zero123plusplus
Maintainer: jd7h

8

| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | View on Arxiv |
Create account to get full access
Model overview
zero123plusplus is a novel AI model developed by jd7h that can turn a single input image into a set of consistent multi-view images. Unlike traditional 3D reconstruction methods, zero123plusplus is able to generate plausible views of an object from different angles starting from a single 2D image. This capability is achieved through the use of a diffusion-based approach, which allows the model to learn the underlying 3D structure of the input image. zero123plusplus builds upon prior work like One-2-3-45 and Zero123, further advancing the state-of-the-art in single-image 3D reconstruction.
Model inputs and outputs
zero123plusplus takes a single input image and generates a set of multi-view images from different 3D angles. The input image should be square-shaped and have a resolution of at least 320x320 pixels. The model can optionally remove the background of the input image as a post-processing step. Additionally, the user can choose to return the intermediate images generated during the diffusion process, providing a glimpse into the model's internal workings.
Inputs
- Image: The input image, which should be square-shaped and at least 320x320 pixels in resolution.
- Remove Background: A flag to indicate whether the background of the input image should be removed.
- Return Intermediate Images: A flag to return the intermediate images generated during the diffusion process, in addition to the final output.
Outputs
- Multi-view Images: A set of images depicting the input object from different 3D angles.
Capabilities
zero123plusplus demonstrates impressive capabilities in generating consistent multi-view images from a single input. The model is able to capture the underlying 3D structure of the input, allowing it to produce plausible views from various angles. This capability can be particularly useful for applications such as 3D visualization, virtual prototyping, and animation. The model's ability to work with a wide range of object types, from simple shapes to complex real-world scenes, further enhances its versatility.
What can I use it for?
zero123plusplus can be a valuable tool for a variety of applications. In the field of visual design and content creation, the model can be used to generate 3D-like assets from 2D images, enabling designers to quickly explore different perspectives and create more immersive visualizations. Similarly, the model's ability to generate multi-view images can be leveraged in virtual and augmented reality applications, where users can interact with objects from different angles.
Beyond creative applications, zero123plusplus can also find use in technical domains such as product design, where it can assist in virtual prototyping and simulation. The model's outputs can be integrated into CAD software or used for mechanical engineering purposes, helping to streamline the design process.
Things to try
One interesting aspect of zero123plusplus is its ability to generate intermediate images during the diffusion process. By examining these intermediate outputs, users can gain insights into the model's internal workings and the gradual transformation of the input image into the final multi-view result. Experimenting with different input images, adjusting the diffusion steps, and observing the changes in the intermediate outputs can provide valuable learning opportunities and a deeper understanding of how the model operates.
Another interesting avenue to explore is the integration of zero123plusplus with other AI models, such as depth estimation or object segmentation tools. By combining the multi-view generation capabilities of zero123plusplus with additional context information, users can unlock new possibilities for 3D scene understanding and reconstruction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models

pix2pix-zero
5
pix2pix-zero is a diffusion-based image-to-image model developed by researcher cjwbw that enables zero-shot image translation. Unlike traditional image-to-image translation models that require fine-tuning for each task, pix2pix-zero can directly use a pre-trained Stable Diffusion model to edit real and synthetic images while preserving the input image's structure. This approach is training-free and prompt-free, removing the need for manual text prompting or costly fine-tuning. The model is similar to other works such as pix2struct and daclip-uir in its focus on leveraging pre-trained vision-language models for efficient image editing and manipulation. However, pix2pix-zero stands out by enabling a wide range of zero-shot editing capabilities without requiring any text input or model fine-tuning. Model inputs and outputs pix2pix-zero takes an input image and a specified editing task (e.g., "cat to dog") and outputs the edited image. The model does not require any text prompts or fine-tuning for the specific task, making it a versatile and efficient tool for image-to-image translation. Inputs Image**: The input image to be edited Task**: The desired editing direction, such as "cat to dog" or "zebra to horse" Xa Guidance**: A parameter that controls the amount of cross-attention guidance applied during the editing process Use Float 16**: A flag to enable the use of half-precision (float16) computation for reduced VRAM requirements Num Inference Steps**: The number of denoising steps to perform during the editing process Negative Guidance Scale**: A parameter that controls the influence of the negative guidance during the editing process Outputs Edited Image**: The output image with the specified editing applied, while preserving the structure of the input image Capabilities pix2pix-zero demonstrates impressive zero-shot image-to-image translation capabilities, allowing users to apply a wide range of edits to both real and synthetic images without the need for manual text prompting or costly fine-tuning. The model can seamlessly translate between various visual concepts, such as "cat to dog", "zebra to horse", and "tree to fall", while maintaining the overall structure and composition of the input image. What can I use it for? The pix2pix-zero model can be a powerful tool for a variety of image editing and manipulation tasks. Some potential use cases include: Creative photo editing**: Quickly apply creative edits to existing photos, such as transforming a cat into a dog or a zebra into a horse, without the need for manual editing. Data augmentation**: Generate diverse synthetic datasets for machine learning tasks by applying various zero-shot transformations to existing images. Accessibility and inclusivity**: Assist users with visual impairments by enabling zero-shot edits that can make images more accessible, such as transforming images of cats to dogs for users who prefer canines. Prototyping and ideation**: Rapidly explore different design concepts or product ideas by applying zero-shot edits to existing images or synthetic assets. Things to try One interesting aspect of pix2pix-zero is its ability to preserve the structure and composition of the input image while applying the desired edit. This can be particularly useful when working with real-world photographs, where maintaining the overall integrity of the image is crucial. You can experiment with adjusting the xa_guidance parameter to find the right balance between preserving the input structure and achieving the desired editing outcome. Increasing the xa_guidance value can help maintain more of the input image's structure, while decreasing it can result in more dramatic transformations. Additionally, the model's versatility allows you to explore a wide range of editing directions beyond the examples provided. Try experimenting with different combinations of source and target concepts, such as "tree to flower" or "car to boat", to see the model's capabilities in action.
Updated Invalid Date

