the XTTS system. Our method builds upon the Tortoise model and adds several novel modifications to enable multilingual training, improve voice cloning, and enable faster training and inference. XTTS was trained in 16 languages and achieved state-of-the-art (SOTA) results in most of them.
6/10/2024

Meta Learning Text-to-Speech Synthesis in over 7000 Languages
Florian Lux, Sarina Meyer, Lyonel Behringer, Frank Zalkow, Phat Do, Matt Coler, Emanuel A. P. Habets, Ngoc Thang Vu
0
0
In this work, we take on the challenging task of building a single text-to-speech synthesis system that is capable of generating speech in over 7000 languages, many of which lack sufficient data for traditional TTS development. By leveraging a novel integration of massively multilingual pretraining and meta learning to approximate language representations, our approach enables zero-shot speech synthesis in languages without any available data. We validate our system's performance through objective measures and human evaluation across a diverse linguistic landscape. By releasing our code and models publicly, we aim to empower communities with limited linguistic resources and foster further innovation in the field of speech technology.
6/11/2024
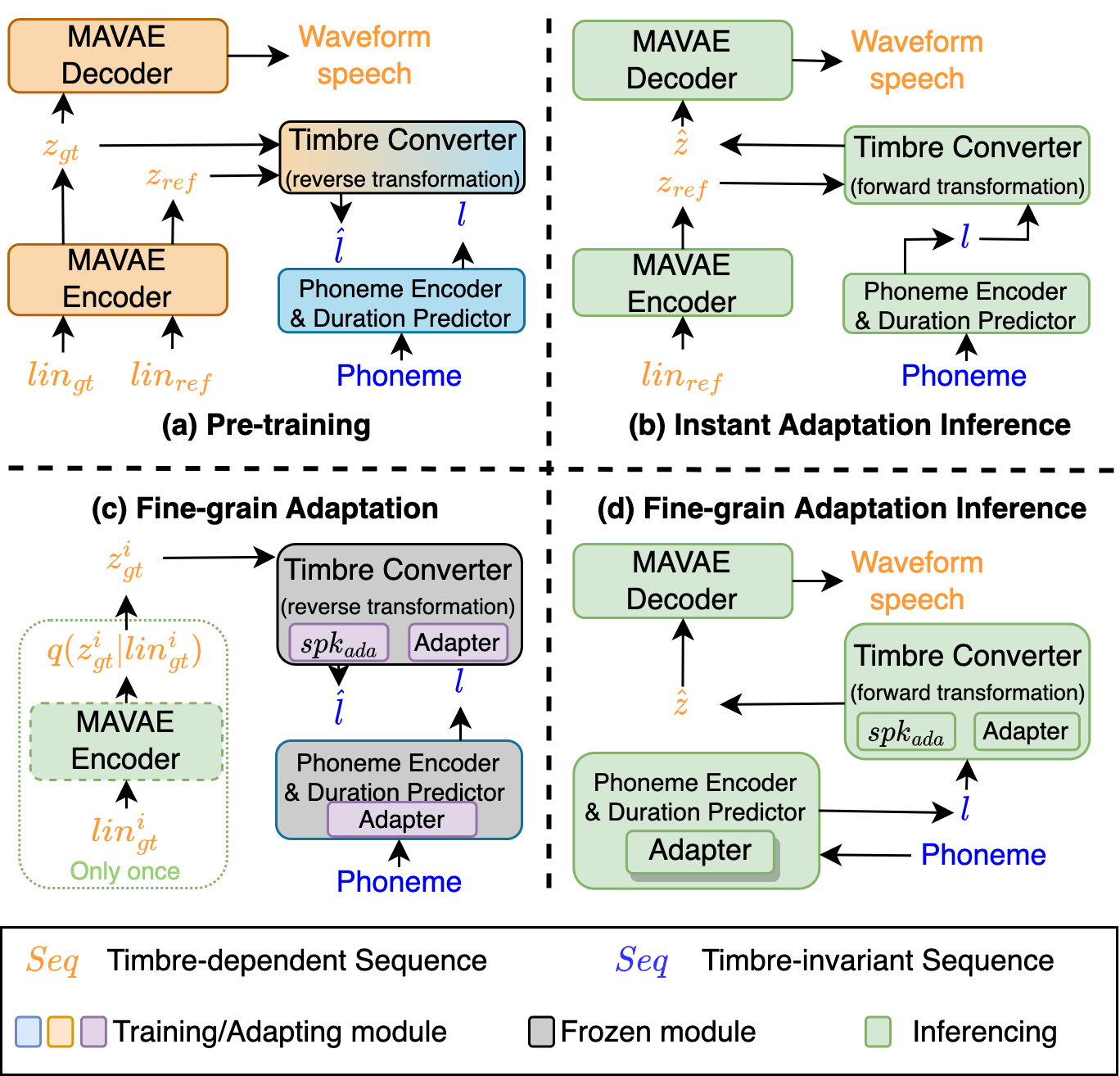
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Wenbin Wang, Yang Song, Sanjay Jha
0
0
Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as instant and fine-grained adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
4/30/2024

DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
Keon Lee, Dong Won Kim, Jaehyeon Kim, Jaewoong Cho
0
0
Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
6/18/2024