whisperspeech-small
Maintainer: lucataco

1

| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | View on Arxiv |
Create account to get full access
Model Overview
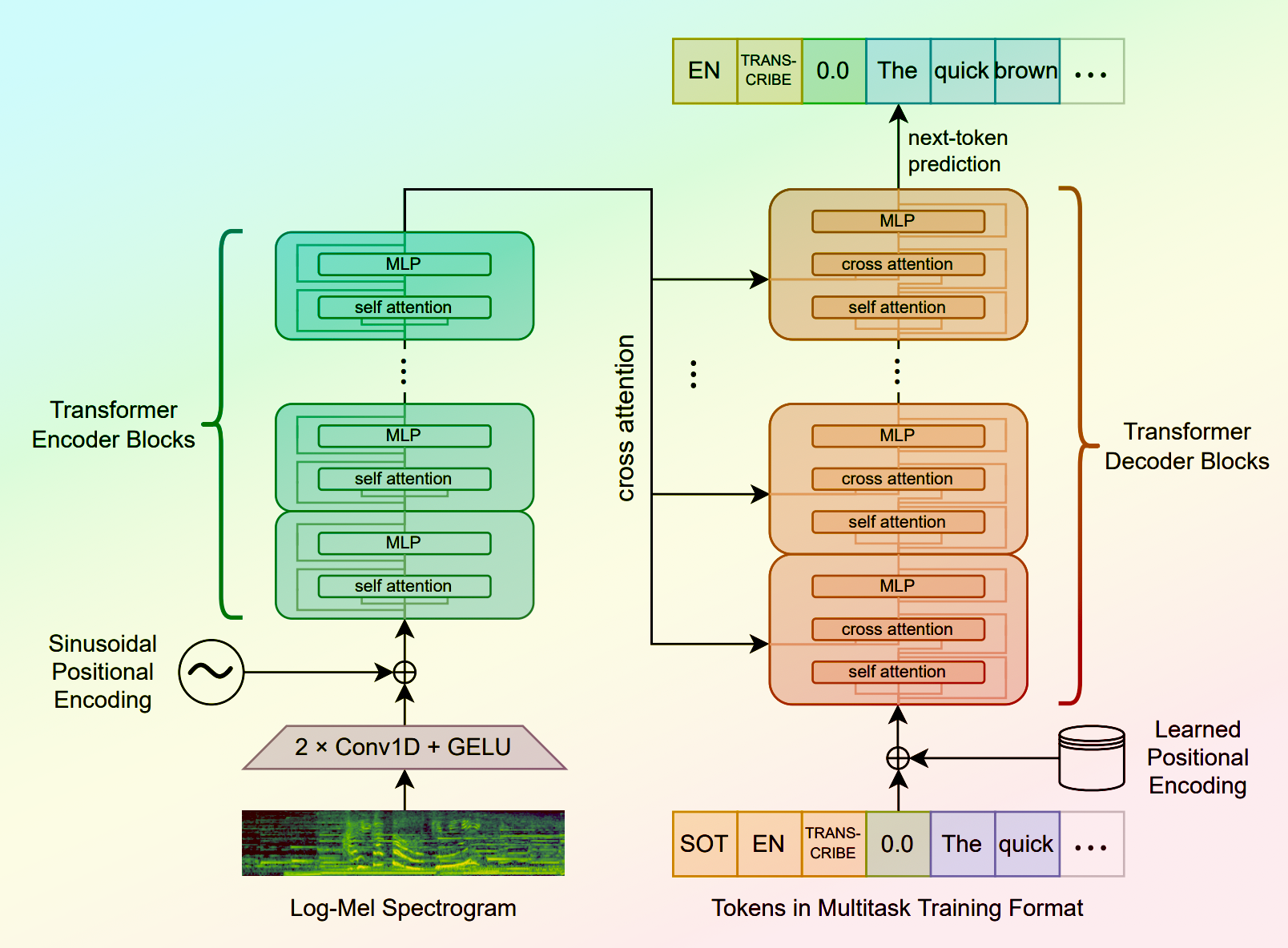
whisperspeech-small is an open-source text-to-speech system built by inverting the Whisper speech recognition model. It was developed by lucataco, a contributor at Replicate. This model can be used to generate audio from text, allowing users to create their own text-to-speech applications.
whisperspeech-small is similar to other open-source text-to-speech models like whisper-diarization, whisperx, and voicecraft, which leverage the capabilities of the Whisper speech recognition model in different ways.
Model Inputs and Outputs
whisperspeech-small takes a text prompt as input and generates an audio file as output. The model can handle various languages, and users can optionally provide a speaker audio file for zero-shot voice cloning.
Inputs
- Prompt: The text to be synthesized into speech
- Speaker: URL of an audio file for zero-shot voice cloning (optional)
- Language: The language of the text to be synthesized
Outputs
- Audio File: The generated speech audio file
Capabilities
whisperspeech-small can generate high-quality speech audio from text in a variety of languages. The model uses the Whisper speech recognition architecture to generate the audio, which results in natural-sounding speech. The zero-shot voice cloning feature also allows users to customize the voice used for the synthesized speech.
