zsLLMCode: An Effective Approach for Functional Code Embedding via LLM with Zero-Shot Learning

0
🤔
Sign in to get full access
Overview
- Large language models (LLMs) have the capability of zero-shot learning, which means they can perform tasks without requiring training or fine-tuning, unlike pre-trained models (PTMs).
- However, LLMs are primarily designed for natural language output and cannot directly produce intermediate embeddings from source code.
- LLMs also face challenges, such as restricted context length, which may prevent them from handling larger inputs, limiting their applicability to many software engineering (SE) tasks.
- Hallucinations may occur when LLMs are applied to complex downstream tasks.
Plain English Explanation
To address the limitations of LLMs in software engineering tasks, the researchers propose a novel approach called zsLLMCode. This approach utilizes LLMs to convert source code into concise summaries through zero-shot learning, which are then transformed into functional code embeddings using specialized embedding models.
The key idea is to leverage the natural language processing capabilities of LLMs to generate summaries of source code, and then use these summaries to create code embeddings that can be used in various software engineering tasks. This unsupervised approach eliminates the need for training and addresses the issue of hallucinations encountered with LLMs.
The researchers conducted experiments to evaluate the performance of their approach, and the results demonstrate its effectiveness and superiority over state-of-the-art unsupervised methods.
Technical Explanation
The researchers propose a zsLLMCode approach that combines LLMs and embedding models to generate functional code embeddings. The approach utilizes LLMs to convert source code into concise summaries through zero-shot learning, which are then transformed into functional code embeddings using specialized embedding models.
This unsupervised approach addresses the limitations of LLMs, such as their inability to directly produce intermediate embeddings from source code and the challenge of hallucinations when applied to complex downstream tasks. By leveraging the natural language processing capabilities of LLMs, the researchers can generate summaries of source code, which are then used to create code embeddings that can be used in various software engineering tasks.
The researchers conducted experiments to evaluate the performance of their approach and compared it to state-of-the-art unsupervised methods. The results demonstrate the effectiveness and superiority of the zsLLMCode approach.
Critical Analysis
The researchers acknowledge that while their zsLLMCode approach addresses the limitations of LLMs, there are still some potential caveats and areas for further research.
One concern is the restricted context length of LLMs, which may prevent them from handling larger inputs, limiting their applicability to some software engineering tasks. Additionally, while the zsLLMCode approach addresses the issue of hallucinations, there may be other challenges that arise when applying LLMs to complex downstream tasks.
The researchers suggest that further research could explore ways to enhance the performance and scalability of their approach, such as investigating techniques to handle larger inputs or improve the accuracy of the code embeddings generated.
Conclusion
The zsLLMCode approach proposed by the researchers represents a promising step towards leveraging the power of LLMs for software engineering tasks. By combining LLMs and embedding models, the approach generates functional code embeddings without the need for training, addressing the limitations of LLMs and providing an effective way to utilize them in various software engineering applications.
The researchers' findings demonstrate the potential of this approach and pave the way for further advancements in the field of software engineering, particularly in areas such as code analysis, understanding, and automation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
New!zsLLMCode: An Effective Approach for Functional Code Embedding via LLM with Zero-Shot Learning
Zixiang Xian, Chenhui Cui, Rubing Huang, Chunrong Fang, Zhenyu Chen
Regarding software engineering (SE) tasks, Large language models (LLMs) have the capability of zero-shot learning, which does not require training or fine-tuning, unlike pre-trained models (PTMs). However, LLMs are primarily designed for natural language output, and cannot directly produce intermediate embeddings from source code. They also face some challenges, for example, the restricted context length may prevent them from handling larger inputs, limiting their applicability to many SE tasks; while hallucinations may occur when LLMs are applied to complex downstream tasks. Motivated by the above facts, we propose zsLLMCode, a novel approach that generates functional code embeddings using LLMs. Our approach utilizes LLMs to convert source code into concise summaries through zero-shot learning, which is then transformed into functional code embeddings using specialized embedding models. This unsupervised approach eliminates the need for training and addresses the issue of hallucinations encountered with LLMs. To the best of our knowledge, this is the first approach that combines LLMs and embedding models to generate code embeddings. We conducted experiments to evaluate the performance of our approach. The results demonstrate the effectiveness and superiority of our approach over state-of-the-art unsupervised methods.
