3D Diffuser Actor: Policy Diffusion with 3D Scene Representations

0
👨🏫
Sign in to get full access
Overview
- Diffusion policies are a type of conditional diffusion model that learns robot action distributions based on the robot and environment state.
- 3D robot policies use 3D scene feature representations from single or multiple camera views with depth information, which can generalize better across camera viewpoints than 2D representations.
- The paper presents 3D Diffuser Actor, a neural policy that fuses information from the 3D visual scene, language instruction, and robot proprioception to predict the noise in 3D robot pose trajectories.
Plain English Explanation
3D Diffuser Actor is a new approach to training robots to perform tasks. Traditional methods often use 2D camera images to determine the robot's actions, but this can be limited when the camera view changes. 3D Diffuser Actor overcomes this by using a 3D representation of the scene, which can better generalize across different camera angles.
The key innovation is a "3D denoising transformer" that combines information from the 3D scene, language instructions, and the robot's own sensor data. This allows the robot to predict how to smoothly move its joints (the "noise" in the robot's pose) to complete the task. The authors show that this 3D approach outperforms previous state-of-the-art methods on benchmark tasks, with substantial performance gains.
Importantly, 3D Diffuser Actor can also be used to control a real-world robot manipulator using just a few demonstration examples, showing its potential for practical applications. The thorough comparisons and ablation studies in the paper highlight how the design choices, like using 3D representations instead of 2D, are critical to the model's strong performance.
Technical Explanation
3D Diffuser Actor unifies two lines of work: diffusion policies, which are conditional diffusion models that learn robot action distributions, and 3D robot policies, which use 3D scene feature representations to better generalize across camera viewpoints.
The core of 3D Diffuser Actor is a novel 3D denoising transformer that fuses information from the 3D visual scene, a language instruction, and the robot's proprioception (internal sensor data) to predict the "noise" in 3D robot pose trajectories. This allows the model to generate smooth, natural-looking robot motions to complete a given task.
The authors evaluate 3D Diffuser Actor on the RLBench and CALVIN benchmarks, showing substantial performance gains over previous state-of-the-art methods. On RLBench, it achieves an 18.1% absolute improvement in a multi-view setup and a 13.1% gain in a single-view setup. On CALVIN, it provides a 9% relative improvement. Importantly, the model can also be used to control a real-world robot manipulator from just a few demonstration examples.
Through detailed comparisons and ablation studies, the paper demonstrates that 3D Diffuser Actor's design choices, such as using 3D representations instead of 2D, a diffusion-based objective instead of regression or classification, and a tokenized 3D scene embedding, are critical to its strong performance.
Critical Analysis
The paper presents a compelling approach to generalizable visuomotor policy learning, with thorough experimental validation and insightful comparisons to prior work. The use of 3D scene representations and the novel 3D denoising transformer are particularly noteworthy innovations.
One potential limitation is the reliance on depth information, which may not always be available in real-world scenarios. The authors mention the possibility of using monocular depth estimation, but further exploration of this would be valuable. Additionally, the paper does not extensively discuss the model's sample efficiency or the effort required to collect the demonstration examples for real-world robot control.
While the results on benchmark tasks are impressive, it would be interesting to see how 3D Diffuser Actor performs on more diverse and challenging robotic manipulation scenarios, especially those involving complex object interactions or long-term planning. Expanding the evaluation to a wider range of tasks could further validate the model's generalization capabilities.
Overall, the paper makes a strong contribution to the field of visuomotor policy learning, and the 3D Diffuser Actor approach represents a promising direction for improving the performance and generalization of robot control systems.
Conclusion
3D Diffuser Actor presents a novel neural policy that leverages 3D scene representations, language instructions, and robot proprioception to predict smooth 3D robot pose trajectories. By fusing this multifaceted information using a 3D denoising transformer, the model achieves state-of-the-art performance on benchmark tasks and demonstrates the ability to control a real-world robot manipulator from just a few demonstrations.
