live-portrait
Maintainer: okaris

16

| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | No Github link provided |
| Paper link | No paper link provided |
Create account to get full access
Model overview
The live-portrait model is an AI-powered portrait animation tool that can generate realistic and dynamic animations from a source image or video. Developed by Replicate creator okaris, this model builds upon similar work such as Efficient Portrait Animation with Stitching and Retargeting Control, live portrait with audio, and Portrait animation using a driving video source. The model aims to create lifelike animations that can be used for a variety of applications, from social media content to virtual avatars.
Model inputs and outputs
The live-portrait model takes in a source image or video, a driving video, and various configuration parameters to control the animation. The outputs are a series of images or a video that brings the source portrait to life, with the movement and expressions matched to the driving video.
Inputs
- Source Image: The source image to be animated
- Source Video: The source video to be animated
- Driving Video: The video that will drive the animation
- Scale, Vx Ratio, Vy Ratio, Flag Remap, Flag Do Crop, Flag Relative, Flag Crop Driving Video, Scale Crop Driving Video, Vx Ratio Crop Driving Video, Vy Ratio Crop Driving Video, Flag Video Editing Head Rotation, Driving Smooth Observation Variance: Various configuration parameters to control the animation
Outputs
- Output: A series of images or a video that animates the source portrait
Capabilities
The live-portrait model is capable of generating realistic and dynamic animations from a variety of input sources. By leveraging the driving video, the model can create animations that closely match the movements and expressions of the source portrait, resulting in a lifelike and engaging experience. The model's ability to control various parameters, such as cropping, scaling, and relative motion, allows for a high degree of customization and fine-tuning of the animation.
What can I use it for?
The live-portrait model can be used for a wide range of applications, from social media content creation to virtual avatars and virtual reality experiences. Content creators could use the model to generate animated portraits for their videos or social media posts, adding a unique and engaging element to their content. Developers could integrate the model into their applications to create virtual assistants or avatars with realistic facial expressions and movements. Businesses could also leverage the model to create personalized video content or virtual experiences for their customers.
Things to try
One interesting aspect of the live-portrait model is its ability to work with both source images and videos. This opens up a wide range of creative possibilities, as users could experiment with mixing and matching different source materials and driving videos to create unique and unexpected animations. Additionally, the model's configurable parameters allow for a high degree of control over the animation, enabling users to fine-tune the results to their specific needs or artistic vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models

live-portrait
5
The live-portrait model is a unique AI tool that can create dynamic, audio-driven portrait animations. It combines an input image and video to produce a captivating animated portrait that reacts to the accompanying audio. This model builds upon similar portrait animation models like live-portrait-fofr, livespeechportraits-yuanxunlu, and aniportrait-audio2vid-cjwbw, each with its own distinct capabilities. Model inputs and outputs The live-portrait model takes two inputs: an image and a video. The image serves as the base for the animated portrait, while the video provides the audio that drives the facial movements and expressions. The output is an array of image URIs representing the animated portrait sequence. Inputs Image**: An input image that forms the base of the animated portrait Video**: An input video that provides the audio to drive the facial animations Outputs An array of image URIs representing the animated portrait sequence Capabilities The live-portrait model can create compelling, real-time animations that seamlessly blend a static portrait with dynamic facial expressions and movements. This can be particularly useful for creating lively, engaging content for video, presentations, or other multimedia applications. What can I use it for? The live-portrait model could be used to bring portraits to life, adding a new level of dynamism and engagement to a variety of projects. For example, you could use it to create animated avatars for virtual events, generate personalized video messages, or add animated elements to presentations and videos. The model's ability to sync facial movements to audio also makes it a valuable tool for creating more expressive and lifelike digital characters. Things to try One interesting aspect of the live-portrait model is its potential to capture the nuances of human expression and movement. By experimenting with different input images and audio sources, you can explore how the model responds to various emotional tones, speech patterns, and physical gestures. This could lead to the creation of unique and captivating animated portraits that convey a wide range of human experiences.
Updated Invalid Date