Read more9/24/2024
0
Uncovering LLM-Generated Code: A Zero-Shot Synthetic Code Detector via Code Rewriting
Tong Ye, Yangkai Du, Tengfei Ma, Lingfei Wu, Xuhong Zhang, Shouling Ji, Wenhai Wang
Large Language Models (LLMs) have exhibited remarkable proficiency in generating code. However, the misuse of LLM-generated (Synthetic) code has prompted concerns within both educational and industrial domains, highlighting the imperative need for the development of synthetic code detectors. Existing methods for detecting LLM-generated content are primarily tailored for general text and often struggle with code content due to the distinct grammatical structure of programming languages and massive low-entropy tokens. Building upon this, our work proposes a novel zero-shot synthetic code detector based on the similarity between the code and its rewritten variants. Our method relies on the intuition that the differences between the LLM-rewritten and original codes tend to be smaller when the original code is synthetic. We utilize self-supervised contrastive learning to train a code similarity model and assess our approach on two synthetic code detection benchmarks. Our results demonstrate a notable enhancement over existing synthetic content detectors designed for general texts, with an improvement of 20.5% in the APPS benchmark and 29.1% in the MBPP benchmark.
Read more5/31/2024

0
Bridging the Language Gap: Enhancing Multilingual Prompt-Based Code Generation in LLMs via Zero-Shot Cross-Lingual Transfer
Mingda Li, Abhijit Mishra, Utkarsh Mujumdar
The use of Large Language Models (LLMs) for program code generation has gained substantial attention, but their biases and limitations with non-English prompts challenge global inclusivity. This paper investigates the complexities of multilingual prompt-based code generation. Our evaluations of LLMs, including CodeLLaMa and CodeGemma, reveal significant disparities in code quality for non-English prompts; we also demonstrate the inadequacy of simple approaches like prompt translation, bootstrapped data augmentation, and fine-tuning. To address this, we propose a zero-shot cross-lingual approach using a neural projection technique, integrating a cross-lingual encoder like LASER artetxe2019massively to map multilingual embeddings from it into the LLM's token space. This method requires training only on English data and scales effectively to other languages. Results on a translated and quality-checked MBPP dataset show substantial improvements in code quality. This research promotes a more inclusive code generation landscape by empowering LLMs with multilingual capabilities to support the diverse linguistic spectrum in programming.