The paper's thorough comparisons and ablation studies highlight the critical importance of the 3D scene representation and the diffusion-based objective, which allow the model to generalize better than previous approaches. While the reliance on depth information and the need for demonstration data are potential limitations, the overall impact of 3D Diffuser Actor is significant, pushing the boundaries of generalizable visuomotor policy learning and paving the way for more capable and adaptable robot control systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
3D Diffuser Actor: Policy Diffusion with 3D Scene Representations
Tsung-Wei Ke, Nikolaos Gkanatsios, Katerina Fragkiadaki
Diffusion policies are conditional diffusion models that learn robot action distributions conditioned on the robot and environment state. They have recently shown to outperform both deterministic and alternative action distribution learning formulations. 3D robot policies use 3D scene feature representations aggregated from a single or multiple camera views using sensed depth. They have shown to generalize better than their 2D counterparts across camera viewpoints. We unify these two lines of work and present 3D Diffuser Actor, a neural policy equipped with a novel 3D denoising transformer that fuses information from the 3D visual scene, a language instruction and proprioception to predict the noise in noised 3D robot pose trajectories. 3D Diffuser Actor sets a new state-of-the-art on RLBench with an absolute performance gain of 18.1% over the current SOTA on a multi-view setup and an absolute gain of 13.1% on a single-view setup. On the CALVIN benchmark, it improves over the current SOTA by a 9% relative increase. It also learns to control a robot manipulator in the real world from a handful of demonstrations. Through thorough comparisons with the current SOTA policies and ablations of our model, we show 3D Diffuser Actor's design choices dramatically outperform 2D representations, regression and classification objectives, absolute attentions, and holistic non-tokenized 3D scene embeddings.
Read more7/26/2024
0
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, Huazhe Xu
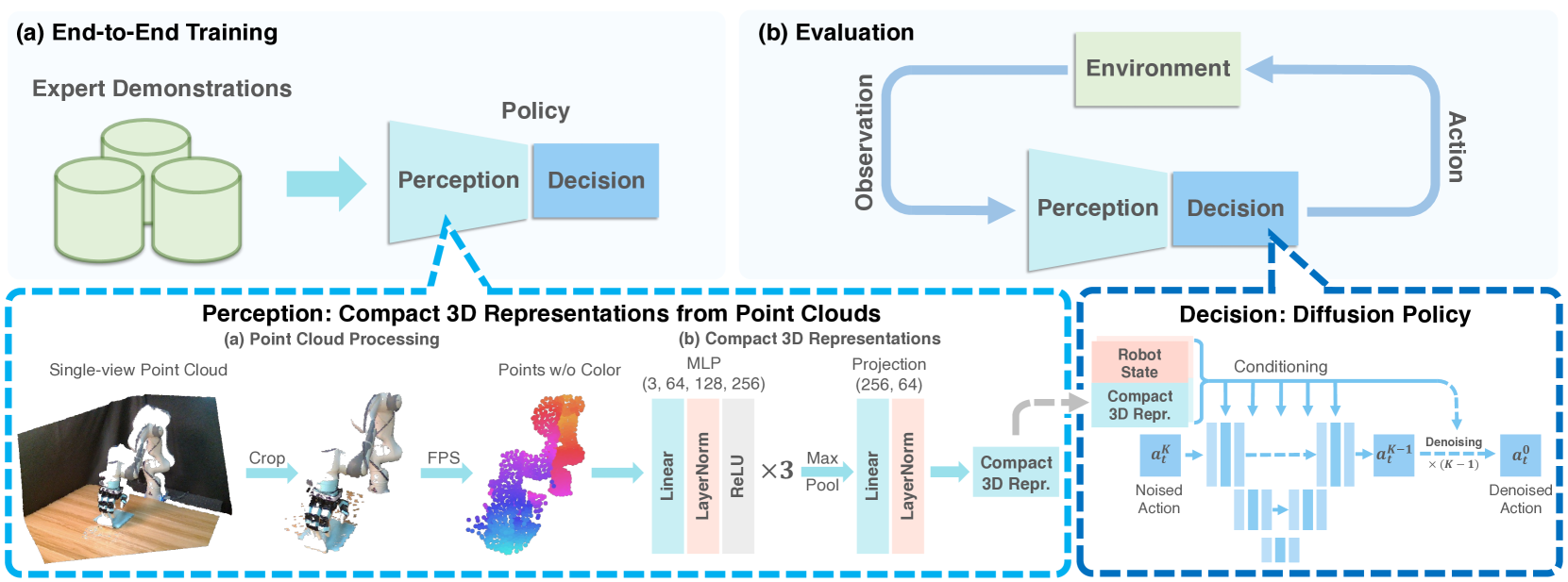
Imitation learning provides an efficient way to teach robots dexterous skills; however, learning complex skills robustly and generalizablely usually consumes large amounts of human demonstrations. To tackle this challenging problem, we present 3D Diffusion Policy (DP3), a novel visual imitation learning approach that incorporates the power of 3D visual representations into diffusion policies, a class of conditional action generative models. The core design of DP3 is the utilization of a compact 3D visual representation, extracted from sparse point clouds with an efficient point encoder. In our experiments involving 72 simulation tasks, DP3 successfully handles most tasks with just 10 demonstrations and surpasses baselines with a 24.2% relative improvement. In 4 real robot tasks, DP3 demonstrates precise control with a high success rate of 85%, given only 40 demonstrations of each task, and shows excellent generalization abilities in diverse aspects, including space, viewpoint, appearance, and instance. Interestingly, in real robot experiments, DP3 rarely violates safety requirements, in contrast to baseline methods which frequently do, necessitating human intervention. Our extensive evaluation highlights the critical importance of 3D representations in real-world robot learning. Videos, code, and data are available on https://3d-diffusion-policy.github.io .