live-portrait
6
The live-portrait model, created by maintainer mbukerepo, is an efficient portrait animation system that allows users to animate a portrait image using a driving video. The model builds upon previous work like LivePortrait, AniPortrait, and Live Speech Portraits, providing a simplified and optimized approach to portrait animation. Model inputs and outputs The live-portrait model takes two main inputs: an input portrait image and a driving video. The output is a generated animation of the portrait image following the motion and expression of the driving video. Inputs Input Image Path**: A portrait image to be animated Input Video Path**: A driving video that will control the animation Flag Do Crop Input**: A boolean flag to determine whether the input image should be cropped Flag Relative Input**: A boolean flag to control whether the input motion is relative Flag Pasteback**: A boolean flag to control whether the generated animation should be pasted back onto the input image Outputs Output**: The generated animation of the portrait image Capabilities The live-portrait model is capable of efficiently animating portrait images using a driving video. It can capture and transfer the motion and expressions from the driving video to the input portrait, resulting in a photorealistic talking head animation. The model uses techniques like stitching and retargeting control to ensure the generated animation is seamless and natural. What can I use it for? The live-portrait model can be used in a variety of applications, such as: Creating animated avatars or virtual characters for games, social media, or video conferencing Generating personalized video content by animating portraits of individuals Producing animated content for educational or informational videos Enhancing virtual reality experiences by adding photorealistic animated faces Things to try One interesting thing to try with the live-portrait model is to experiment with different types of driving videos, such as those with exaggerated expressions or unusual motion patterns. This can help push the limits of the model's capabilities and lead to more creative and expressive portrait animations. Additionally, you could try incorporating the model into larger projects or workflows, such as by using the generated animations as part of a larger multimedia presentation or interactive experience.
Updated Invalid Date
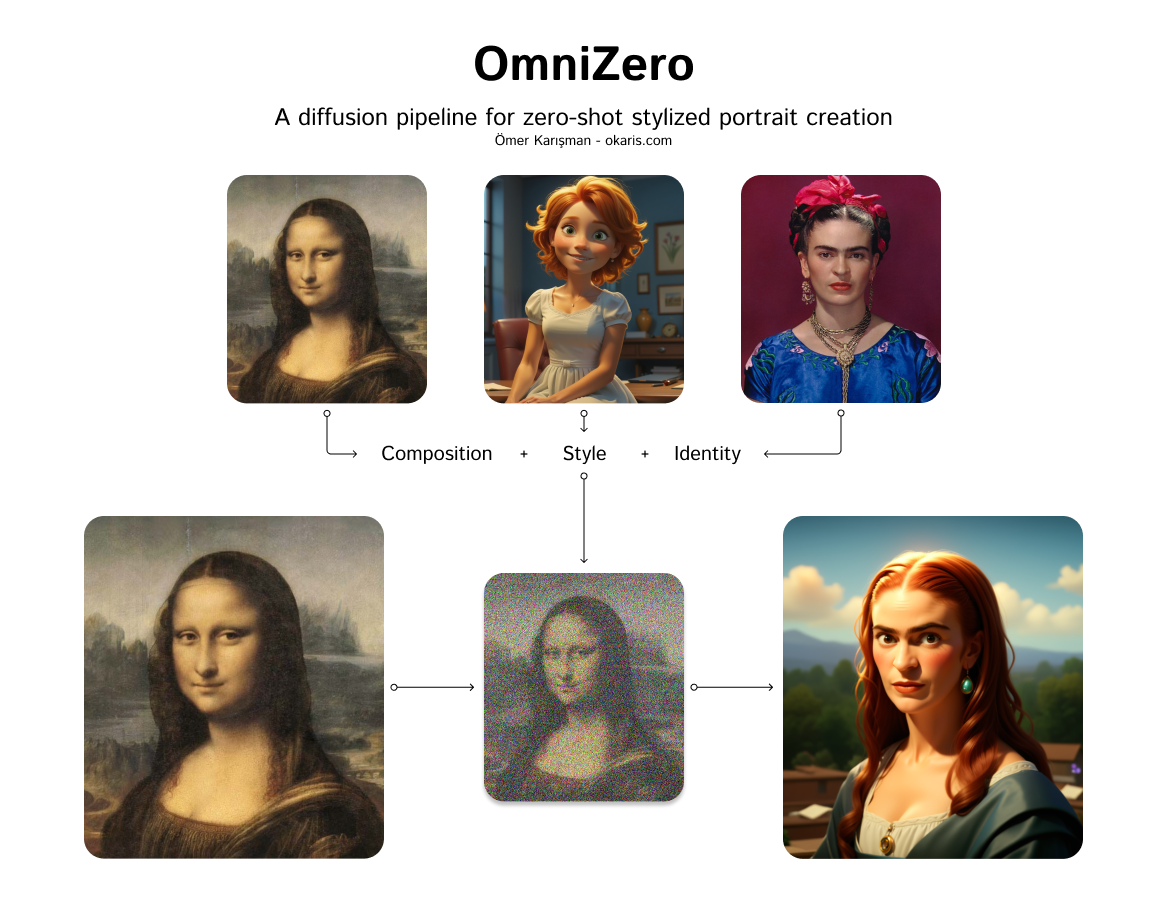
omni-zero
458
Omni-Zero is a diffusion pipeline model created by okaris that enables zero-shot stylized portrait creation. It leverages the power of diffusion models, similar to Stable Diffusion, to generate photo-realistic images from text prompts. However, Omni-Zero adds the ability to apply various styles and effects to the generated portraits, allowing for a high degree of customization and creativity. Model inputs and outputs Omni-Zero takes in a variety of inputs that allow for fine-tuned control over the generated portraits. These include a text prompt, a seed value for reproducibility, a guidance scale, and the number of steps and images to generate. Users can also provide optional input images, such as a base image, style image, identity image, and composition image, to further influence the output. Inputs Seed**: A random seed value for reproducibility Prompt**: The text prompt describing the desired portrait Negative Prompt**: Optional text to exclude from the generated image Number of Images**: The number of images to generate Number of Steps**: The number of steps to use in the diffusion process Guidance Scale**: The strength of the text guidance during the diffusion process Base Image**: An optional base image to use as a starting point Style Image**: An optional image to use as a style reference Identity Image**: An optional image to use as an identity reference Composition Image**: An optional image to use as a composition reference Depth Image**: An optional depth image to use for depth-aware generation Outputs An array of generated portrait images in the form of image URLs Capabilities Omni-Zero excels at generating highly stylized and personalized portraits from text prompts. It can capture a wide range of artistic styles, from photorealistic to more abstract and impressionistic renderings. The model's ability to incorporate various input images, such as style and identity references, allows for a high degree of customization and creative expression. What can I use it for? Omni-Zero can be a powerful tool for artists, designers, and content creators who want to quickly generate unique and visually striking portrait images. It could be used to create custom avatars, character designs, or even personalized art pieces. The model's versatility also makes it suitable for various applications, such as social media content, illustrations, and even product design. Things to try One interesting aspect of Omni-Zero is its ability to blend multiple styles and identities in a single generated portrait. By providing a diverse set of input images, users can explore the interplay of different visual elements and create truly unique and captivating portraits. Additionally, experimenting with the depth image and composition inputs can lead to some fascinating depth-aware and spatially-aware generations.
Updated Invalid Date