Read more8/20/2024
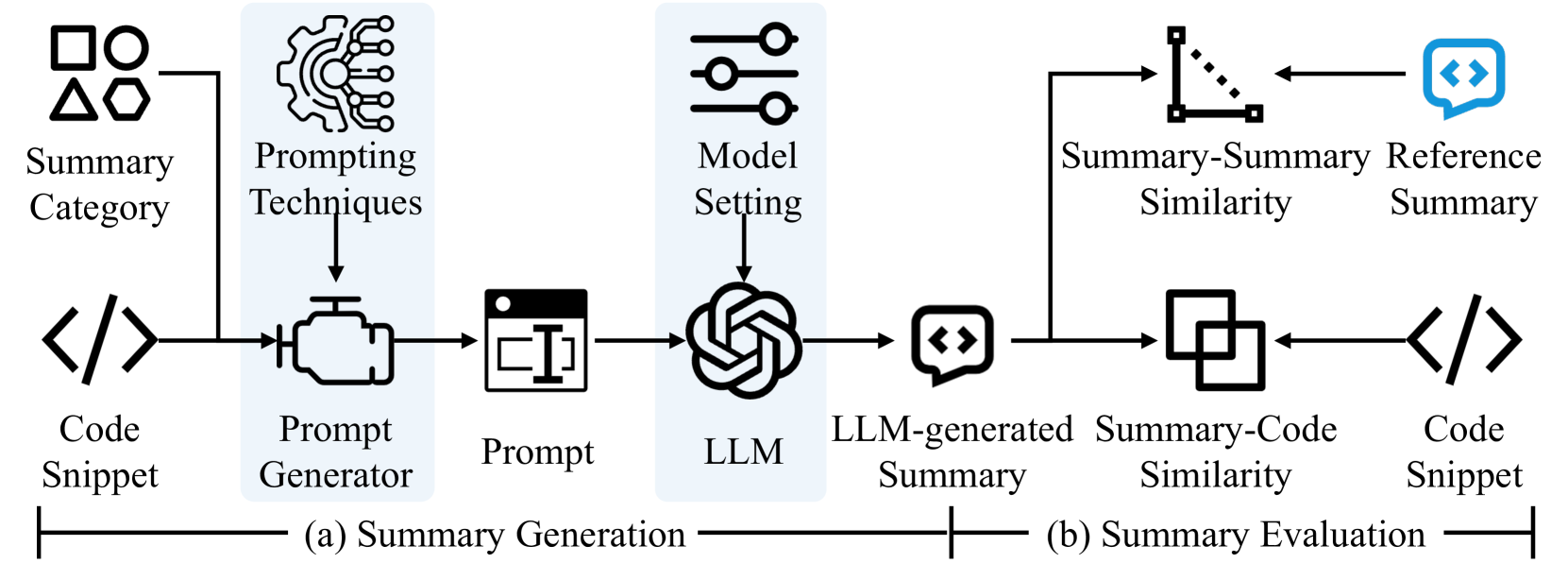
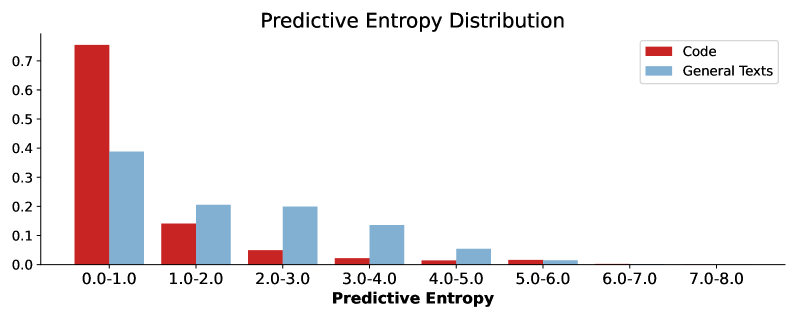
0
Source Code Summarization in the Era of Large Language Models
Weisong Sun, Yun Miao, Yuekang Li, Hongyu Zhang, Chunrong Fang, Yi Liu, Gelei Deng, Yang Liu, Zhenyu Chen
To support software developers in understanding and maintaining programs, various automatic (source) code summarization techniques have been proposed to generate a concise natural language summary (i.e., comment) for a given code snippet. Recently, the emergence of large language models (LLMs) has led to a great boost in the performance of code-related tasks. In this paper, we undertake a systematic and comprehensive study on code summarization in the era of LLMs, which covers multiple aspects involved in the workflow of LLM-based code summarization. Specifically, we begin by examining prevalent automated evaluation methods for assessing the quality of summaries generated by LLMs and find that the results of the GPT-4 evaluation method are most closely aligned with human evaluation. Then, we explore the effectiveness of five prompting techniques (zero-shot, few-shot, chain-of-thought, critique, and expert) in adapting LLMs to code summarization tasks. Contrary to expectations, advanced prompting techniques may not outperform simple zero-shot prompting. Next, we investigate the impact of LLMs' model settings (including top_p and temperature parameters) on the quality of generated summaries. We find the impact of the two parameters on summary quality varies by the base LLM and programming language, but their impacts are similar. Moreover, we canvass LLMs' abilities to summarize code snippets in distinct types of programming languages. The results reveal that LLMs perform suboptimally when summarizing code written in logic programming languages compared to other language types. Finally, we unexpectedly find that CodeLlama-Instruct with 7B parameters can outperform advanced GPT-4 in generating summaries describing code implementation details and asserting code properties. We hope that our findings can provide a comprehensive understanding of code summarization in the era of LLMs.
Read more7/12/2024