What Can I Use It For?
whisperspeech-small can be used to create text-to-speech applications, such as audiobook narration, language learning tools, or accessibility features for websites and applications. The model's ability to generate speech in multiple languages makes it useful for international or multilingual projects. Additionally, the zero-shot voice cloning feature allows for more personalized or branded text-to-speech outputs.
Things to Try
One interesting thing to try with whisperspeech-small is using the zero-shot voice cloning feature to generate speech that matches the voice of a specific person or character. This could be useful for creating audiobooks, podcasts, or interactive voice experiences. Another idea is to experiment with different text prompts and language settings to see how the model handles a variety of input content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models
whisper
33.7K
Whisper is a general-purpose speech recognition model developed by OpenAI. It is capable of converting speech in audio to text, with the ability to translate the text to English if desired. Whisper is based on a large Transformer model trained on a diverse dataset of multilingual and multitask speech recognition data. This allows the model to handle a wide range of accents, background noises, and languages. Similar models like whisper-large-v3, incredibly-fast-whisper, and whisper-diarization offer various optimizations and additional features built on top of the core Whisper model. Model inputs and outputs Whisper takes an audio file as input and outputs a text transcription. The model can also translate the transcription to English if desired. The input audio can be in various formats, and the model supports a range of parameters to fine-tune the transcription, such as temperature, patience, and language. Inputs Audio**: The audio file to be transcribed Model**: The specific version of the Whisper model to use, currently only large-v3 is supported Language**: The language spoken in the audio, or None to perform language detection Translate**: A boolean flag to translate the transcription to English Transcription**: The format for the transcription output, such as "plain text" Initial Prompt**: An optional initial text prompt to provide to the model Suppress Tokens**: A list of token IDs to suppress during sampling Logprob Threshold**: The minimum average log probability threshold for a successful transcription No Speech Threshold**: The threshold for considering a segment as silence Condition on Previous Text**: Whether to provide the previous output as a prompt for the next window Compression Ratio Threshold**: The maximum compression ratio threshold for a successful transcription Temperature Increment on Fallback**: The temperature increase when the decoding fails to meet the specified thresholds Outputs Transcription**: The text transcription of the input audio Language**: The detected language of the audio (if language input is None) Tokens**: The token IDs corresponding to the transcription Timestamp**: The start and end timestamps for each word in the transcription Confidence**: The confidence score for each word in the transcription Capabilities Whisper is a powerful speech recognition model that can handle a wide range of accents, background noises, and languages. The model is capable of accurately transcribing audio and optionally translating the transcription to English. This makes Whisper useful for a variety of applications, such as real-time captioning, meeting transcription, and audio-to-text conversion. What can I use it for? Whisper can be used in various applications that require speech-to-text conversion, such as: Captioning and Subtitling**: Automatically generate captions or subtitles for videos, improving accessibility for viewers. Meeting Transcription**: Transcribe audio recordings of meetings, interviews, or conferences for easy review and sharing. Podcast Transcription**: Convert audio podcasts to text, making the content more searchable and accessible. Language Translation**: Transcribe audio in one language and translate the text to another, enabling cross-language communication. Voice Interfaces**: Integrate Whisper into voice-controlled applications, such as virtual assistants or smart home devices. Things to try One interesting aspect of Whisper is its ability to handle a wide range of languages and accents. You can experiment with the model's performance on audio samples in different languages or with various background noises to see how it handles different real-world scenarios. Additionally, you can explore the impact of the different input parameters, such as temperature, patience, and language detection, on the transcription quality and accuracy.
Updated Invalid Date

xtts-v2
327
The xtts-v2 model is a multilingual text-to-speech voice cloning system developed by lucataco, the maintainer of this Cog implementation. This model is part of the Coqui TTS project, an open-source text-to-speech library. The xtts-v2 model is similar to other text-to-speech models like whisperspeech-small, styletts2, and qwen1.5-110b, which also generate speech from text. Model inputs and outputs The xtts-v2 model takes three main inputs: text to synthesize, a speaker audio file, and the output language. It then produces a synthesized audio file of the input text spoken in the voice of the provided speaker. Inputs Text**: The text to be synthesized Speaker**: The original speaker audio file (wav, mp3, m4a, ogg, or flv) Language**: The output language for the synthesized speech Outputs Output**: The synthesized audio file Capabilities The xtts-v2 model can generate high-quality multilingual text-to-speech audio by cloning the voice of a provided speaker. This can be useful for a variety of applications, such as creating personalized audio content, improving accessibility, or enhancing virtual assistants. What can I use it for? The xtts-v2 model can be used to create personalized audio content, such as audiobooks, podcasts, or video narrations. It could also be used to improve accessibility by generating audio versions of written content for users with visual impairments or other disabilities. Additionally, the model could be integrated into virtual assistants or chatbots to provide a more natural, human-like voice interface. Things to try One interesting thing to try with the xtts-v2 model is to experiment with different speaker audio files to see how the synthesized voice changes. You could also try using the model to generate audio in various languages and compare the results. Additionally, you could explore ways to integrate the model into your own applications or projects to enhance the user experience.
