Sparse Diffusion Policy: A Sparse, Reusable, and Flexible Policy for Robot Learning

0

Sign in to get full access
Overview
- This paper introduces a new reinforcement learning technique called the Sparse Diffusion Policy (SDP), which is designed to be a sparse, reusable, and flexible policy for robot learning.
- The SDP approach aims to learn compact and expressive policies that can be efficiently deployed and adapted to new tasks or environments.
- The key ideas behind SDP include leveraging diffusion models for policy representation, sparse activation patterns, and a modular design that enables reusability and customization.
Plain English Explanation
The paper describes a new way for robots to learn how to perform tasks, called the Sparse Diffusion Policy (SDP). The main goal of SDP is to create policies - the decision-making algorithms that control a robot's actions - that are efficient, flexible, and can be reused across different tasks.
The researchers take inspiration from a machine learning technique called diffusion models, which can generate highly realistic images by gradually transforming random noise into structured outputs. In a similar way, the SDP approach learns a compact policy representation that can flexibly generate the right actions for a robot in different situations.
A key aspect of SDP is that the policy is "sparse", meaning it only activates a small number of its internal components at a time. This makes the policy more efficient and easier to understand than traditional, dense policies. It also allows the policy to be easily modified and reused for new tasks, rather than having to be trained from scratch each time.
The modular design of SDP means that the policy can be customized and combined with other components to handle a wide variety of robot learning problems. This flexibility is important, as robots often need to adapt to new environments and tasks, and reusing existing knowledge can make the learning process much faster and more effective.
Technical Explanation
The Sparse Diffusion Policy (SDP) introduced in this paper is a new approach to reinforcement learning for robot control tasks. The key innovations of SDP include:
-
Diffusion-based Policy Representation: The policy is represented using a diffusion model, which learns to gradually transform random noise into structured, task-relevant actions. This allows the policy to be compact and expressive, capturing the complex dynamics of robot control.
-
Sparse Activation Patterns: The policy activates only a sparse subset of its internal components at any given time. This sparsity improves the efficiency and interpretability of the policy, and enables easier adaptation to new tasks.
-
Modular and Reusable Design: SDP is designed with a modular architecture, allowing different components of the policy to be easily swapped, combined, or fine-tuned for different robot learning problems. This promotes reusability and flexibility.
The paper presents experiments demonstrating the advantages of SDP over traditional dense policies in terms of sample efficiency, task generalization, and transfer learning. The authors show that SDP can learn complex robot manipulation skills from scratch, and can also be easily adapted to new tasks by fine-tuning only a small subset of the policy's parameters.
Critical Analysis
The Sparse Diffusion Policy introduced in this paper represents an interesting and promising approach to reinforcement learning for robot control. The key strengths of the SDP method include its efficient and interpretable policy representation, as well as its modular and reusable design.
One potential limitation of the current work is that the experiments are focused on relatively simple robot manipulation tasks. It would be valuable to see how SDP performs on more complex, multi-step robotic tasks, or in environments with higher degrees of uncertainty and dynamics. Additionally, the paper does not provide a thorough analysis of the computational and memory requirements of SDP, which would be an important consideration for real-world robotic applications.
Another area for further research could be exploring ways to further improve the reusability and transfer learning capabilities of SDP. The modular design is a good start, but additional techniques like meta-learning or hierarchical policy structures could potentially enhance the ability to quickly adapt the policy to new situations.
Overall, the Sparse Diffusion Policy is a promising direction for reinforcement learning in robotics, and the ideas presented in this paper warrant further investigation and development.
Conclusion
The Sparse Diffusion Policy (SDP) introduced in this paper represents an innovative approach to robot learning that aims to address key limitations of traditional reinforcement learning techniques. By leveraging diffusion models for policy representation, sparse activation patterns, and a modular design, SDP can learn compact and flexible policies that can be efficiently deployed and adapted to new tasks or environments.
