Source Code Summarization in the Era of Large Language Models

0
Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) for the task of source code summarization.
- The authors investigate the performance of LLMs in generating concise and accurate summaries of source code, a critical task for software engineering.
- The paper provides a comprehensive analysis of various LLM-based approaches and their effectiveness in summarizing code from different programming languages and domains.
Plain English Explanation
In the era of increasingly powerful large language models (LLMs), researchers have turned their attention to using these advanced AI systems to summarize source code. Summarizing code is an important task in software engineering, as it helps developers quickly understand the purpose and functionality of a codebase without having to read through every line.
The authors of this paper explore how well LLMs, such as GPT-3 and Codex, perform at generating concise and accurate summaries of source code. They test these models on a variety of programming languages and domains, ranging from simple utilities to complex enterprise-level applications. The results show that LLMs can indeed produce useful summaries, but there are also some limitations and areas for improvement.
One key finding is that the performance of LLMs can vary depending on the complexity and style of the code being summarized. For example, the models may struggle with summarizing code that relies heavily on domain-specific jargon or complex algorithms. The researchers also note that the quality of the summaries can be influenced by the way the prompts are crafted when interacting with the LLMs.
Overall, this paper provides valuable insights into the current state of LLM-based source code summarization and points to exciting opportunities for further research and development in this area. As LLMs continue to advance, they could become increasingly useful tools for software engineers, helping them more efficiently navigate and understand large, complex codebases.
Technical Explanation
The paper begins by reviewing the current state of research on large language models (LLMs) and their application to source code summarization. The authors note that while LLMs have shown promising results in various natural language processing tasks, their performance on the specific challenge of summarizing source code has not been extensively studied.
To address this gap, the researchers conduct a series of experiments to evaluate the effectiveness of several LLM-based approaches for source code summarization. They test models such as GPT-3 and Codex on a diverse dataset of source code from various programming languages and domains, ranging from simple utilities to complex enterprise-level applications.
The experimental setup involves providing the LLMs with code snippets and prompting them to generate concise summaries. The authors then assess the quality of the generated summaries using both automated metrics and human evaluation. They also explore the impact of different prompt engineering techniques on the summarization performance.
The results show that LLMs can indeed generate useful summaries of source code, with some models outperforming others depending on the complexity and style of the code. However, the researchers also identify key limitations, such as the models' struggle with domain-specific terminology and complex algorithmic logic.
The paper also provides a comparative analysis of open-source language models for code summarization, highlighting the tradeoffs between model size, performance, and computational efficiency. Additionally, the authors examine the comparative performance of large language models on the task of code documentation summarization, further expanding the understanding of LLM-based approaches in this domain.
Critical Analysis
The paper presents a thorough and well-designed study on the application of large language models to source code summarization. However, the authors acknowledge several caveats and limitations that warrant further consideration.
One key limitation is the diversity and complexity of the code samples used in the experiments. The researchers note that the performance of LLMs can vary significantly depending on factors such as the programming language, code structure, and the use of domain-specific terminology. While the dataset covers a range of scenarios, there may be additional challenges that arise when dealing with highly specialized or idiomatic code.
Additionally, the paper does not delve deeply into the potential biases or inconsistencies that may be present in the LLM-generated summaries. It would be valuable to explore how these models handle edge cases, ambiguities, or subtle nuances in the code, and whether their summaries accurately capture the intent and functionality of the source code.
Further research could also investigate the impact of different prompt engineering strategies, as the paper suggests that the quality of the summaries can be influenced by the way the LLMs are prompted. Exploring more advanced prompting techniques, as well as the development of specialized prompting frameworks, could lead to significant improvements in the performance of LLM-based code summarization.
Overall, this paper provides a solid foundation for understanding the current state of LLM-based source code summarization and highlights promising directions for future work in this field. As large language models continue to evolve, their ability to assist software engineers in comprehending complex codebases could become increasingly valuable.
