Reducing Fine-Tuning Memory Overhead by Approximate and Memory-Sharing Backpropagation

0
Sign in to get full access
Overview
• This paper presents a novel approach to reduce the memory overhead during fine-tuning of large language models (LLMs).
• The proposed method, called Approximate and Memory-Sharing Backpropagation (AMSB), introduces two key techniques: approximate backpropagation and memory sharing.
• These techniques aim to significantly reduce the memory requirements of fine-tuning LLMs without compromising performance.
Plain English Explanation
Training large language models (LLMs) like GPT-3 can be extremely memory-intensive, especially during the fine-tuning process. The authors of this paper have developed a new technique called Approximate and Memory-Sharing Backpropagation (AMSB) to address this challenge.
The key idea behind AMSB is to reduce the memory required for fine-tuning LLMs in two ways:
-
Approximate Backpropagation: Instead of performing the full, exact backpropagation algorithm, AMSB uses an approximate version that requires less memory. This approximation still allows the model to learn effectively, but with a smaller memory footprint.
-
Memory Sharing: AMSB shares memory between different parts of the model during the backpropagation process. This means that the model doesn't need to store as much intermediate data, further reducing the overall memory requirements.
By combining these two techniques, the researchers were able to significantly reduce the memory overhead of fine-tuning LLMs without sacrificing performance. This could make it easier and more feasible to fine-tune these powerful models on a wider range of hardware, including devices with limited memory resources.
Technical Explanation
The paper introduces the Approximate and Memory-Sharing Backpropagation (AMSB) method to reduce the memory overhead of fine-tuning large language models (LLMs).
The first key component of AMSB is Approximate Backpropagation. Instead of performing the full, exact backpropagation algorithm, AMSB uses an approximation that requires less memory. Specifically, the authors propose an approximate gradient calculation that only considers a subset of the model's parameters during each backpropagation step.
The second component is Memory Sharing. AMSB shares memory between different parts of the model during the backpropagation process. This is achieved by reusing the activations and gradients computed for one layer in the computations for another layer, rather than storing them separately.
The authors evaluate AMSB on a variety of LLM fine-tuning tasks, including text classification, natural language inference, and question answering. Their results show that AMSB can significantly reduce the memory overhead of fine-tuning these models, often by 50% or more, without sacrificing performance.
Critical Analysis
The paper provides a compelling approach to reducing the memory overhead of fine-tuning large language models, which is a significant challenge in the field of machine learning. The authors have thoughtfully designed two key techniques, approximate backpropagation and memory sharing, to address this problem.
One potential limitation of the AMSB method is that the approximate backpropagation algorithm may not fully capture the complex dependencies and gradients within the LLM. While the authors demonstrate that the performance impact is minimal, this approximation could still lead to some degradation in fine-tuning performance, especially for more challenging tasks.
Additionally, the paper does not extensively explore the trade-offs between the degree of approximation and memory savings. It would be interesting to see how the performance and memory usage scale as the approximation becomes more or less aggressive.
Finally, the authors mention that AMSB could be combined with other memory-saving techniques, such as BLOB or DPZero, but they do not provide a detailed analysis of how these techniques could be integrated and what the potential benefits might be.
Conclusion
The Approximate and Memory-Sharing Backpropagation (AMSB) method presented in this paper is a promising approach to reducing the memory overhead of fine-tuning large language models. By introducing approximate backpropagation and memory sharing techniques, the authors have demonstrated significant memory savings without compromising performance.
This work has important implications for the broader field of machine learning, as it could make it more feasible to fine-tune powerful LLMs on a wider range of hardware, including devices with limited memory resources. Additionally, the techniques introduced in this paper could potentially be combined with other memory-saving methods, further enhancing the efficiency of LLM fine-tuning.