The experiments presented in the paper demonstrate the potential of SDP to learn complex robotic skills from scratch, as well as to enable effective transfer learning by fine-tuning only a subset of the policy's parameters. These capabilities could have significant implications for the development of more versatile and autonomous robotic systems that can quickly adapt to new challenges.
While the current work focuses on relatively simple manipulation tasks, the core ideas of SDP suggest that it could be a valuable tool for advancing the state-of-the-art in robot learning, with further research and development potentially leading to even more powerful and flexible policy representations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sparse Diffusion Policy: A Sparse, Reusable, and Flexible Policy for Robot Learning
Yixiao Wang, Yifei Zhang, Mingxiao Huo, Ran Tian, Xiang Zhang, Yichen Xie, Chenfeng Xu, Pengliang Ji, Wei Zhan, Mingyu Ding, Masayoshi Tomizuka
The increasing complexity of tasks in robotics demands efficient strategies for multitask and continual learning. Traditional models typically rely on a universal policy for all tasks, facing challenges such as high computational costs and catastrophic forgetting when learning new tasks. To address these issues, we introduce a sparse, reusable, and flexible policy, Sparse Diffusion Policy (SDP). By adopting Mixture of Experts (MoE) within a transformer-based diffusion policy, SDP selectively activates experts and skills, enabling efficient and task-specific learning without retraining the entire model. SDP not only reduces the burden of active parameters but also facilitates the seamless integration and reuse of experts across various tasks. Extensive experiments on diverse tasks in both simulations and real world show that SDP 1) excels in multitask scenarios with negligible increases in active parameters, 2) prevents forgetting in continual learning of new tasks, and 3) enables efficient task transfer, offering a promising solution for advanced robotic applications. Demos and codes can be found in https://forrest-110.github.io/sparse_diffusion_policy/.
Read more7/2/2024
0
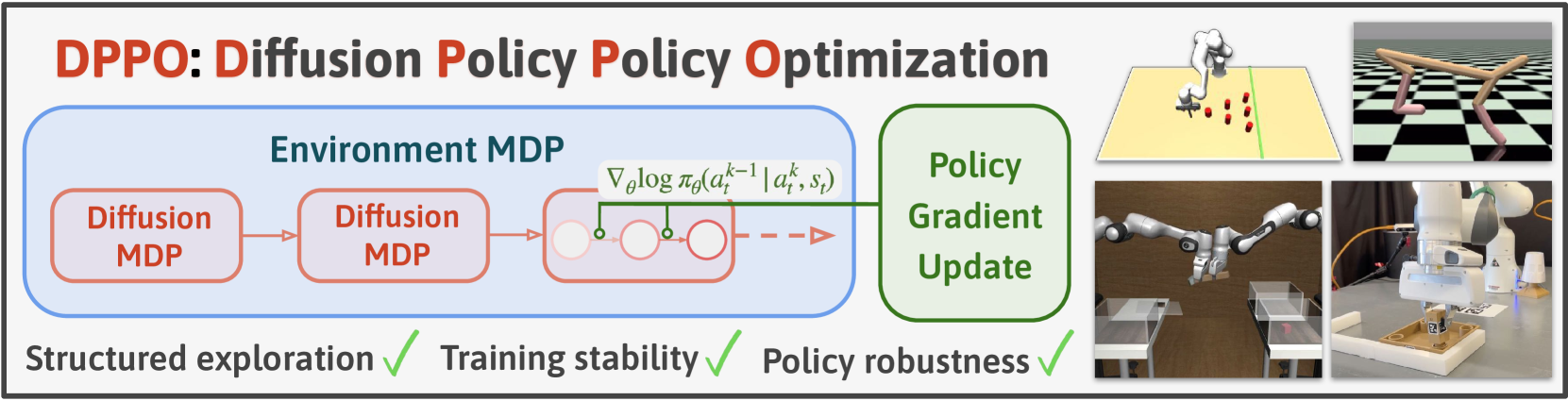
Diffusion Policy Policy Optimization
Allen Z. Ren, Justin Lidard, Lars L. Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, Max Simchowitz
We introduce Diffusion Policy Policy Optimization, DPPO, an algorithmic framework including best practices for fine-tuning diffusion-based policies (e.g. Diffusion Policy) in continuous control and robot learning tasks using the policy gradient (PG) method from reinforcement learning (RL). PG methods are ubiquitous in training RL policies with other policy parameterizations; nevertheless, they had been conjectured to be less efficient for diffusion-based policies. Surprisingly, we show that DPPO achieves the strongest overall performance and efficiency for fine-tuning in common benchmarks compared to other RL methods for diffusion-based policies and also compared to PG fine-tuning of other policy parameterizations. Through experimental investigation, we find that DPPO takes advantage of unique synergies between RL fine-tuning and the diffusion parameterization, leading to structured and on-manifold exploration, stable training, and strong policy robustness. We further demonstrate the strengths of DPPO in a range of realistic settings, including simulated robotic tasks with pixel observations, and via zero-shot deployment of simulation-trained policies on robot hardware in a long-horizon, multi-stage manipulation task. Website with code: diffusion-ppo.github.io