Conclusion
This paper explores the promising potential of large language models (LLMs) for the task of source code summarization. The researchers conduct a comprehensive analysis of various LLM-based approaches, evaluating their performance on a diverse dataset of source code from different programming languages and domains.
The results demonstrate that LLMs can generate useful summaries of source code, but also reveal notable limitations and areas for improvement. The paper highlights the impact of factors such as code complexity, domain-specific terminology, and prompt engineering on the quality of the generated summaries.
Overall, this work provides valuable insights into the current state of LLM-based source code summarization and points to exciting opportunities for further research and development in this field. As LLMs continue to advance, they could become increasingly powerful tools for software engineers, helping them more efficiently navigate and understand complex codebases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Source Code Summarization in the Era of Large Language Models
Weisong Sun, Yun Miao, Yuekang Li, Hongyu Zhang, Chunrong Fang, Yi Liu, Gelei Deng, Yang Liu, Zhenyu Chen
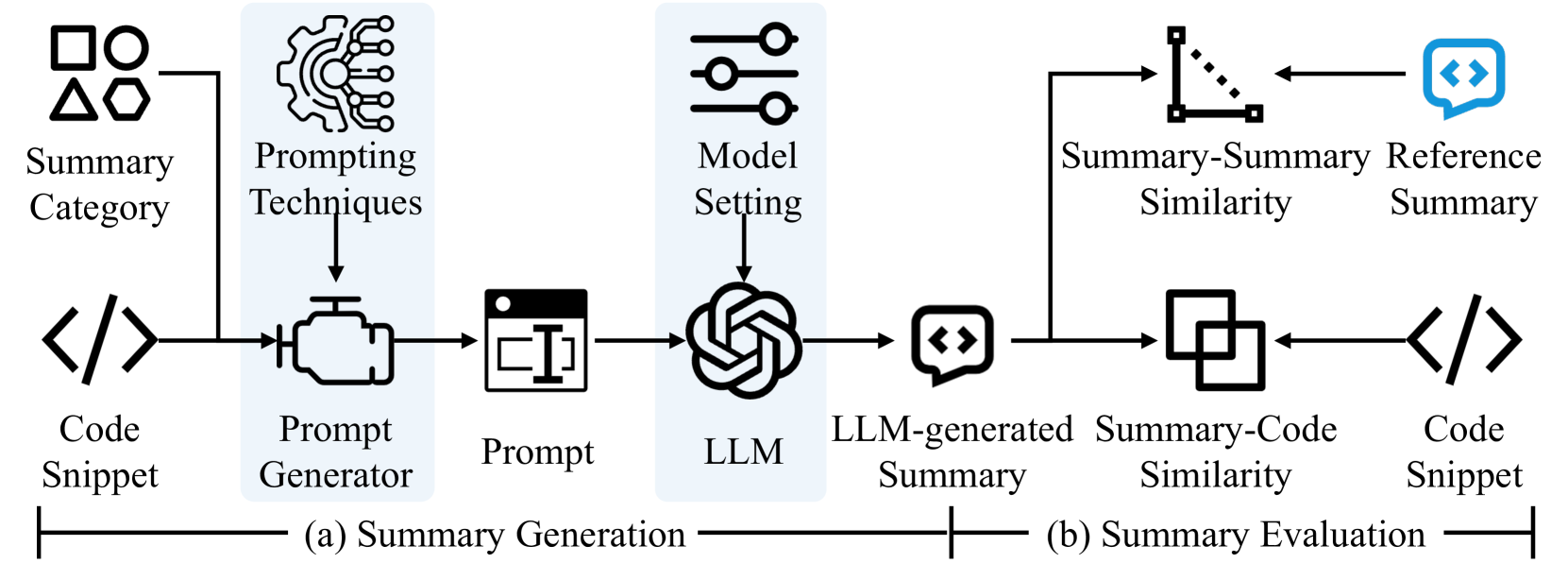
To support software developers in understanding and maintaining programs, various automatic (source) code summarization techniques have been proposed to generate a concise natural language summary (i.e., comment) for a given code snippet. Recently, the emergence of large language models (LLMs) has led to a great boost in the performance of code-related tasks. In this paper, we undertake a systematic and comprehensive study on code summarization in the era of LLMs, which covers multiple aspects involved in the workflow of LLM-based code summarization. Specifically, we begin by examining prevalent automated evaluation methods for assessing the quality of summaries generated by LLMs and find that the results of the GPT-4 evaluation method are most closely aligned with human evaluation. Then, we explore the effectiveness of five prompting techniques (zero-shot, few-shot, chain-of-thought, critique, and expert) in adapting LLMs to code summarization tasks. Contrary to expectations, advanced prompting techniques may not outperform simple zero-shot prompting. Next, we investigate the impact of LLMs' model settings (including top_p and temperature parameters) on the quality of generated summaries. We find the impact of the two parameters on summary quality varies by the base LLM and programming language, but their impacts are similar. Moreover, we canvass LLMs' abilities to summarize code snippets in distinct types of programming languages. The results reveal that LLMs perform suboptimally when summarizing code written in logic programming languages compared to other language types. Finally, we unexpectedly find that CodeLlama-Instruct with 7B parameters can outperform advanced GPT-4 in generating summaries describing code implementation details and asserting code properties. We hope that our findings can provide a comprehensive understanding of code summarization in the era of LLMs.
Read more7/12/2024

0
Large Language Models for Code Summarization
Bal'azs Szalontai, GergH{o} Szalay, Tam'as M'arton, Anna Sike, Bal'azs Pint'er, Tibor Gregorics
