3D Foundation Models Enable Simultaneous Geometry and Pose Estimation of Grasped Objects

0

Sign in to get full access
Overview
- This research paper introduces a novel approach to simultaneously estimating the geometry and pose of objects grasped by a robot hand.
- The proposed method uses "3D foundation models" - powerful deep learning models trained on large datasets of 3D object data - to enable this dual estimation task.
- The researchers demonstrate the effectiveness of their approach on a range of experiments, showcasing its ability to accurately reconstruct the 3D shape and 6-DoF pose of grasped objects.
Plain English Explanation
The paper describes a new way for robots to understand the 3D objects they are holding. When a robot grasps an object, it's important for the robot to know both the exact shape of the object as well as its precise position and orientation in 3D space. This information helps the robot manipulate the object accurately.
The researchers developed a system that can estimate the 3D geometry and 6-degree-of-freedom (6-DoF) pose of an object simultaneously, using powerful machine learning models called "3D foundation models." These models are trained on huge datasets of 3D object information, giving them a deep understanding of 3D shapes.
By applying these 3D foundation models to the task of grasping, the researchers show their system can accurately reconstruct the 3D shape and position/orientation of a wide variety of objects a robot is holding. This dual capability - estimating both geometry and pose - is a significant advance that can improve a robot's ability to interact with and manipulate objects in the real world.
Technical Explanation
The paper introduces a novel approach for simultaneous geometry and pose estimation of grasped objects, leveraging the power of "3D foundation models." These are large-scale deep learning models that have been pre-trained on massive datasets of 3D object data, allowing them to capture rich representations of 3D shape and structure.
The researchers demonstrate how these 3D foundation models can be adapted and applied to the task of estimating the 6-DoF pose and 3D geometry of objects grasped by a robot hand. Their approach combines a neural network that predicts the object's 3D shape with another network that estimates the object's 6-DoF pose relative to the robot's hand.
Through extensive experiments, the paper shows this dual estimation capability outperforms previous methods that could only estimate either the geometry or the pose, but not both simultaneously. The researchers also show their approach can handle objects moving freely and can jointly reconstruct the object shape and grasp configuration.
Critical Analysis
The paper presents a compelling approach that demonstrates the power of 3D foundation models for simultaneous 3D shape and pose estimation. However, the authors acknowledge some limitations, such as the need for a known initial hand-object pose and the potential for errors in the estimated 3D geometry to affect the pose estimation.
Additionally, the experiments focus on relatively simple, household objects. It would be valuable to see how the method performs on more complex, deformable, or occluded objects that might present greater challenges for 3D reconstruction and pose estimation.
Further research could also explore ways to integrate local geometric cues from the hand-object interaction to potentially improve the overall estimation accuracy. Incorporating feedback loops between the geometry and pose estimation components could also be a fruitful direction.
Conclusion
This paper introduces an innovative approach that leverages the power of 3D foundation models to enable simultaneous estimation of an object's 3D shape and 6-DoF pose when grasped by a robot hand. The demonstrated capabilities represent a significant advancement in robot perception and manipulation, with the potential to enhance a wide range of robotic applications that involve interacting with and manipulating objects in the physical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
3D Foundation Models Enable Simultaneous Geometry and Pose Estimation of Grasped Objects
Weiming Zhi, Haozhan Tang, Tianyi Zhang, Matthew Johnson-Roberson
Humans have the remarkable ability to use held objects as tools to interact with their environment. For this to occur, humans internally estimate how hand movements affect the object's movement. We wish to endow robots with this capability. We contribute methodology to jointly estimate the geometry and pose of objects grasped by a robot, from RGB images captured by an external camera. Notably, our method transforms the estimated geometry into the robot's coordinate frame, while not requiring the extrinsic parameters of the external camera to be calibrated. Our approach leverages 3D foundation models, large models pre-trained on huge datasets for 3D vision tasks, to produce initial estimates of the in-hand object. These initial estimations do not have physically correct scales and are in the camera's frame. Then, we formulate, and efficiently solve, a coordinate-alignment problem to recover accurate scales, along with a transformation of the objects to the coordinate frame of the robot. Forward kinematics mappings can subsequently be defined from the manipulator's joint angles to specified points on the object. These mappings enable the estimation of points on the held object at arbitrary configurations, enabling robot motion to be designed with respect to coordinates on the grasped objects. We empirically evaluate our approach on a robot manipulator holding a diverse set of real-world objects.