Overall, this paper represents an important contribution to the ongoing efforts to make large language models more accessible and practical for a wider range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reducing Fine-Tuning Memory Overhead by Approximate and Memory-Sharing Backpropagation
Yuchen Yang, Yingdong Shi, Cheems Wang, Xiantong Zhen, Yuxuan Shi, Jun Xu
Fine-tuning pretrained large models to downstream tasks is an important problem, which however suffers from huge memory overhead due to large-scale parameters. This work strives to reduce memory overhead in fine-tuning from perspectives of activation function and layer normalization. To this end, we propose the Approximate Backpropagation (Approx-BP) theory, which provides the theoretical feasibility of decoupling the forward and backward passes. We apply our Approx-BP theory to backpropagation training and derive memory-efficient alternatives of GELU and SiLU activation functions, which use derivative functions of ReLUs in the backward pass while keeping their forward pass unchanged. In addition, we introduce a Memory-Sharing Backpropagation strategy, which enables the activation memory to be shared by two adjacent layers, thereby removing activation memory usage redundancy. Our method neither induces extra computation nor reduces training efficiency. We conduct extensive experiments with pretrained vision and language models, and the results demonstrate that our proposal can reduce up to $sim$$30%$ of the peak memory usage. Our code is released at https://github.com/yyyyychen/LowMemoryBP.
Read more6/26/2024

0
Inverted Activations
Georgii Novikov, Ivan Oseledets
