speaker-diarization
Maintainer: meronym

42
| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | No paper link provided |
Create account to get full access
Model overview
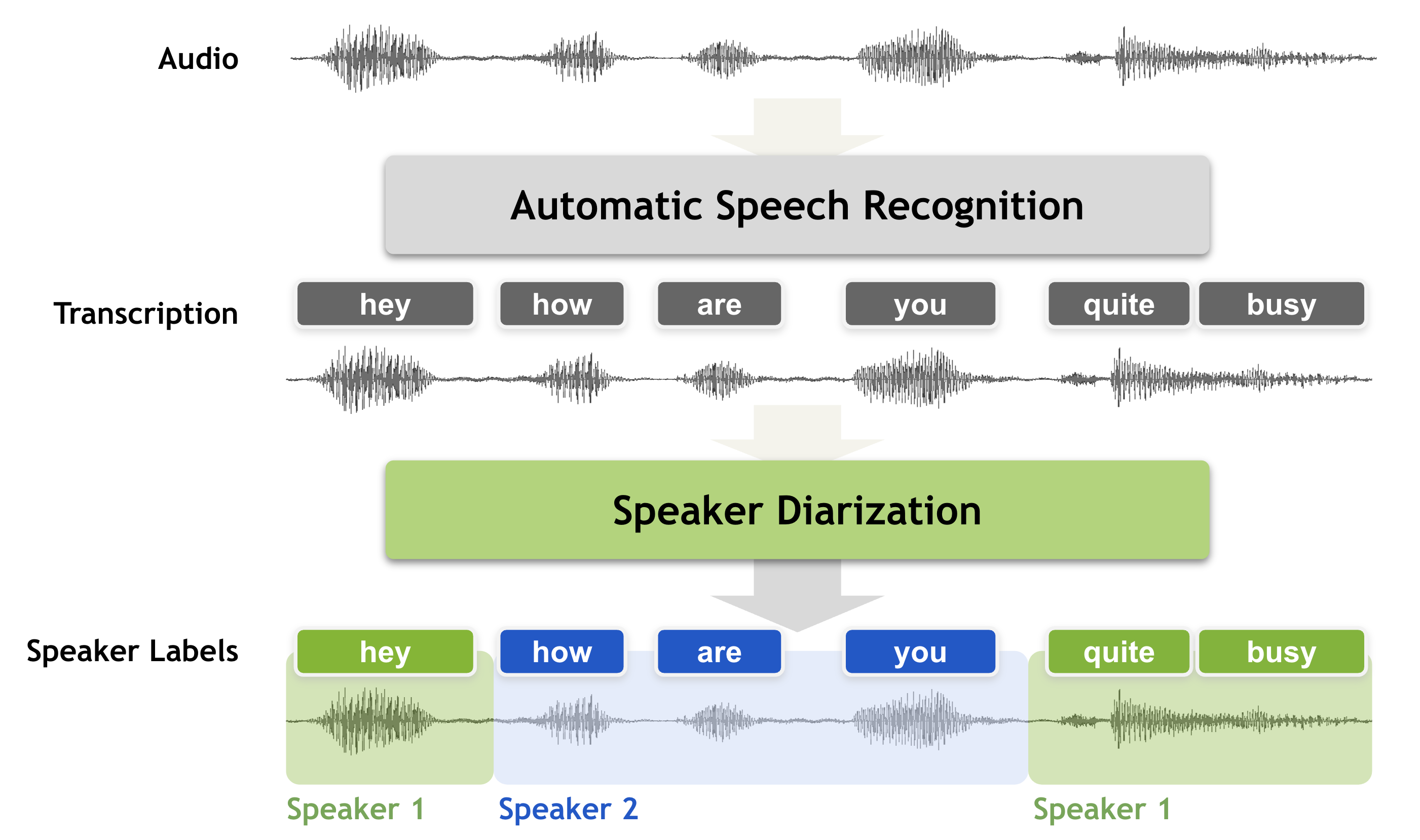
The speaker-diarization model from Replicate creator meronym is a tool that segments an audio recording based on who is speaking. It is built using the open-source [object Object] library, which provides a set of trainable end-to-end neural building blocks for speaker diarization.
