1M-Deepfakes Detection Challenge

0

Sign in to get full access
Overview
- The 1M-Deepfakes Detection Challenge is a large-scale dataset and competition focused on detecting deepfake videos.
- The dataset contains over 1 million deepfake videos, making it the largest of its kind.
- The challenge aims to develop robust deepfake detection models that can generalize to a wide range of scenarios.
Plain English Explanation
Deepfakes are videos that have been digitally manipulated to make it look like someone said or did something they didn't. This can be used to spread misinformation or create harmful content. The 1M-Deepfakes Detection Challenge is a competition that provides a massive dataset of over 1 million deepfake videos to help researchers and developers create better tools for detecting these kinds of fake videos.
The goal is to develop deepfake detection models that can reliably spot deepfakes, even in challenging real-world scenarios. This is important because as deepfake technology becomes more advanced, it's crucial to have strong safeguards in place to prevent the malicious use of this technology. By training on such a large and diverse dataset, the hope is that the detection models will be able to generalize well and catch deepfakes that haven't been seen before.
Technical Explanation
The 1M-Deepfakes Detection Challenge provides a large-scale dataset designed to push the boundaries of deepfake detection. The dataset contains over 1 million deepfake videos, making it the largest of its kind. These deepfakes were generated using a variety of state-of-the-art deepfake generation techniques, including language model-driven audio synthesis.
The dataset also includes a large collection of real, unmanipulated videos to serve as the "real" class for the detection task. Together, this massive dataset spanning over 1 million examples aims to create a challenging testbed for evaluating the robustness and generalization of deepfake detection models.
Critical Analysis
The 1M-Deepfakes Detection Challenge represents a significant step forward in the field of deepfake detection. By providing such a large and diverse dataset, the challenge encourages the development of more sophisticated detection models that can handle the complexity and variability of real-world deepfakes.
However, the challenge may also have some limitations. The dataset, while impressive in size, may not fully capture the constantly evolving nature of deepfake technology. As new deepfake generation techniques emerge, the challenge dataset may become outdated, requiring regular updates to maintain relevance.
Additionally, while the challenge focuses on video-based deepfakes, the growing threat of audio-based deepfakes is also a concern that may not be addressed as directly. Researchers and developers should consider exploring multimodal approaches that can detect deepfakes across different media types.
Conclusion
The 1M-Deepfakes Detection Challenge represents a significant advancement in the fight against the spread of misinformation and harmful deepfake content. By providing a massive dataset and encouraging the development of robust deepfake detection models, the challenge aims to equip researchers and practitioners with the tools they need to stay ahead of this evolving threat.
As deepfake technology continues to advance, it will be crucial to maintain and expand initiatives like the 1M-Deepfakes Detection Challenge to ensure that the tools for detecting and mitigating deepfakes keep pace with the rapidly changing landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
1M-Deepfakes Detection Challenge
Zhixi Cai, Abhinav Dhall, Shreya Ghosh, Munawar Hayat, Dimitrios Kollias, Kalin Stefanov, Usman Tariq
The detection and localization of deepfake content, particularly when small fake segments are seamlessly mixed with real videos, remains a significant challenge in the field of digital media security. Based on the recently released AV-Deepfake1M dataset, which contains more than 1 million manipulated videos across more than 2,000 subjects, we introduce the 1M-Deepfakes Detection Challenge. This challenge is designed to engage the research community in developing advanced methods for detecting and localizing deepfake manipulations within the large-scale high-realistic audio-visual dataset. The participants can access the AV-Deepfake1M dataset and are required to submit their inference results for evaluation across the metrics for detection or localization tasks. The methodologies developed through the challenge will contribute to the development of next-generation deepfake detection and localization systems. Evaluation scripts, baseline models, and accompanying code will be available on https://github.com/ControlNet/AV-Deepfake1M.
Read more9/12/2024
🌐
0
AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset
Zhixi Cai, Shreya Ghosh, Aman Pankaj Adatia, Munawar Hayat, Abhinav Dhall, Tom Gedeon, Kalin Stefanov
The detection and localization of highly realistic deepfake audio-visual content are challenging even for the most advanced state-of-the-art methods. While most of the research efforts in this domain are focused on detecting high-quality deepfake images and videos, only a few works address the problem of the localization of small segments of audio-visual manipulations embedded in real videos. In this research, we emulate the process of such content generation and propose the AV-Deepfake1M dataset. The dataset contains content-driven (i) video manipulations, (ii) audio manipulations, and (iii) audio-visual manipulations for more than 2K subjects resulting in a total of more than 1M videos. The paper provides a thorough description of the proposed data generation pipeline accompanied by a rigorous analysis of the quality of the generated data. The comprehensive benchmark of the proposed dataset utilizing state-of-the-art deepfake detection and localization methods indicates a significant drop in performance compared to previous datasets. The proposed dataset will play a vital role in building the next-generation deepfake localization methods. The dataset and associated code are available at https://github.com/ControlNet/AV-Deepfake1M .