Read more7/16/2024
0
CenterGrasp: Object-Aware Implicit Representation Learning for Simultaneous Shape Reconstruction and 6-DoF Grasp Estimation
Eugenio Chisari, Nick Heppert, Tim Welschehold, Wolfram Burgard, Abhinav Valada
Reliable object grasping is a crucial capability for autonomous robots. However, many existing grasping approaches focus on general clutter removal without explicitly modeling objects and thus only relying on the visible local geometry. We introduce CenterGrasp, a novel framework that combines object awareness and holistic grasping. CenterGrasp learns a general object prior by encoding shapes and valid grasps in a continuous latent space. It consists of an RGB-D image encoder that leverages recent advances to detect objects and infer their pose and latent code, and a decoder to predict shape and grasps for each object in the scene. We perform extensive experiments on simulated as well as real-world cluttered scenes and demonstrate strong scene reconstruction and 6-DoF grasp-pose estimation performance. Compared to the state of the art, CenterGrasp achieves an improvement of 38.5 mm in shape reconstruction and 33 percentage points on average in grasp success. We make the code and trained models publicly available at http://centergrasp.cs.uni-freiburg.de.
Read more4/8/2024
0
Grasping Diverse Objects with Simulated Humanoids
Zhengyi Luo, Jinkun Cao, Sammy Christen, Alexander Winkler, Kris Kitani, Weipeng Xu
We present a method for controlling a simulated humanoid to grasp an object and move it to follow an object trajectory. Due to the challenges in controlling a humanoid with dexterous hands, prior methods often use a disembodied hand and only consider vertical lifts or short trajectories. This limited scope hampers their applicability for object manipulation required for animation and simulation. To close this gap, we learn a controller that can pick up a large number (>1200) of objects and carry them to follow randomly generated trajectories. Our key insight is to leverage a humanoid motion representation that provides human-like motor skills and