360SFUDA++: Towards Source-free UDA for Panoramic Segmentation by Learning Reliable Category Prototypes

0
🔗
Sign in to get full access
Overview
- This paper addresses the challenge of source-free unsupervised domain adaptation (SFUDA) for pinhole-to-panoramic semantic segmentation.
- The key challenges include:
- Semantic mismatches from the distinct Field-of-View (FoV) between pinhole and panoramic images.
- Style discrepancies inherent in the unsupervised domain adaptation (UDA) problem.
- Distortion in panoramic images.
- The authors propose 360SFUDA++, a method that effectively extracts knowledge from a source pinhole model and transfers it to the target panoramic domain using only unlabeled panoramic images.
Plain English Explanation
The paper tackles the problem of adapting a computer vision model trained on pinhole camera images to work well on panoramic images, without having any labeled panoramic images. This is a challenging task due to several key differences between pinhole and panoramic images:
- Semantic Mismatch: Pinhole and panoramic images capture different fields of view, so the objects and their spatial relationships appear different.
- Style Discrepancy: Pinhole and panoramic images have inherent visual style differences, even if they depict the same scene.
- Panoramic Distortion: Panoramic images exhibit geometric distortions that are not present in pinhole images.
To address these challenges, the authors propose a method called 360SFUDA++. It first uses techniques like Tangent Projection and Fixed FoV Projection to extract useful knowledge from the source pinhole model, while accounting for the differences between the image types. Then, it employs a "Reliable Panoramic Prototype Adaptation Module" to transfer this knowledge to the target panoramic domain, focusing on the most confident and relevant information. Additionally, a "Cross-projection Dual Attention Module" is used to better align the features between the pinhole and panoramic image domains.
By effectively extracting and transferring knowledge, 360SFUDA++ is able to significantly outperform previous source-free unsupervised domain adaptation methods on both synthetic and real-world benchmarks, for both outdoor and indoor scenarios.
Technical Explanation
The key technical elements of the 360SFUDA++ method are:
- Knowledge Extraction: The authors use two types of image projections to extract knowledge from the source pinhole model:
- Tangent Projection: This projection has less distortion and slices the equirectangular panoramic image into patches with a fixed field-of-view.
- Fixed FoV Projection: This projection mimics the pinhole image perspective.
- Reliable Panoramic Prototype Adaptation Module (RP2AM): This module transfers knowledge at both the prediction and prototype levels, selecting the most confident and reliable information to adapt to the target panoramic domain.
- Cross-projection Dual Attention Module (CDAM): This module better aligns the spatial and channel-wise features between the pinhole and panoramic image domains at the feature level.
The knowledge extraction and transfer processes are updated synchronously to achieve the best performance.
Critical Analysis
The paper presents a comprehensive and effective solution for the challenging problem of source-free unsupervised domain adaptation from pinhole to panoramic images. However, there are a few potential limitations and areas for further research:
- Dependence on Synthetic Data: The authors use a synthetic dataset, Frequency Decomposition Driven Unsupervised Domain Adaptation for Remote Sensing, to evaluate their method. While this allows for controlled experiments, the performance on real-world data may be different.
- Open-set Scenarios: The paper does not address open-set source-free unsupervised domain adaptation, where the target domain may contain classes not present in the source domain.
- Architecture Search: The authors use a fixed model architecture, but unsupervised domain adaptation architecture search could potentially further improve the performance.
Overall, the 360SFUDA++ method represents a significant advancement in addressing the challenging problem of pinhole-to-panoramic semantic segmentation without labeled target data. The technical innovations and strong empirical results make this a valuable contribution to the field of unsupervised domain adaptation.
Conclusion
This paper introduces 360SFUDA++, a novel method for addressing the challenging problem of source-free unsupervised domain adaptation from pinhole to panoramic images. By effectively extracting knowledge from a source pinhole model and reliably transferring it to the target panoramic domain, 360SFUDA++ is able to achieve significantly better performance than previous SFUDA methods on both synthetic and real-world benchmarks.