Read more7/30/2024
🔎
0
WildDeepfake: A Challenging Real-World Dataset for Deepfake Detection
Bojia Zi, Minghao Chang, Jingjing Chen, Xingjun Ma, Yu-Gang Jiang
In recent years, the abuse of a face swap technique called deepfake has raised enormous public concerns. So far, a large number of deepfake videos (known as deepfakes) have been crafted and uploaded to the internet, calling for effective countermeasures. One promising countermeasure against deepfakes is deepfake detection. Several deepfake datasets have been released to support the training and testing of deepfake detectors, such as DeepfakeDetection and FaceForensics++. While this has greatly advanced deepfake detection, most of the real videos in these datasets are filmed with a few volunteer actors in limited scenes, and the fake videos are crafted by researchers using a few popular deepfake softwares. Detectors developed on these datasets may become less effective against real-world deepfakes on the internet. To better support detection against real-world deepfakes, in this paper, we introduce a new dataset WildDeepfake which consists of 7,314 face sequences extracted from 707 deepfake videos collected completely from the internet. WildDeepfake is a small dataset that can be used, in addition to existing datasets, to develop and test the effectiveness of deepfake detectors against real-world deepfakes. We conduct a systematic evaluation of a set of baseline detection networks on both existing and our WildDeepfake datasets, and show that WildDeepfake is indeed a more challenging dataset, where the detection performance can decrease drastically. We also propose two (eg. 2D and 3D) Attention-based Deepfake Detection Networks (ADDNets) to leverage the attention masks on real/fake faces for improved detection. We empirically verify the effectiveness of ADDNets on both existing datasets and WildDeepfake. The dataset is available at: https://github.com/OpenTAI/wild-deepfake.
Read more7/18/2024
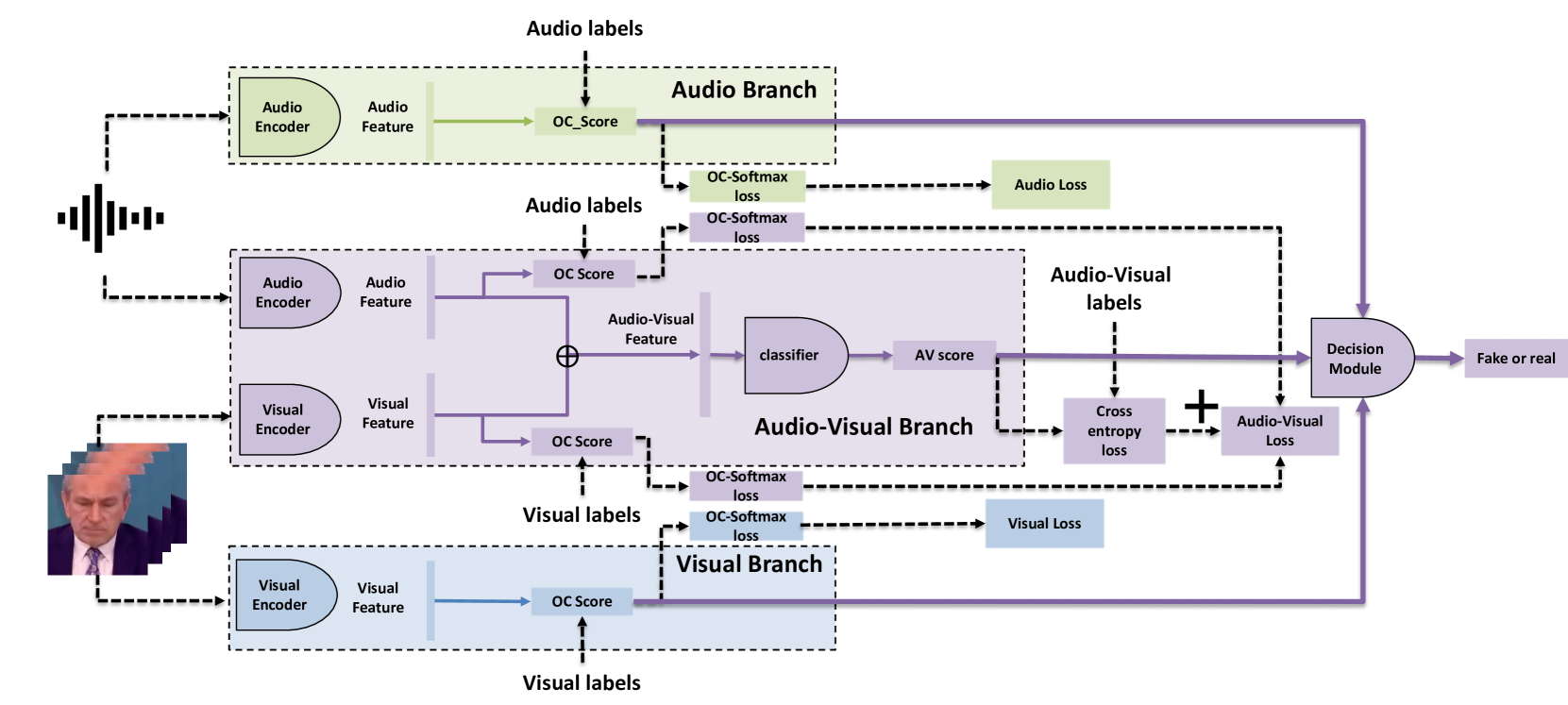
0
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake videos (Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and Unsynchronized videos). The experimental results demonstrate that our approach surpasses the previous models by a large margin. Furthermore, our proposed framework offers interpretability, indicating which modality the model identifies as more likely to be fake. The source code is released at https://github.com/bok-bok/MSOC.
Read more8/20/2024