This model is similar to other speaker diarization models available, such as speaker-diarization and whisper-diarization, which also leverage the pyannote.audio library. However, the speaker-diarization model from meronym specifically uses a pre-trained pipeline that combines speaker segmentation, embedding, and clustering to identify individual speakers within the audio.
Model inputs and outputs
Inputs
- audio: The audio file to be processed, in a supported format such as MP3, AAC, FLAC, OGG, OPUS, or WAV.
Outputs
- The model outputs a JSON file with the following structure:
segments: A list of diarization segments, each with a speaker label, start time, and end time.speakers: An object containing the number of detected speakers, their labels, and 192-dimensional speaker embedding vectors.
Capabilities
The speaker-diarization model is capable of automatically identifying individual speakers within an audio recording, even in cases where there is overlapping speech. It can handle a variety of audio formats and sample rates, and provides both segmentation information and speaker embeddings as output.
What can I use it for?
This model can be useful for a variety of applications, such as:
- Data Augmentation: The speaker diarization output can be used to enhance transcription and captioning tasks by providing speaker-level segmentation.
- Speaker Recognition: The speaker embeddings generated by the model can be used to match against a database of known speakers, enabling speaker identification and verification.
- Meeting and Interview Analysis: The speaker diarization output can be used to analyze meeting recordings or interviews, providing insights into speaker participation, turn-taking, and interaction patterns.
Things to try
One interesting aspect of the speaker-diarization model is its ability to handle overlapping speech. You could experiment with audio files that contain multiple speakers talking simultaneously, and observe how the model segments and labels the different speakers. Additionally, you could explore the use of the speaker embeddings for tasks like speaker clustering or identification, and see how the model's performance compares to other approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models
speaker-transcription
21
The speaker-transcription model is a powerful AI system that combines speaker diarization and speech transcription capabilities. It was developed by Meronym, a creator on the Replicate platform. This model builds upon two main components: the pyannote.audio speaker diarization pipeline and OpenAI's whisper model for general-purpose English speech transcription. The speaker-transcription model outperforms similar models like whisper-diarization and whisperx by providing more accurate speaker segmentation and identification, as well as high-quality transcription. It can be particularly useful for tasks that require both speaker information and verbatim transcripts, such as interview analysis, podcast processing, or meeting recordings. Model inputs and outputs The speaker-transcription model takes an audio file as input and can optionally accept a prompt string to guide the transcription. The model outputs a JSON file containing the transcribed segments, with each segment associated with a speaker label and timestamps. Inputs Audio**: An audio file in a supported format, such as MP3, AAC, FLAC, OGG, OPUS, or WAV. Prompt (optional)**: A text prompt that can be used to provide additional context for the transcription. Outputs JSON file**: A JSON file with the following structure: segments: A list of transcribed segments, each with a speaker label, start and stop timestamps, and the segment transcript. speakers: Information about the detected speakers, including the total count, labels for each speaker, and embeddings (a vector representation of each speaker's voice). Capabilities The speaker-transcription model excels at accurately identifying and labeling different speakers within an audio recording, while also providing high-quality transcripts of the spoken content. This makes it a valuable tool for a variety of applications, such as interview analysis, podcast processing, or meeting recordings. What can I use it for? The speaker-transcription model can be used for data augmentation and segmentation tasks, where the speaker information and timestamps can be used to improve the accuracy and effectiveness of transcription and captioning models. Additionally, the speaker embeddings generated by the model can be used for speaker recognition, allowing you to match voice profiles against a database of known speakers. Things to try One interesting aspect of the speaker-transcription model is the ability to use a prompt to guide the transcription. By providing additional context about the topic or subject matter, you can potentially improve the accuracy and relevance of the transcripts. Try experimenting with different prompts to see how they affect the output. Another useful feature is the generation of speaker embeddings, which can be used for speaker recognition and identification tasks. Consider exploring ways to leverage these embeddings, such as building a speaker verification system or clustering speakers in large audio datasets.
