1-Bit FQT: Pushing the Limit of Fully Quantized Training to 1-bit

0
Sign in to get full access
Overview
- The paper presents a new training technique called 1-Bit FQT (Fully Quantized Training to 1-bit) that pushes the limits of quantization in neural network training.
- 1-Bit FQT can train neural networks using only 1-bit weights and activations, significantly reducing the memory and computational requirements compared to traditional training.
- Experiments demonstrate that 1-Bit FQT can achieve comparable performance to full-precision training on various benchmark tasks.
Plain English Explanation
1-Bit FQT: Pushing the Limit of Fully Quantized Training to 1-bit is a new technique that allows training neural networks using only 1-bit for weights and activations. This is a significant advancement, as most neural network training today uses 32-bit or 16-bit floating-point numbers, which require much more memory and computation.
By using just 1-bit, the memory and computational requirements are greatly reduced. This could enable deploying powerful AI models on resource-constrained devices like smartphones or embedded systems. The key insight is that even with such extreme quantization, the neural network can still learn effectively and achieve comparable performance to the original full-precision model.
The researchers demonstrate the effectiveness of 1-Bit FQT on several benchmark tasks, showing that it can match the accuracy of the full-precision models. This is an important step towards making AI systems more efficient and accessible, especially in edge computing scenarios where memory and power are limited.
Technical Explanation
1-Bit FQT: Pushing the Limit of Fully Quantized Training to 1-bit introduces a new training technique that can train neural networks using only 1-bit weights and activations. This is a significant advancement compared to traditional training, which typically uses 32-bit or 16-bit floating-point values.
The key components of the 1-Bit FQT approach are:
- Quantization: The weights and activations of the neural network are quantized to 1-bit values during training. This is achieved through a specialized quantization function that maps the full-precision values to binary.
- Gradient Computation: The gradients are computed using the quantized weights and activations, and then the full-precision weights are updated accordingly.
- Normalization: The researchers introduce a normalization scheme to ensure the quantized values have the appropriate scale and distribution, which is crucial for effective training.
The experiments in the paper demonstrate the effectiveness of 1-Bit FQT on various benchmark tasks, including image classification, language modeling, and reinforcement learning. The results show that 1-Bit FQT can achieve performance comparable to full-precision training, while significantly reducing the memory and computational requirements.
Critical Analysis
The paper presents a compelling approach to pushing the limits of neural network quantization, but there are a few potential caveats and areas for further research:
[1] The experiments are limited to relatively simple benchmark tasks, and it's unclear how well 1-Bit FQT would scale to more complex real-world problems. Further research is needed to understand the limits of this technique.
[2] The paper does not provide a thorough analysis of the training dynamics and how the extreme quantization affects learning. A deeper understanding of the underlying mechanisms could lead to further improvements.
[3] The 1-bit quantization may introduce significant information loss, which could limit the expressiveness of the neural network. Exploring hybrid approaches with higher bit-widths for certain layers or components could be a promising direction.
[4] The paper does not address the potential impact of 1-Bit FQT on neural network robustness and generalization. Further research is needed to understand how the quantization affects these important properties.
Overall, the 1-Bit FQT technique is a significant advancement in neural network quantization and has the potential to enable more efficient AI systems. However, continued research is necessary to address the limitations and expand the applicability of this approach.
Conclusion
1-Bit FQT: Pushing the Limit of Fully Quantized Training to 1-bit presents a novel training technique that can train neural networks using only 1-bit weights and activations. This is a significant step forward in making AI systems more memory and computationally efficient, which could enable their deployment on resource-constrained devices.
The experiments demonstrate that 1-Bit FQT can achieve performance comparable to full-precision training on various benchmark tasks, while drastically reducing the memory and computational requirements. This work opens up new possibilities for deploying powerful AI models in edge computing scenarios, where memory and power are limited.