The scaling of neural networks with increasing data and model sizes necessitates more efficient deep learning algorithms. This paper addresses the memory footprint challenge in neural network training by proposing a modification to the handling of activation tensors in pointwise nonlinearity layers. Traditionally, these layers save the entire input tensor for the backward pass, leading to substantial memory use. Our method involves saving the output tensor instead, reducing the memory required when the subsequent layer also saves its input tensor. This approach is particularly beneficial for transformer-based architectures like GPT, BERT, Mistral, and Llama. Application of our method involves taken an inverse function of nonlinearity. To the best of our knowledge, that can not be done analitically and instead we buid an accurate approximations using simpler functions. Experimental results confirm that our method significantly reduces memory usage without affecting training accuracy. The implementation is available at https://github.com/PgLoLo/optiacts.
Read more7/23/2024
0
2BP: 2-Stage Backpropagation
Christopher Rae, Joseph K. L. Lee, James Richings
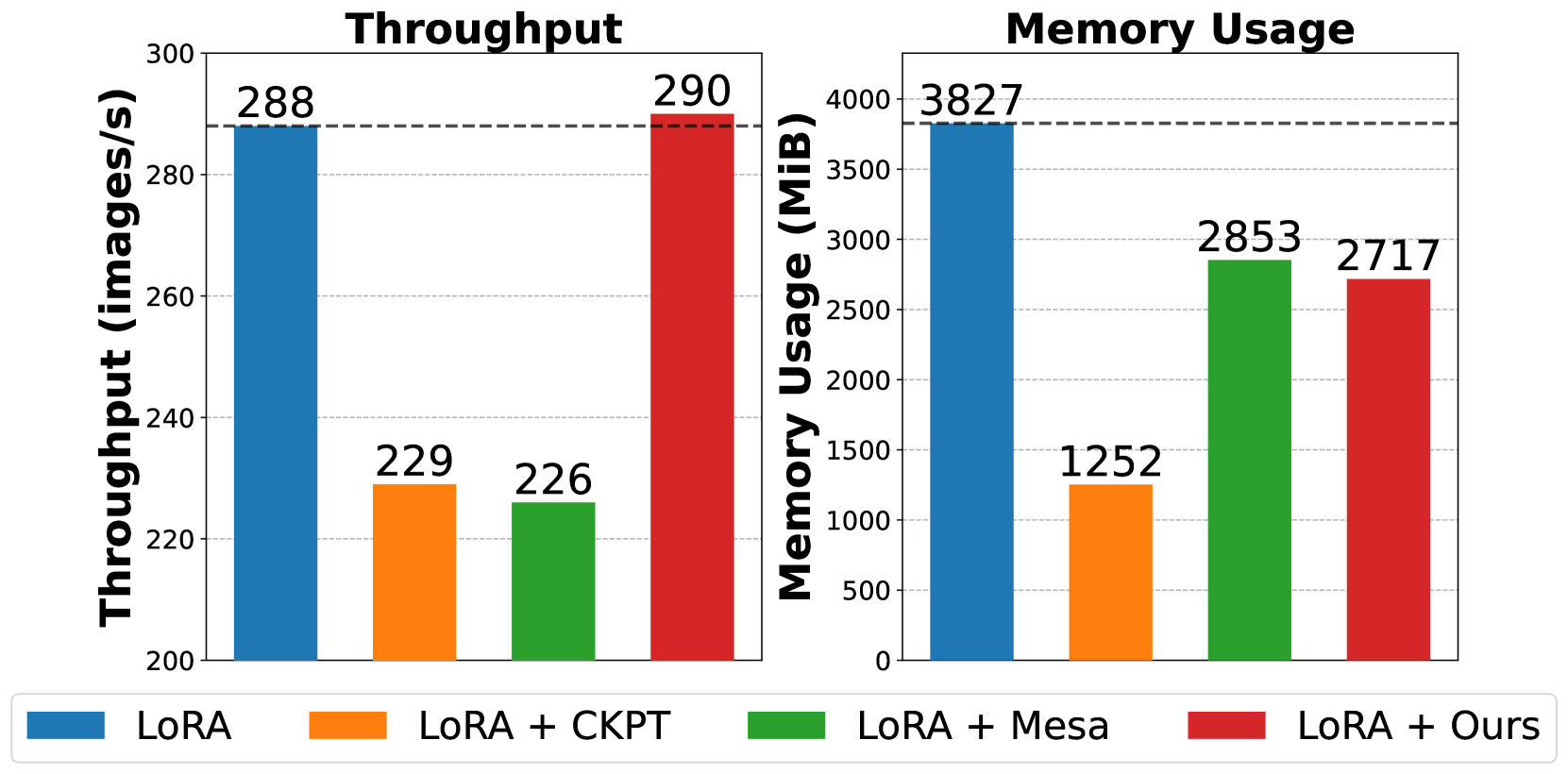
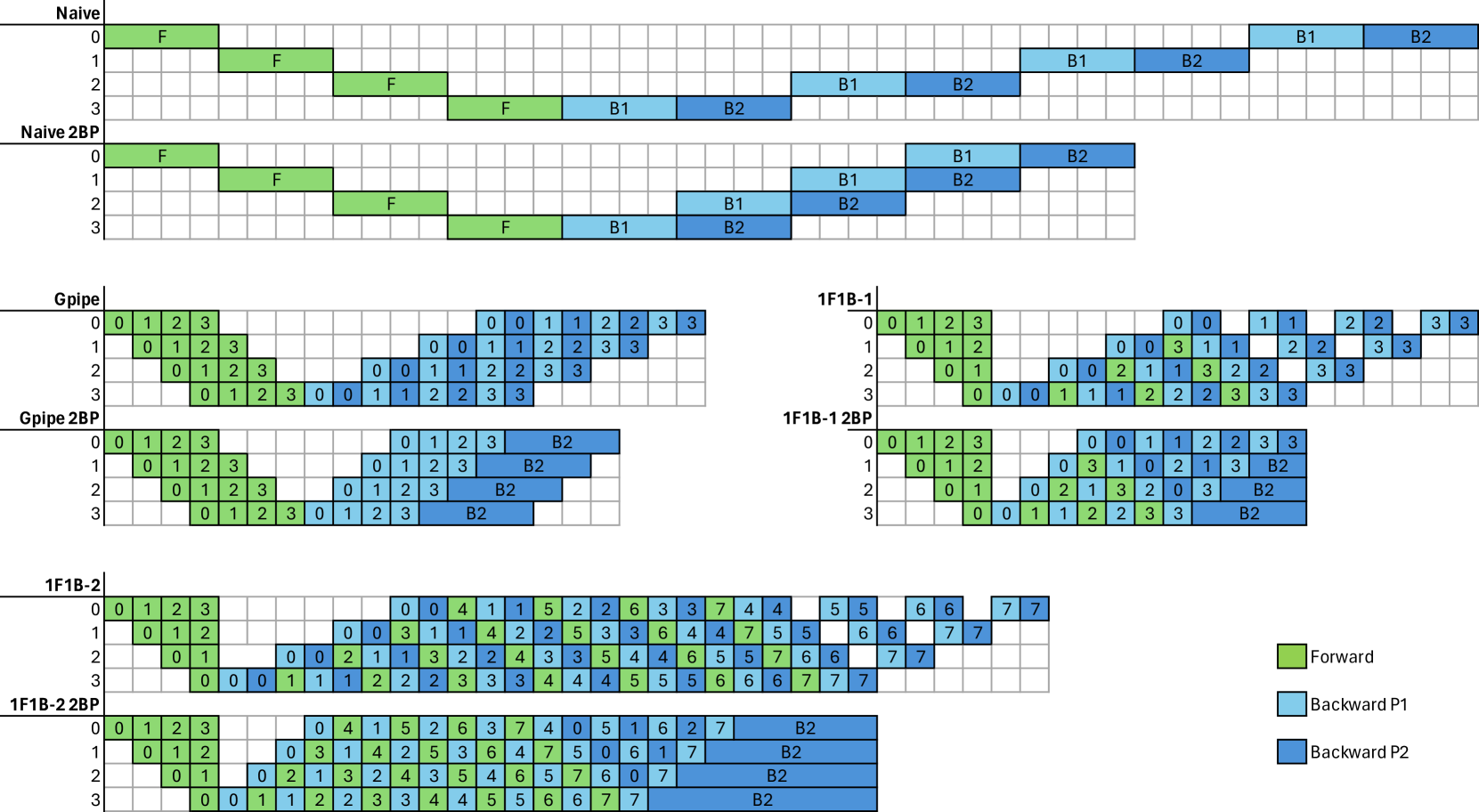
As Deep Neural Networks (DNNs) grow in size and complexity, they often exceed the memory capacity of a single accelerator, necessitating the sharding of model parameters across multiple accelerators. Pipeline parallelism is a commonly used sharding strategy for training large DNNs. However, current implementations of pipeline parallelism are being unintentionally bottlenecked by the automatic differentiation tools