The key technical innovations, including the use of Tangent Projection, Fixed FoV Projection, Reliable Panoramic Prototype Adaptation Module, and Cross-projection Dual Attention Module, demonstrate the authors' deep understanding of the problem and their ability to devise effective solutions. While the paper has a few limitations, such as the reliance on synthetic data and the lack of open-set considerations, it represents an important step forward in the field of unsupervised domain adaptation and has the potential to enable more robust and versatile computer vision systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔗
0
360SFUDA++: Towards Source-free UDA for Panoramic Segmentation by Learning Reliable Category Prototypes
Xu Zheng, Pengyuan Zhou, Athanasios V. Vasilakos, Lin Wang
In this paper, we address the challenging source-free unsupervised domain adaptation (SFUDA) for pinhole-to-panoramic semantic segmentation, given only a pinhole image pre-trained model (i.e., source) and unlabeled panoramic images (i.e., target). Tackling this problem is non-trivial due to three critical challenges: 1) semantic mismatches from the distinct Field-of-View (FoV) between domains, 2) style discrepancies inherent in the UDA problem, and 3) inevitable distortion of the panoramic images. To tackle these problems, we propose 360SFUDA++ that effectively extracts knowledge from the source pinhole model with only unlabeled panoramic images and transfers the reliable knowledge to the target panoramic domain. Specifically, we first utilize Tangent Projection (TP) as it has less distortion and meanwhile slits the equirectangular projection (ERP) to patches with fixed FoV projection (FFP) to mimic the pinhole images. Both projections are shown effective in extracting knowledge from the source model. However, as the distinct projections make it less possible to directly transfer knowledge between domains, we then propose Reliable Panoramic Prototype Adaptation Module (RP2AM) to transfer knowledge at both prediction and prototype levels. RP$^2$AM selects the confident knowledge and integrates panoramic prototypes for reliable knowledge adaptation. Moreover, we introduce Cross-projection Dual Attention Module (CDAM), which better aligns the spatial and channel characteristics across projections at the feature level between domains. Both knowledge extraction and transfer processes are synchronously updated to reach the best performance. Extensive experiments on the synthetic and real-world benchmarks, including outdoor and indoor scenarios, demonstrate that our 360SFUDA++ achieves significantly better performance than prior SFUDA methods.
Read more4/26/2024

0
Multi-source Domain Adaptation for Panoramic Semantic Segmentation
Jing Jiang, Sicheng Zhao, Jiankun Zhu, Wenbo Tang, Zhaopan Xu, Jidong Yang, Pengfei Xu, Hongxun Yao
Panoramic semantic segmentation has received widespread attention recently due to its comprehensive 360degree field of view. However, labeling such images demands greater resources compared to pinhole images. As a result, many unsupervised domain adaptation methods for panoramic semantic segmentation have emerged, utilizing real pinhole images or low-cost synthetic panoramic images. But, the segmentation model lacks understanding of the panoramic structure when only utilizing real pinhole images, and it lacks perception of real-world scenes when only adopting synthetic panoramic images. Therefore, in this paper, we propose a new task of multi-source domain adaptation for panoramic semantic segmentation, aiming to utilize both real pinhole and synthetic panoramic images in the source domains, enabling the segmentation model to perform well on unlabeled real panoramic images in the target domain. Further, we propose Deformation Transform Aligner for Panoramic Semantic Segmentation (DTA4PASS), which converts all pinhole images in the source domains into panoramic-like images, and then aligns the