Read more9/4/2024

0
Variational Distillation of Diffusion Policies into Mixture of Experts
Hongyi Zhou, Denis Blessing, Ge Li, Onur Celik, Xiaogang Jia, Gerhard Neumann, Rudolf Lioutikov
This work introduces Variational Diffusion Distillation (VDD), a novel method that distills denoising diffusion policies into Mixtures of Experts (MoE) through variational inference. Diffusion Models are the current state-of-the-art in generative modeling due to their exceptional ability to accurately learn and represent complex, multi-modal distributions. This ability allows Diffusion Models to replicate the inherent diversity in human behavior, making them the preferred models in behavior learning such as Learning from Human Demonstrations (LfD). However, diffusion models come with some drawbacks, including the intractability of likelihoods and long inference times due to their iterative sampling process. The inference times, in particular, pose a significant challenge to real-time applications such as robot control. In contrast, MoEs effectively address the aforementioned issues while retaining the ability to represent complex distributions but are notoriously difficult to train. VDD is the first method that distills pre-trained diffusion models into MoE models, and hence, combines the expressiveness of Diffusion Models with the benefits of Mixture Models. Specifically, VDD leverages a decompositional upper bound of the variational objective that allows the training of each expert separately, resulting in a robust optimization scheme for MoEs. VDD demonstrates across nine complex behavior learning tasks, that it is able to: i) accurately distill complex distributions learned by the diffusion model, ii) outperform existing state-of-the-art distillation methods, and iii) surpass conventional methods for training MoE.
Read more6/19/2024

0
Learning Multimodal Behaviors from Scratch with Diffusion Policy Gradient
Zechu Li, Rickmer Krohn, Tao Chen, Anurag Ajay, Pulkit Agrawal, Georgia Chalvatzaki
Deep reinforcement learning (RL) algorithms typically parameterize the policy as a deep network that outputs either a deterministic action or a stochastic one modeled as a Gaussian distribution, hence restricting learning to a single behavioral mode. Meanwhile, diffusion models emerged as a powerful framework for multimodal learning. However, the use of diffusion policies in online RL is hindered by the intractability of policy likelihood approximation, as well as the greedy objective of RL methods that can easily skew the policy to a single mode. This paper presents Deep Diffusion Policy Gradient (DDiffPG), a novel actor-critic algorithm that learns from scratch multimodal policies parameterized as diffusion models while discovering and maintaining versatile behaviors. DDiffPG explores and discovers multiple modes through off-the-shelf unsupervised clustering combined with novelty-based intrinsic motivation. DDiffPG forms a multimodal training batch and utilizes mode-specific Q-learning to mitigate the inherent greediness of the RL objective, ensuring the improvement of the diffusion policy across all modes. Our approach further allows the policy to be conditioned on mode-specific embeddings to explicitly control the learned modes. Empirical studies validate DDiffPG's capability to master multimodal behaviors in complex, high-dimensional continuous control tasks with sparse rewards, also showcasing proof-of-concept dynamic online replanning when navigating mazes with unseen obstacles.
Read more6/4/2024