Read more5/29/2024

0
Sparse Diffusion Policy: A Sparse, Reusable, and Flexible Policy for Robot Learning
Yixiao Wang, Yifei Zhang, Mingxiao Huo, Ran Tian, Xiang Zhang, Yichen Xie, Chenfeng Xu, Pengliang Ji, Wei Zhan, Mingyu Ding, Masayoshi Tomizuka
The increasing complexity of tasks in robotics demands efficient strategies for multitask and continual learning. Traditional models typically rely on a universal policy for all tasks, facing challenges such as high computational costs and catastrophic forgetting when learning new tasks. To address these issues, we introduce a sparse, reusable, and flexible policy, Sparse Diffusion Policy (SDP). By adopting Mixture of Experts (MoE) within a transformer-based diffusion policy, SDP selectively activates experts and skills, enabling efficient and task-specific learning without retraining the entire model. SDP not only reduces the burden of active parameters but also facilitates the seamless integration and reuse of experts across various tasks. Extensive experiments on diverse tasks in both simulations and real world show that SDP 1) excels in multitask scenarios with negligible increases in active parameters, 2) prevents forgetting in continual learning of new tasks, and 3) enables efficient task transfer, offering a promising solution for advanced robotic applications. Demos and codes can be found in https://forrest-110.github.io/sparse_diffusion_policy/.
Read more7/2/2024

0
PDP: Physics-Based Character Animation via Diffusion Policy
Takara E. Truong, Michael Piseno, Zhaoming Xie, C. Karen Liu
Generating diverse and realistic human motion that can physically interact with an environment remains a challenging research area in character animation. Meanwhile, diffusion-based methods, as proposed by the robotics community, have demonstrated the ability to capture highly diverse and multi-modal skills. However, naively training a diffusion policy often results in unstable motions for high-frequency, under-actuated control tasks like bipedal locomotion due to rapidly accumulating compounding errors, pushing the agent away from optimal training trajectories. The key idea lies in using RL policies not just for providing optimal trajectories but for providing corrective actions in sub-optimal states, giving the policy a chance to correct for errors caused by environmental stimulus, model errors, or numerical errors in simulation. Our method, Physics-Based Character Animation via Diffusion Policy (PDP), combines reinforcement learning (RL) and behavior cloning (BC) to create a robust diffusion policy for physics-based character animation. We demonstrate PDP on perturbation recovery, universal motion tracking, and physics-based text-to-motion synthesis.
Read more6/4/2024