Updated Invalid Date
speaker-diarization
9
The speaker-diarization model is an AI-powered tool that can segment an audio recording based on who is speaking. It uses a pre-trained speaker diarization pipeline from the pyannote.audio package, which is an open-source toolkit for speaker diarization based on PyTorch. The model is capable of identifying individual speakers within an audio recording and providing information about the start and stop times of each speaker's segment, as well as speaker embeddings that can be used for speaker recognition. This model is similar to other audio-related models created by lucataco, such as whisperspeech-small, xtts-v2, and magnet. Model inputs and outputs The speaker-diarization model takes a single input: an audio file in a variety of supported formats, including MP3, AAC, FLAC, OGG, OPUS, and WAV. The model processes the audio and outputs a JSON file containing information about the identified speakers, including the start and stop times of each speaker's segment, the number of detected speakers, and speaker embeddings that can be used for speaker recognition. Inputs Audio**: An audio file in a supported format (e.g., MP3, AAC, FLAC, OGG, OPUS, WAV) Outputs Output.json**: A JSON file containing the following information: segments: A list of objects, each representing a detected speaker segment, with the speaker label, start time, and end time speakers: An object containing the number of detected speakers, their labels, and the speaker embeddings for each speaker Capabilities The speaker-diarization model can effectively segment an audio recording and identify the individual speakers. This can be useful for a variety of applications, such as transcription and captioning tasks, as well as speaker recognition. The model's ability to generate speaker embeddings can be particularly valuable for building speaker recognition systems. What can I use it for? The speaker-diarization model can be used for a variety of data augmentation and segmentation tasks, such as processing interview recordings, podcast episodes, or meeting recordings. The speaker segmentation and embedding information provided by the model can be used to enhance transcription and captioning tasks, as well as to implement speaker recognition systems that can identify specific speakers within an audio recording. Things to try One interesting thing to try with the speaker-diarization model is to experiment with the speaker embeddings it generates. These embeddings can be used to build speaker recognition systems that can identify specific speakers within an audio recording. You could try matching the speaker embeddings against a database of known speakers, or using them as input features for a machine learning model that can classify speakers. Another thing to try is to use the speaker segmentation information provided by the model to enhance transcription and captioning tasks. By knowing where each speaker's segments begin and end, you can potentially improve the accuracy of the transcription or captioning, especially in cases where there is overlapping speech.
Updated Invalid Date

whisper-diarization
603
whisper-diarization is a fast audio transcription model that combines the powerful Whisper Large v3 model with speaker diarization from the Pyannote audio library. This model provides accurate transcription with word-level timestamps and the ability to identify different speakers in the audio. Similar models like whisperx and voicecraft also offer advanced speech-to-text capabilities, but whisper-diarization stands out with its speed and ease of use. Model inputs and outputs whisper-diarization takes in audio data in various formats, including a direct file URL, a Base64 encoded audio file, or a local audio file path. Users can also provide a prompt containing relevant vocabulary to improve transcription accuracy. The model outputs a list of speaker segments with start and end times, the detected number of speakers, and the language of the spoken words. Inputs file_string: Base64 encoded audio file file_url: Direct URL to an audio file file: Local audio file path prompt: Vocabulary to improve transcription accuracy group_segments: Option to group short segments from the same speaker num_speakers: Specify the number of speakers (leave empty to autodetect) language: Language of the spoken words (leave empty to autodetect) offset_seconds: Offset in seconds for chunked inputs Outputs segments: List of speaker segments with start/end times, average log probability, and word-level probabilities num_speakers: Number of detected speakers language: Detected language of the spoken words Capabilities whisper-diarization excels at fast and accurate audio transcription, even in noisy or multilingual environments. The model's ability to identify different speakers and provide word-level timestamps makes it a powerful tool for a variety of applications, from meeting recordings to podcast production. What can I use it for? whisper-diarization can be used in many industries and applications that require accurate speech-to-text conversion and speaker identification. Some potential use cases include: Meeting and interview transcription**: Quickly generate transcripts with speaker attribution for remote or in-person meetings, interviews, and conferences. Podcast and audio production**: Streamline the podcast production workflow by automatically generating transcripts and identifying different speakers. Accessibility and subtitling**: Provide accurate, time-stamped captions for videos and audio content to improve accessibility. Market research and customer service**: Analyze audio recordings of customer calls or focus groups to extract insights and improve product or service offerings. Things to try One interesting aspect of whisper-diarization is its ability to handle multiple speakers and provide word-level timestamps. This can be particularly useful for applications that require speaker segmentation, such as conversation analysis or audio captioning. You could experiment with the group_segments and num_speakers parameters to see how they affect the model's performance on different types of audio content. Another area to explore is the use of the prompt parameter to improve transcription accuracy. By providing relevant vocabulary, acronyms, or proper names, you can potentially boost the model's performance on domain-specific content, such as technical jargon or industry-specific terminology.