live-portrait
60
The live-portrait model is an efficient portrait animation system that uses a driving video source to animate a portrait. It is developed by the Replicate creator fofr, who has created similar models like video-morpher, frames-to-video, and toolkit. The live-portrait model is based on the research paper "LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control" and shares some similarities with other portrait animation models like aniportrait-vid2vid and livespeechportraits. Model inputs and outputs The live-portrait model takes a face image and a driving video as inputs, and generates an animated portrait that follows the movements and expressions of the driving video. The model also allows for various configuration parameters to control the output, such as the size, scaling, positioning, and retargeting of the animated portrait. Inputs Face Image**: An image containing the face to be animated Driving Video**: A video that will drive the animation of the portrait Live Portrait Dsize**: The size of the output image Live Portrait Scale**: The scaling factor for the face Video Frame Load Cap**: The maximum number of frames to load from the driving video Live Portrait Lip Zero**: Whether to enable lip zero Live Portrait Relative**: Whether to use relative positioning Live Portrait Vx Ratio**: The horizontal shift ratio Live Portrait Vy Ratio**: The vertical shift ratio Live Portrait Stitching**: Whether to enable stitching Video Select Every N Frames**: The frequency of frames to select from the driving video Live Portrait Eye Retargeting**: Whether to enable eye retargeting Live Portrait Lip Retargeting**: Whether to enable lip retargeting Live Portrait Lip Retargeting Multiplier**: The multiplier for lip retargeting Live Portrait Eyes Retargeting Multiplier**: The multiplier for eye retargeting Outputs An array of URIs representing the animated portrait frames Capabilities The live-portrait model can efficiently animate a portrait by using a driving video source. It supports various configuration options to control the output, such as the size, scaling, positioning, and retargeting of the animated portrait. The model can be useful for creating various types of animated content, such as video messages, social media posts, or even virtual characters. What can I use it for? The live-portrait model can be used to create engaging and personalized animated content. For example, you could use it to create custom video messages for your customers or clients, or to animate virtual characters for use in games, movies, or other interactive media. The model's ability to control the positioning and retargeting of the animated portrait could also make it useful for creating animated content for educational or training purposes, where the focus on the speaker's face is important. Things to try One interesting thing to try with the live-portrait model is to experiment with the various configuration options, such as the retargeting parameters, to see how they affect the output. You could also try using different types of driving videos, such as video of yourself speaking, to see how the model handles different types of facial movements and expressions. Additionally, you could try combining the live-portrait model with other AI models, such as speech-to-text or text-to-speech, to create more complex animated content.
Updated Invalid Date