360$^circ$ High-Resolution Depth Estimation via Uncertainty-aware Structural Knowledge Transfer

0
🔄
Sign in to get full access
Overview
- This paper explores a novel approach to estimate high-resolution (HR) omnidirectional depth maps directly from low-resolution (LR) omnidirectional images (ODIs), without access to HR depth ground truth.
- The key idea is to transfer scene structural knowledge from the HR image modality and corresponding LR depth maps to enable HR depth estimation without extra inference cost.
- The method introduces ODI super-resolution (SR) as an auxiliary task, training both tasks collaboratively in a weakly supervised manner to boost HR depth estimation performance.
Plain English Explanation
The paper tackles the problem of estimating high-quality 360-degree depth maps from low-quality 360-degree images. Existing methods typically require high-resolution 360-degree images as input, which can be impractical for resource-constrained devices. Additionally, depth maps often have lower resolution than color images.
The researchers propose a new approach that can generate high-resolution depth maps directly from low-resolution 360-degree images, without needing access to high-resolution depth ground truth data. The key insight is to leverage the structural information present in the high-resolution images and the corresponding low-resolution depth maps to train the model to estimate high-resolution depth.
Specifically, the method introduces 360-degree image super-resolution as an auxiliary task, training the model to perform both super-resolution and high-resolution depth estimation collaboratively. This allows the model to learn the underlying scene structure, which is then transferred to improve the depth estimation task. The paper introduces novel architectural components, such as a cylindrical implicit interpolation function and a feature distillation loss, to facilitate this knowledge transfer.
The researchers demonstrate that their weakly-supervised method outperforms baseline approaches and even achieves comparable performance to fully-supervised methods that have access to high-resolution depth ground truth.
Technical Explanation
The paper presents a novel method for estimating high-resolution (HR) omnidirectional depth maps from low-resolution (LR) omnidirectional images (ODIs), without access to HR depth ground truth. Existing methods typically leverage HR ODIs as input through fully-supervised learning, which is undesirable for resource-constrained devices.
To address this, the authors introduce an approach that transfers scene structural knowledge from the HR image modality and corresponding LR depth maps to enable HR depth estimation without extra inference cost. Specifically, they incorporate ODI super-resolution (SR) as an auxiliary task and train both tasks collaboratively in a weakly supervised manner.
The ODI SR task extracts scene structural knowledge via uncertainty estimation, which is then leveraged by a proposed scene structural knowledge transfer (SSKT) module. The SSKT module has two key components:
- A cylindrical implicit interpolation function (CIIF) to learn cylindrical neural interpolation weights for feature up-sampling, with shared parameters between the two tasks.
- A feature distillation (FD) loss that provides extra structural regularization to help the HR depth estimation task learn more scene structural knowledge.
Extensive experiments demonstrate that the proposed weakly-supervised method outperforms baseline approaches and even achieves comparable performance to fully-supervised methods that have access to HR depth ground truth.
Critical Analysis
The paper presents a compelling approach to address the practical challenge of estimating high-resolution omnidirectional depth maps from low-resolution inputs, without requiring access to high-resolution depth ground truth data. The key innovation of transferring scene structural knowledge from related modalities is well-motivated and the experiments show promising results.
However, the paper does not discuss some potential limitations or areas for further research. For example, the performance of the method on diverse datasets and scenes is not explored, and the scalability of the approach to very high resolutions or complex environments is unclear. Additionally, the paper does not provide a thorough analysis of the failure cases or discuss potential biases that may be introduced by the weakly-supervised training process.
Further research could investigate the robustness of the method to noise or other real-world challenges, as well as explore ways to incorporate additional cues or constraints to improve the reliability and generalization of the depth estimation. Comparisons to unsupervised depth estimation techniques could also provide useful insights.
Overall, the paper presents an interesting and practical approach to a challenging problem in computer vision, but there is room for further exploration and refinement to address the potential limitations and strengthen the broader applicability of the method.
Conclusion
This paper introduces a novel weakly-supervised approach for estimating high-resolution omnidirectional depth maps directly from low-resolution omnidirectional images, without requiring access to high-resolution depth ground truth. The key innovation is the transfer of scene structural knowledge from the high-resolution image modality and corresponding low-resolution depth maps, enabling high-quality depth estimation without extra inference cost.