wonder3d
2
The wonder3d model, developed by Replicate creator adirik, is a powerful AI model that can generate 3D assets from a single input image. This model uses a multi-view diffusion approach to create detailed 3D representations of objects, buildings, or scenes in just a few minutes. It is similar to other 3D generation models like DreamGaussian and Face-to-Many, which can also convert 2D images into 3D content. Model inputs and outputs The wonder3d model takes a single image as input and generates a 3D asset as output. Users can also specify the number of steps for the diffusion process and whether to remove the image background. Inputs Image**: The input image to be converted to 3D Num Steps**: The number of iterations for the diffusion process (default is 3000, range is 100-10000) Remove Bg**: Whether to remove the image background (default is true) Random Seed**: An optional random seed for reproducibility Outputs Output**: A 3D asset generated from the input image Capabilities The wonder3d model is capable of generating high-quality 3D assets from a wide variety of input images, including objects, buildings, and scenes. The model can capture intricate details and textures, resulting in realistic 3D representations. It is particularly useful for applications such as 3D modeling, virtual reality, and game development. What can I use it for? The wonder3d model can be used for a variety of applications, such as creating 3D assets for use in games, virtual reality experiences, architectural visualizations, or product design. The model's ability to generate 3D content from a single image can streamline the content creation process and make 3D modeling more accessible to a wider audience. Companies in industries like gaming, architecture, and e-commerce may find this model particularly useful for rapidly generating 3D assets. Things to try Some interesting things to try with the wonder3d model include experimenting with different input images, adjusting the number of diffusion steps, and testing the background removal feature. You could also try combining the 3D assets generated by wonder3d with other AI models, such as StyleMC or GFPGAN, to create unique and compelling visual effects.
Updated Invalid Date
omni-zero
458
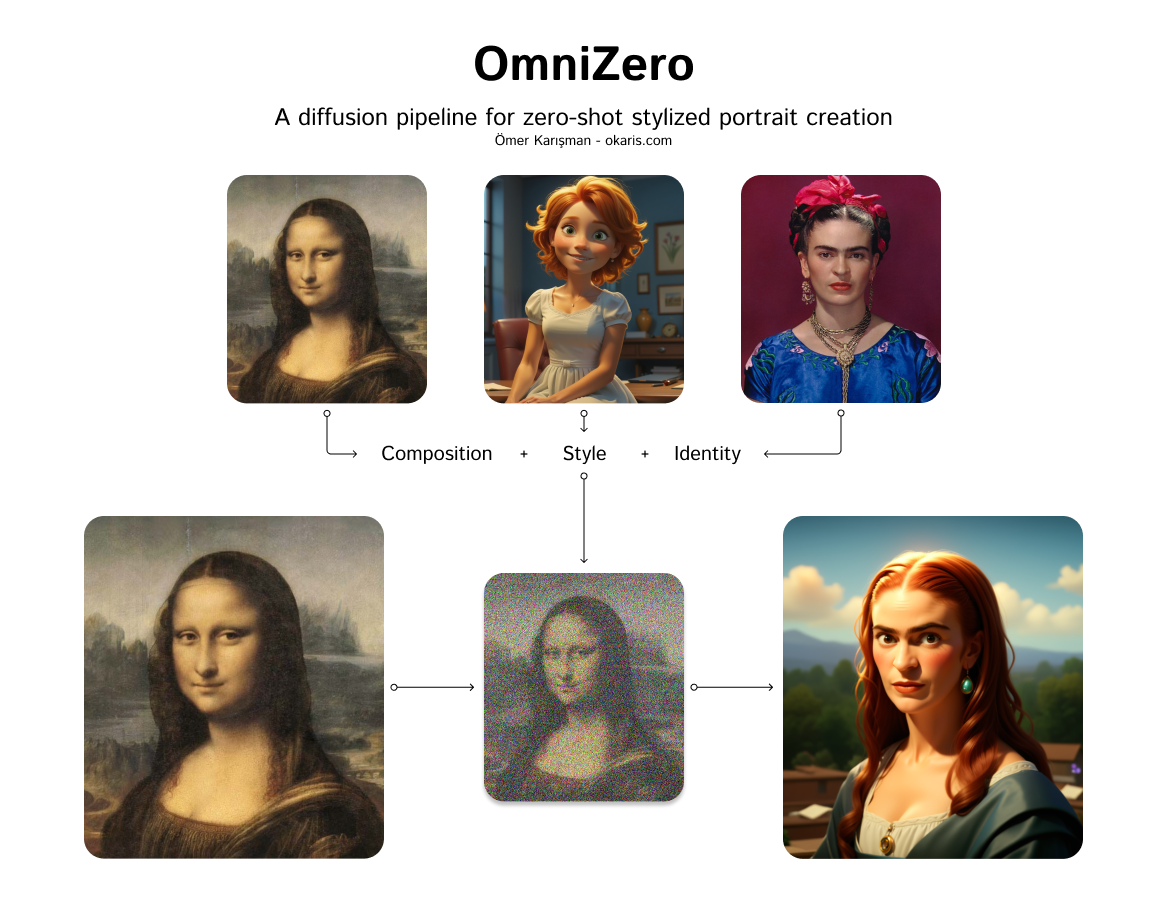
Omni-Zero is a diffusion pipeline model created by okaris that enables zero-shot stylized portrait creation. It leverages the power of diffusion models, similar to Stable Diffusion, to generate photo-realistic images from text prompts. However, Omni-Zero adds the ability to apply various styles and effects to the generated portraits, allowing for a high degree of customization and creativity. Model inputs and outputs Omni-Zero takes in a variety of inputs that allow for fine-tuned control over the generated portraits. These include a text prompt, a seed value for reproducibility, a guidance scale, and the number of steps and images to generate. Users can also provide optional input images, such as a base image, style image, identity image, and composition image, to further influence the output. Inputs Seed**: A random seed value for reproducibility Prompt**: The text prompt describing the desired portrait Negative Prompt**: Optional text to exclude from the generated image Number of Images**: The number of images to generate Number of Steps**: The number of steps to use in the diffusion process Guidance Scale**: The strength of the text guidance during the diffusion process Base Image**: An optional base image to use as a starting point Style Image**: An optional image to use as a style reference Identity Image**: An optional image to use as an identity reference Composition Image**: An optional image to use as a composition reference Depth Image**: An optional depth image to use for depth-aware generation Outputs An array of generated portrait images in the form of image URLs Capabilities Omni-Zero excels at generating highly stylized and personalized portraits from text prompts. It can capture a wide range of artistic styles, from photorealistic to more abstract and impressionistic renderings. The model's ability to incorporate various input images, such as style and identity references, allows for a high degree of customization and creative expression. What can I use it for? Omni-Zero can be a powerful tool for artists, designers, and content creators who want to quickly generate unique and visually striking portrait images. It could be used to create custom avatars, character designs, or even personalized art pieces. The model's versatility also makes it suitable for various applications, such as social media content, illustrations, and even product design. Things to try One interesting aspect of Omni-Zero is its ability to blend multiple styles and identities in a single generated portrait. By providing a diverse set of input images, users can explore the interplay of different visual elements and create truly unique and captivating portraits. Additionally, experimenting with the depth image and composition inputs can lead to some fascinating depth-aware and spatially-aware generations.
Updated Invalid Date