Recently, there has been increasing activity in using deep learning for software engineering, including tasks like code generation and summarization. In particular, the most recent coding Large Language Models seem to perform well on these problems. In this technical report, we aim to review how these models perform in code explanation/summarization, while also investigating their code generation capabilities (based on natural language descriptions).
Read more5/30/2024
0
Analyzing the Performance of Large Language Models on Code Summarization
Rajarshi Haldar, Julia Hockenmaier
Large language models (LLMs) such as Llama 2 perform very well on tasks that involve both natural language and source code, particularly code summarization and code generation. We show that for the task of code summarization, the performance of these models on individual examples often depends on the amount of (subword) token overlap between the code and the corresponding reference natural language descriptions in the dataset. This token overlap arises because the reference descriptions in standard datasets (corresponding to docstrings in large code bases) are often highly similar to the names of the functions they describe. We also show that this token overlap occurs largely in the function names of the code and compare the relative performance of these models after removing function names versus removing code structure. We also show that using multiple evaluation metrics like BLEU and BERTScore gives us very little additional insight since these metrics are highly correlated with each other.
Read more4/15/2024

0
A Survey on Large Language Models for Code Generation
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, Sunghun Kim
Large Language Models (LLMs) have garnered remarkable advancements across diverse code-related tasks, known as Code LLMs, particularly in code generation that generates source code with LLM from natural language descriptions. This burgeoning field has captured significant interest from both academic researchers and industry professionals due to its practical significance in software development, e.g., GitHub Copilot. Despite the active exploration of LLMs for a variety of code tasks, either from the perspective of natural language processing (NLP) or software engineering (SE) or both, there is a noticeable absence of a comprehensive and up-to-date literature review dedicated to LLM for code generation. In this survey, we aim to bridge this gap by providing a systematic literature review that serves as a valuable reference for researchers investigating the cutting-edge progress in LLMs for code generation. We introduce a taxonomy to categorize and discuss the recent developments in LLMs for code generation, covering aspects such as data curation, latest advances, performance evaluation, and real-world applications. In addition, we present a historical overview of the evolution of LLMs for code generation and offer an empirical comparison using the widely recognized HumanEval and MBPP benchmarks to highlight the progressive enhancements in LLM capabilities for code generation. We identify critical challenges and promising opportunities regarding the gap between academia and practical development. Furthermore, we have established a dedicated resource website (https://codellm.github.io) to continuously document and disseminate the most recent advances in the field.
Read more6/4/2024