The proposed method, which integrates 360-degree image super-resolution as an auxiliary task, outperforms baseline approaches and even achieves comparable performance to fully-supervised methods. This work demonstrates the potential of leveraging related modalities and collaborative training to address practical challenges in depth estimation, with implications for applications such as 360-degree imaging, virtual reality, and autonomous navigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
360$^circ$ High-Resolution Depth Estimation via Uncertainty-aware Structural Knowledge Transfer
Zidong Cao, Hao Ai, Athanasios V. Vasilakos, Lin Wang
To predict high-resolution (HR) omnidirectional depth map, existing methods typically leverage HR omnidirectional image (ODI) as the input via fully-supervised learning. However, in practice, taking HR ODI as input is undesired due to resource-constrained devices. In addition, depth maps are often with lower resolution than color images. Therefore, in this paper, we explore for the first time to estimate the HR omnidirectional depth directly from a low-resolution (LR) ODI, when no HR depth GT map is available. Our key idea is to transfer the scene structural knowledge from the HR image modality and the corresponding LR depth maps to achieve the goal of HR depth estimation without any extra inference cost. Specifically, we introduce ODI super-resolution (SR) as an auxiliary task and train both tasks collaboratively in a weakly supervised manner to boost the performance of HR depth estimation. The ODI SR task extracts the scene structural knowledge via uncertainty estimation. Buttressed by this, a scene structural knowledge transfer (SSKT) module is proposed with two key components. First, we employ a cylindrical implicit interpolation function (CIIF) to learn cylindrical neural interpolation weights for feature up-sampling and share the parameters of CIIFs between the two tasks. Then, we propose a feature distillation (FD) loss that provides extra structural regularization to help the HR depth estimation task learn more scene structural knowledge. Extensive experiments demonstrate that our weakly-supervised method outperforms baseline methods, and even achieves comparable performance with the fully-supervised methods.
Read more5/24/2024

0
OmniSSR: Zero-shot Omnidirectional Image Super-Resolution using Stable Diffusion Model
Runyi Li, Xuhan Sheng, Weiqi Li, Jian Zhang
Omnidirectional images (ODIs) are commonly used in real-world visual tasks, and high-resolution ODIs help improve the performance of related visual tasks. Most existing super-resolution methods for ODIs use end-to-end learning strategies, resulting in inferior realness of generated images and a lack of effective out-of-domain generalization capabilities in training methods. Image generation methods represented by diffusion model provide strong priors for visual tasks and have been proven to be effectively applied to image restoration tasks. Leveraging the image priors of the Stable Diffusion (SD) model, we achieve omnidirectional image super-resolution with both fidelity and realness, dubbed as OmniSSR. Firstly, we transform the equirectangular projection (ERP) images into tangent projection (TP) images, whose distribution approximates the planar image domain. Then, we use SD to iteratively sample initial high-resolution results. At each denoising iteration, we further correct and update the initial results using the proposed Octadecaplex Tangent Information Interaction (OTII) and Gradient Decomposition (GD) technique to ensure better consistency. Finally, the TP images are transformed back to obtain the final high-resolution results. Our method is zero-shot, requiring no training or fine-tuning. Experiments of our method on two benchmark datasets demonstrate the effectiveness of our proposed method.
Read more4/17/2024

0
Geometric Distortion Guided Transformer for Omnidirectional Image Super-Resolution
Cuixin Yang, Rongkang Dong, Jun Xiao, Cong Zhang, Kin-Man Lam, Fei Zhou, Guoping Qiu
As virtual and augmented reality applications gain popularity, omnidirectional image (ODI) super-resolution has become increasingly important. Unlike 2D plain images that are formed on a plane, ODIs are projected onto spherical surfaces. Applying established image super-resolution methods to ODIs, therefore, requires performing equirectangular projection (ERP) to map the ODIs onto a plane. ODI super-resolution needs to take into account geometric distortion resulting from ERP. However, without considering such geometric distortion of ERP images, previous deep-learning-based methods only utilize a limited range of pixels and may easily miss self-similar textures for reconstruction. In this paper, we introduce a novel Geometric Distortion Guided Transformer for Omnidirectional image Super-Resolution (GDGT-OSR). Specifically, a distortion modulated rectangle-window self-attention mechanism, integrated with deformable self-attention, is proposed to better perceive the distortion and thus involve more self-similar textures. Distortion modulation is achieved through a newly devised distortion guidance generator that produces guidance by exploiting the variability of distortion across latitudes. Furthermore, we propose a dynamic feature aggregation scheme to adaptively fuse the features from different self-attention modules. We present extensive experimental results on public datasets and show that the new GDGT-OSR outperforms methods in existing literature.