zerodim
1
The zerodim model, developed by Aviv Gabbay, is a powerful tool for disentangled face manipulation. It leverages CLIP-based annotations to facilitate the manipulation of facial attributes like age, gender, ethnicity, hair color, beard, and glasses in a zero-shot manner. This approach sets it apart from models like StyleCLIP, which requires textual descriptions for manipulation, and GFPGAN, which focuses on face restoration. Model inputs and outputs The zerodim model takes a facial image as input and allows manipulation of specific attributes. The available attributes include age, gender, hair color, beard, and glasses. The model outputs the manipulated image, seamlessly incorporating the desired changes. Inputs image**: The input facial image, which will be aligned and resized to 256x256 pixels. factor**: The attribute of interest to manipulate, such as age, gender, hair color, beard, or glasses. Outputs file**: The manipulated image with the specified attribute change. text**: A brief description of the manipulation performed. Capabilities The zerodim model excels at disentangled face manipulation, allowing users to independently modify facial attributes without affecting other aspects of the image. This capability is particularly useful for applications such as photo editing, virtual try-on, and character design. The model's ability to leverage CLIP-based annotations sets it apart from traditional face manipulation approaches, enabling a more intuitive and user-friendly experience. What can I use it for? The zerodim model can be employed in a variety of applications, including: Photo editing**: Easily manipulate facial attributes in existing photos to explore different looks or create desired effects. Virtual try-on**: Visualize how a person would appear with different hairstyles, glasses, or other facial features. Character design**: Quickly experiment with different facial characteristics when designing characters for games, movies, or other creative projects. Things to try One interesting aspect of the zerodim model is its ability to separate the manipulation of specific facial attributes from the overall image. This allows users to explore subtle changes or exaggerated effects, unlocking a wide range of creative possibilities. For example, you could try manipulating the gender of a face while keeping other features unchanged, or experiment with dramatic changes in hair color or the presence of facial hair.
Updated Invalid Date