Updated Invalid Date
sabuhi-model
25
The sabuhi-model is an AI model developed by sabuhigr that builds upon the popular Whisper AI model. This model incorporates channel separation and speaker diarization, allowing it to transcribe audio with multiple speakers and distinguish between them. The sabuhi-model can be seen as an extension of similar Whisper-based models like whisper-large-v3, whisper-subtitles, and the original whisper model. It offers additional capabilities for handling multi-speaker audio, making it a useful tool for transcribing interviews, meetings, and other scenarios with multiple participants. Model inputs and outputs The sabuhi-model takes in an audio file, along with several optional parameters to customize the transcription process. These include the choice of Whisper model, a Hugging Face token for speaker diarization, language settings, and various decoding options. Inputs audio**: The audio file to be transcribed model**: The Whisper model to use, with "large-v2" as the default hf_token**: Your Hugging Face token for speaker diarization language**: The language spoken in the audio (can be left as "None" for language detection) translate**: Whether to translate the transcription to English temperature**: The temperature to use for sampling max_speakers**: The maximum number of speakers to detect (default is 1) min_speakers**: The minimum number of speakers to detect (default is 1) transcription**: The format for the transcription (e.g., "plain text") initial_prompt**: Optional text to provide as a prompt for the first window suppress_tokens**: Comma-separated list of token IDs to suppress during sampling logprob_threshold**: The average log probability threshold for considering the decoding as failed no_speech_threshold**: The probability threshold for considering a segment as silence condition_on_previous_text**: Whether to provide the previous output as a prompt for the next window compression_ratio_threshold**: The gzip compression ratio threshold for considering the decoding as failed temperature_increment_on_fallback**: The temperature increment to use when falling back due to threshold issues Outputs The transcribed text, with speaker diarization and other formatting options as specified in the inputs Capabilities The sabuhi-model inherits the core speech recognition capabilities of the Whisper model, but also adds the ability to separate and identify multiple speakers within the audio. This makes it a useful tool for transcribing meetings, interviews, and other scenarios where multiple people are speaking. What can I use it for? The sabuhi-model can be used for a variety of applications that involve transcribing audio with multiple speakers, such as: Generating transcripts for interviews, meetings, or conference calls Creating subtitles or captions for videos with multiple speakers Improving the accessibility of audio-based content by providing text-based alternatives Enabling better search and indexing of audio-based content by generating transcripts Companies working on voice assistants, video conferencing tools, or media production workflows may find the sabuhi-model particularly useful for their needs. Things to try One interesting aspect of the sabuhi-model is its ability to handle audio with multiple speakers and identify who is speaking at any given time. This could be particularly useful for analyzing the dynamics of a conversation, tracking who speaks the most, or identifying the main speakers in a meeting or interview. Additionally, the model's various decoding options, such as the ability to suppress certain tokens or adjust the temperature, provide opportunities to experiment and fine-tune the transcription output to better suit specific use cases or preferences.
Updated Invalid Date