Further research is needed to address the potential limitations of the 1-Bit FQT approach, such as its scalability to complex real-world problems, the impact on neural network robustness and generalization, and the underlying training dynamics. Nonetheless, this paper represents an important milestone in the ongoing efforts to make AI systems more efficient and accessible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
1-Bit FQT: Pushing the Limit of Fully Quantized Training to 1-bit
Chang Gao, Jianfei Chen, Kang Zhao, Jiaqi Wang, Liping Jing
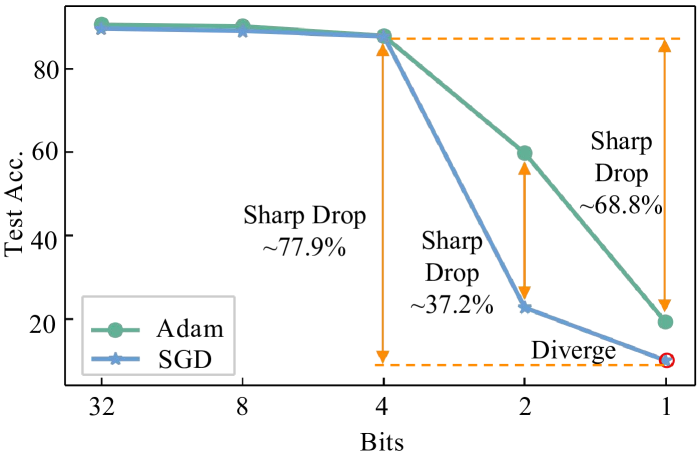
Fully quantized training (FQT) accelerates the training of deep neural networks by quantizing the activations, weights, and gradients into lower precision. To explore the ultimate limit of FQT (the lowest achievable precision), we make a first attempt to 1-bit FQT. We provide a theoretical analysis of FQT based on Adam and SGD, revealing that the gradient variance influences the convergence of FQT. Building on these theoretical results, we introduce an Activation Gradient Pruning (AGP) strategy. The strategy leverages the heterogeneity of gradients by pruning less informative gradients and enhancing the numerical precision of remaining gradients to mitigate gradient variance. Additionally, we propose Sample Channel joint Quantization (SCQ), which utilizes different quantization strategies in the computation of weight gradients and activation gradients to ensure that the method is friendly to low-bitwidth hardware. Finally, we present a framework to deploy our algorithm. For fine-tuning VGGNet-16 and ResNet-18 on multiple datasets, our algorithm achieves an average accuracy improvement of approximately 6%, compared to per-sample quantization. Moreover, our training speedup can reach a maximum of 5.13x compared to full precision training.
Read more8/27/2024
0
Gradient-based Automatic Per-Weight Mixed Precision Quantization for Neural Networks On-Chip
Chang Sun, Thea K. {AA}rrestad, Vladimir Loncar, Jennifer Ngadiuba, Maria Spiropulu
Model size and inference speed at deployment time, are major challenges in many deep learning applications. A promising strategy to overcome these challenges is quantization. However, a straightforward uniform quantization to very low precision can result in significant accuracy loss. Mixed-precision quantization, based on the idea that certain parts of the network can accommodate lower precision without compromising performance compared to other parts, offers a potential solution. In this work, we present High Granularity Quantization (HGQ), an innovative quantization-aware training method that could fine-tune the per-weight and per-activation precision by making them optimizable through gradient descent. This approach enables ultra-low latency and low power neural networks on hardware capable of performing arithmetic operations with an arbitrary number of bits, such as FPGAs and ASICs. We demonstrate that HGQ can outperform existing methods by a substantial margin, achieving resource reduction by up to a factor of 20 and latency improvement by a factor of 5 while preserving accuracy.
Read more8/12/2024
🧠
0
Accurate Neural Training with 4-bit Matrix Multiplications at Standard Formats
Brian Chmiel, Ron Banner, Elad Hoffer, Hilla Ben Yaacov, Daniel Soudry
Quantization of the weights and activations is one of the main methods to reduce the computational footprint of Deep Neural Networks (DNNs) training. Current methods enable 4-bit quantization of the forward phase. However, this constitutes only a third of the training process. Reducing the computational footprint of the entire training process requires the quantization of the neural gradients, i.e., the loss gradients with respect to the outputs of intermediate neural layers. Previous works separately showed that accurate 4-bit quantization of the neural gradients needs to (1) be unbiased and (2) have a log scale. However, no previous work aimed to combine both ideas, as we do in this work. Specifically, we examine the importance of having unbiased quantization in quantized neural network training, where to maintain it, and how to combine it with logarithmic quantization. Based on this, we suggest a $textit{logarithmic unbiased quantization}$ (LUQ) method to quantize both the forward and backward phases to 4-bit, achieving state-of-the-art results in 4-bit training without the overhead. For example, in ResNet50 on ImageNet, we achieved a degradation of 1.1%. We further improve this to a degradation of only 0.32% after three epochs of high precision fine-tuning, combined with a variance reduction method -- where both these methods add overhead comparable to previously suggested methods.
Read more6/11/2024
🏋️
0
AdaQAT: Adaptive Bit-Width Quantization-Aware Training
C'edric Gernigon (TARAN), Silviu-Ioan Filip (TARAN), Olivier Sentieys (TARAN), Cl'ement Coggiola (CNES), Mickael Bruno (CNES)
Large-scale deep neural networks (DNNs) have achieved remarkable success in many application scenarios. However, high computational complexity and energy costs of modern DNNs make their deployment on edge devices challenging. Model quantization is a common approach to deal with deployment constraints, but searching for optimized bit-widths can be challenging. In this work, we present Adaptive Bit-Width Quantization Aware Training (AdaQAT), a learning-based method that automatically optimizes weight and activation signal bit-widths during training for more efficient DNN inference. We use relaxed real-valued bit-widths that are updated using a gradient descent rule, but are otherwise discretized for all quantization operations. The result is a simple and flexible QAT approach for mixed-precision uniform quantization problems. Compared to other methods that are generally designed to be run on a pretrained network, AdaQAT works well in both training from scratch and fine-tuning scenarios.Initial results on the CIFAR-10 and ImageNet datasets using ResNet20 and ResNet18 models, respectively, indicate that our method is competitive with other state-of-the-art mixed-precision quantization approaches.
Read more4/29/2024