significantly speeds up training. Using only simplistic reward, state, and object representations, our method shows favorable scalability on diverse object and trajectories. For training, we do not need dataset of paired full-body motion and object trajectories. At test time, we only require the object mesh and desired trajectories for grasping and transporting. To demonstrate the capabilities of our method, we show state-of-the-art success rates in following object trajectories and generalizing to unseen objects. Code and models will be released.
Read more7/17/2024
0
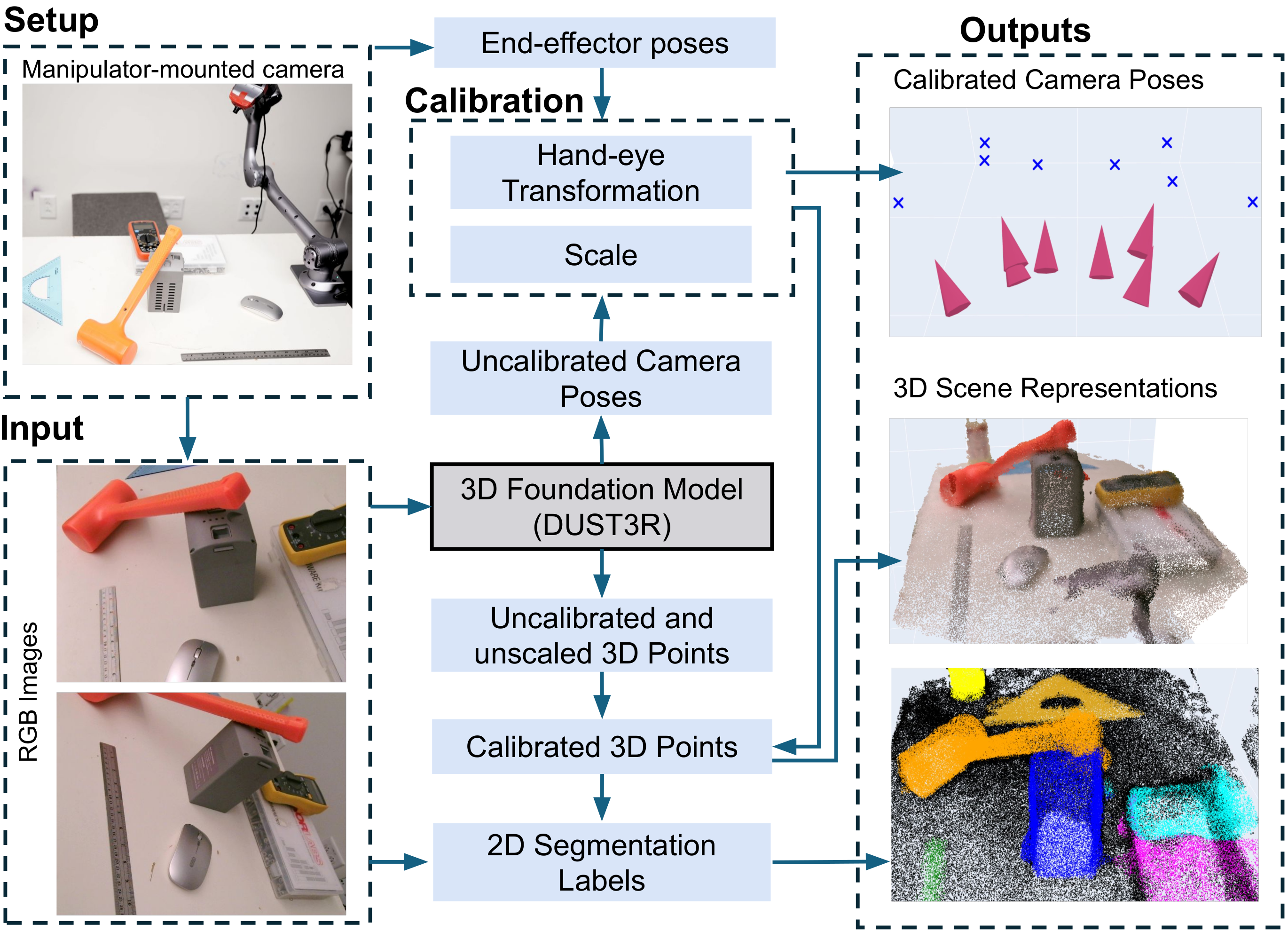
Unifying Scene Representation and Hand-Eye Calibration with 3D Foundation Models
Weiming Zhi, Haozhan Tang, Tianyi Zhang, Matthew Johnson-Roberson
Representing the environment is a central challenge in robotics, and is essential for effective decision-making. Traditionally, before capturing images with a manipulator-mounted camera, users need to calibrate the camera using a specific external marker, such as a checkerboard or AprilTag. However, recent advances in computer vision have led to the development of emph{3D foundation models}. These are large, pre-trained neural networks that can establish fast and accurate multi-view correspondences with very few images, even in the absence of rich visual features. This paper advocates for the integration of 3D foundation models into scene representation approaches for robotic systems equipped with manipulator-mounted RGB cameras. Specifically, we propose the Joint Calibration and Representation (JCR) method. JCR uses RGB images, captured by a manipulator-mounted camera, to simultaneously construct an environmental representation and calibrate the camera relative to the robot's end-effector, in the absence of specific calibration markers. The resulting 3D environment representation is aligned with the robot's coordinate frame and maintains physically accurate scales. We demonstrate that JCR can build effective scene representations using a low-cost RGB camera attached to a manipulator, without prior calibration.
Read more4/19/2024