converted source domains with the target domain. Specifically, DTA4PASS consists of two main components: Unpaired Semantic Morphing (USM) and Distortion Gating Alignment (DGA). Firstly, in USM, the Semantic Dual-view Discriminator (SDD) assists in training the diffeomorphic deformation network, enabling the effective transformation of pinhole images without paired panoramic views. Secondly, DGA assigns pinhole-like and panoramic-like features to each image by gating, and aligns these two features through uncertainty estimation. DTA4PASS outperforms the previous state-of-the-art methods by 1.92% and 2.19% on the outdoor and indoor multi-source domain adaptation scenarios, respectively. The source code will be released.
Read more8/30/2024
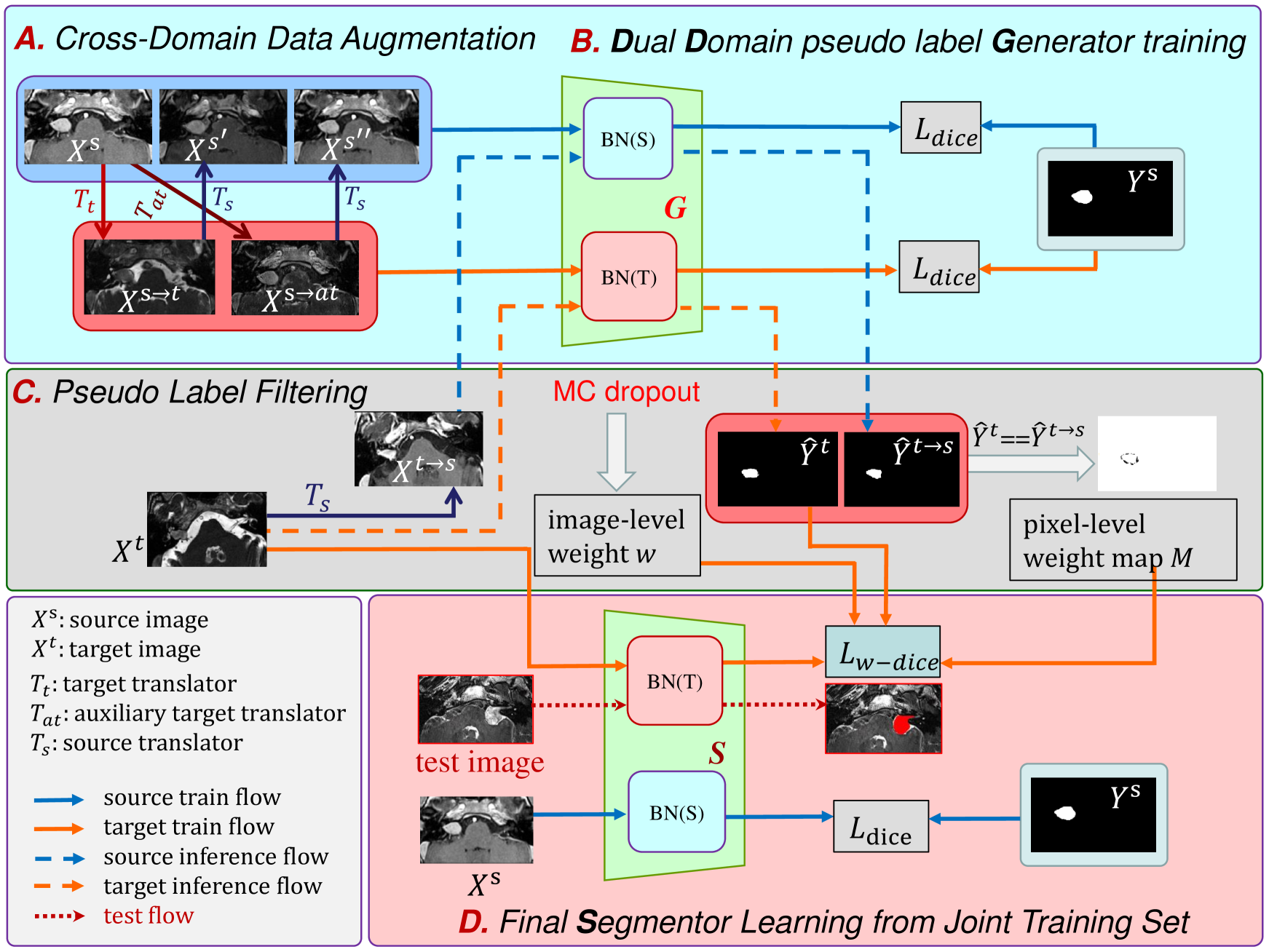
0
FPL+: Filtered Pseudo Label-based Unsupervised Cross-Modality Adaptation for 3D Medical Image Segmentation
Jianghao Wu, Dong Guo, Guotai Wang, Qiang Yue, Huijun Yu, Kang Li, Shaoting Zhang
Adapting a medical image segmentation model to a new domain is important for improving its cross-domain transferability, and due to the expensive annotation process, Unsupervised Domain Adaptation (UDA) is appealing where only unlabeled images are needed for the adaptation. Existing UDA methods are mainly based on image or feature alignment with adversarial training for regularization, and they are limited by insufficient supervision in the target domain. In this paper, we propose an enhanced Filtered Pseudo Label (FPL+)-based UDA method for 3D medical image segmentation. It first uses cross-domain data augmentation to translate labeled images in the source domain to a dual-domain training set consisting of a pseudo source-domain set and a pseudo target-domain set. To leverage the dual-domain augmented images to train a pseudo label generator, domain-specific batch normalization layers are used to deal with the domain shift while learning the domain-invariant structure features, generating high-quality pseudo labels for target-domain images. We then combine labeled source-domain images and target-domain images with pseudo labels to train a final segmentor, where image-level weighting based on uncertainty estimation and pixel-level weighting based on dual-domain consensus are proposed to mitigate the adverse effect of noisy pseudo labels. Experiments on three public multi-modal datasets for Vestibular Schwannoma, brain tumor and whole heart segmentation show that our method surpassed ten state-of-the-art UDA methods, and it even achieved better results than fully supervised learning in the target domain in some cases.
Read more4/9/2024
🤷
0
Train Till You Drop: Towards Stable and Robust Source-free Unsupervised 3D Domain Adaptation
Bjorn Michele, Alexandre Boulch, Tuan-Hung Vu, Gilles Puy, Renaud Marlet, Nicolas Courty
We tackle the challenging problem of source-free unsupervised domain adaptation (SFUDA) for 3D semantic segmentation. It amounts to performing domain adaptation on an unlabeled target domain without any access to source data; the available information is a model trained to achieve good performance on the source domain. A common issue with existing SFUDA approaches is that performance degrades after some training time, which is a by product of an under-constrained and ill-posed problem. We discuss two strategies to alleviate this issue. First, we propose a sensible way to regularize the learning problem. Second, we introduce a novel criterion based on agreement with a reference model. It is used (1) to stop the training when appropriate and (2) as validator to select hyperparameters without any knowledge on the target domain. Our contributions are easy to implement and readily amenable for all SFUDA methods, ensuring stable improvements over all baselines. We validate our findings on various 3D lidar settings, achieving state-of-the-art performance. The project repository (with code) is: github.com/valeoai/TTYD.
Read more9/9/2024