Updated Invalid Date
↗️
whisper
12
Whisper is a state-of-the-art speech recognition model developed by OpenAI. It is capable of transcribing audio into text with high accuracy, making it a valuable tool for a variety of applications. The model is implemented as a Cog model by the maintainer soykertje, allowing it to be easily integrated into various projects. Similar models like Whisper, Whisper Diarization, Whisper Large v3, WhisperSpeech Small, and WhisperX Spanish offer different variations and capabilities, catering to diverse speech recognition needs. Model inputs and outputs The Whisper model takes an audio file as input and generates a text transcription of the speech. The model also supports additional options, such as language specification, translation, and adjusting parameters like temperature and patience for the decoding process. Inputs Audio**: The audio file to be transcribed Model**: The specific Whisper model to use Language**: The language spoken in the audio Translate**: Whether to translate the text to English Transcription**: The format for the transcription (e.g., plain text) Temperature**: The temperature to use for sampling Patience**: The patience value to use in beam decoding Suppress Tokens**: A comma-separated list of token IDs to suppress during sampling Word Timestamps**: Whether to include word-level timestamps in the transcription Logprob Threshold**: The threshold for the average log probability to consider the decoding as successful No Speech Threshold**: The threshold for the probability of the token to consider the segment as silence Condition On Previous Text**: Whether to provide the previous output as a prompt for the next window Compression Ratio Threshold**: The threshold for the gzip compression ratio to consider the decoding as successful Temperature Increment On Fallback**: The temperature increase when falling back due to the above thresholds Outputs The transcribed text, with optional formatting and additional information such as word-level timestamps. Capabilities Whisper is a powerful speech recognition model that can accurately transcribe a wide range of audio content, including interviews, lectures, and spontaneous conversations. The model's ability to handle various accents, background noise, and speaker variations makes it a versatile tool for a variety of applications. What can I use it for? The Whisper model can be utilized in a range of applications, such as: Automated transcription of audio recordings for content creators, journalists, or researchers Real-time captioning for video conferencing or live events Voice-to-text conversion for accessibility purposes or hands-free interaction Language translation services, where the transcribed text can be further translated Developing voice-controlled interfaces or intelligent assistants Things to try Experimenting with the various input parameters of the Whisper model can help fine-tune the transcription quality for specific use cases. For example, adjusting the temperature and patience values can influence the model's sampling behavior, leading to more fluent or more conservative transcriptions. Additionally, leveraging the word-level timestamps can enable synchronized subtitles or captions in multimedia applications.
Updated Invalid Date

whisper-large-v3
3
The whisper-large-v3 model is a general-purpose speech recognition model developed by OpenAI. It is a large Transformer-based model trained on a diverse dataset of audio data, allowing it to perform multilingual speech recognition, speech translation, and language identification. The model is highly capable and can transcribe speech across a wide range of languages, although its performance varies based on the specific language. Similar models like incredibly-fast-whisper, whisper-diarization, and whisperx-a40-large offer various optimizations and additional features built on top of the base whisper-large-v3 model. Model inputs and outputs The whisper-large-v3 model takes in audio files and can perform speech recognition, transcription, and translation tasks. It supports a wide range of input audio formats, including common formats like FLAC, MP3, and WAV. The model can identify the source language of the audio and optionally translate the transcribed text into English. Inputs Filepath**: Path to the audio file to transcribe Language**: The source language of the audio, if known (e.g., "English", "French") Translate**: Whether to translate the transcribed text to English Outputs The transcribed text from the input audio file Capabilities The whisper-large-v3 model is a highly capable speech recognition model that can handle a diverse range of audio data. It demonstrates strong performance across many languages, with the ability to identify the source language and optionally translate the transcribed text to English. The model can also perform tasks like speaker diarization and generating word-level timestamps, as showcased by similar models like whisper-diarization and whisperx-a40-large. What can I use it for? The whisper-large-v3 model can be used for a variety of applications that involve transcribing speech, such as live captioning, audio-to-text conversion, and language learning. It can be particularly useful for transcribing multilingual audio, as it can identify the source language and provide accurate transcriptions. Additionally, the model's ability to translate the transcribed text to English opens up opportunities for cross-lingual communication and accessibility. Things to try One interesting aspect of the whisper-large-v3 model is its ability to handle a wide range of audio data, from high-quality studio recordings to low-quality field recordings. You can experiment with different types of audio input and observe how the model's performance varies. Additionally, you can try using the model's language identification capabilities to transcribe audio in unfamiliar languages and explore its translation functionality to bridge language barriers.
Updated Invalid Date