provided by ML frameworks. This paper introduces 2-stage backpropagation (2BP). By splitting the backward propagation step into two separate stages, we can reduce idle compute time. We tested 2BP on various model architectures and pipelining schedules, achieving increases in throughput in all cases. Using 2BP, we were able to achieve a 1.70x increase in throughput compared to traditional methods when training a LLaMa-like transformer with 7 billion parameters across 4 GPUs.
Read more5/29/2024
💬
0
DPZero: Private Fine-Tuning of Language Models without Backpropagation
Liang Zhang, Bingcong Li, Kiran Koshy Thekumparampil, Sewoong Oh, Niao He
The widespread practice of fine-tuning large language models (LLMs) on domain-specific data faces two major challenges in memory and privacy. First, as the size of LLMs continues to grow, the memory demands of gradient-based training methods via backpropagation become prohibitively high. Second, given the tendency of LLMs to memorize training data, it is important to protect potentially sensitive information in the fine-tuning data from being regurgitated. Zeroth-order methods, which rely solely on forward passes, substantially reduce memory consumption during training. However, directly combining them with standard differentially private gradient descent suffers more as model size grows. To bridge this gap, we introduce DPZero, a novel private zeroth-order algorithm with nearly dimension-independent rates. The memory efficiency of DPZero is demonstrated in privately fine-tuning RoBERTa and OPT on several downstream tasks. Our code is available at https://github.com/Liang137/DPZero.
Read more6/7/2024