Read more6/18/2024
0
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
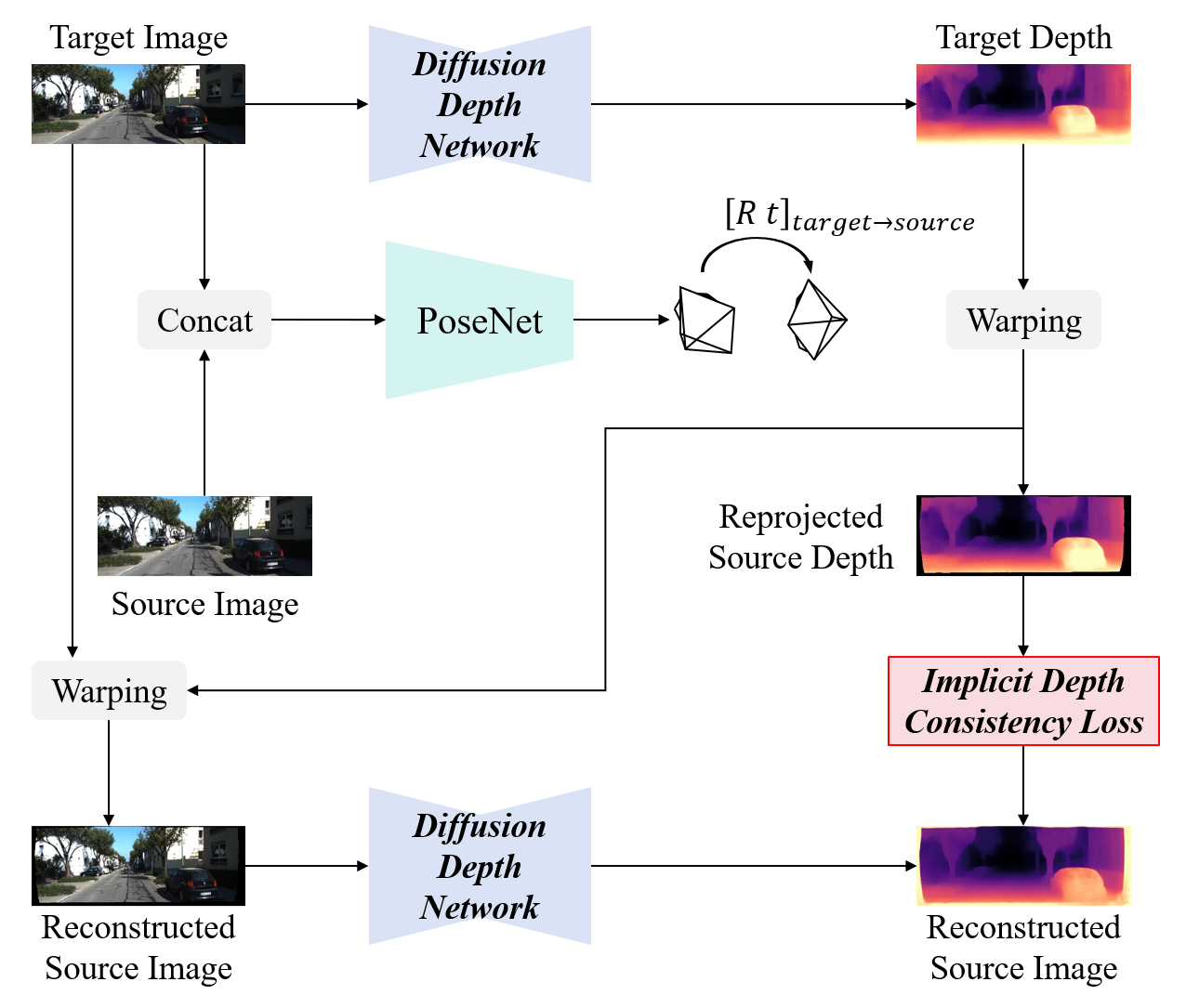
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
Read more6/17/2024