Unifying Scene Representation and Hand-Eye Calibration with 3D Foundation Models

0
Sign in to get full access
Overview
- This research paper explores the unification of scene representation and hand-eye calibration using 3D foundation models.
- The paper proposes a novel approach that leverages the capabilities of 3D foundation models to enable dense scene reconstruction and hand-eye calibration in a unified manner.
- The research aims to address the challenges associated with traditional methods that often treat these tasks separately, leading to suboptimal performance and increased complexity.
Plain English Explanation
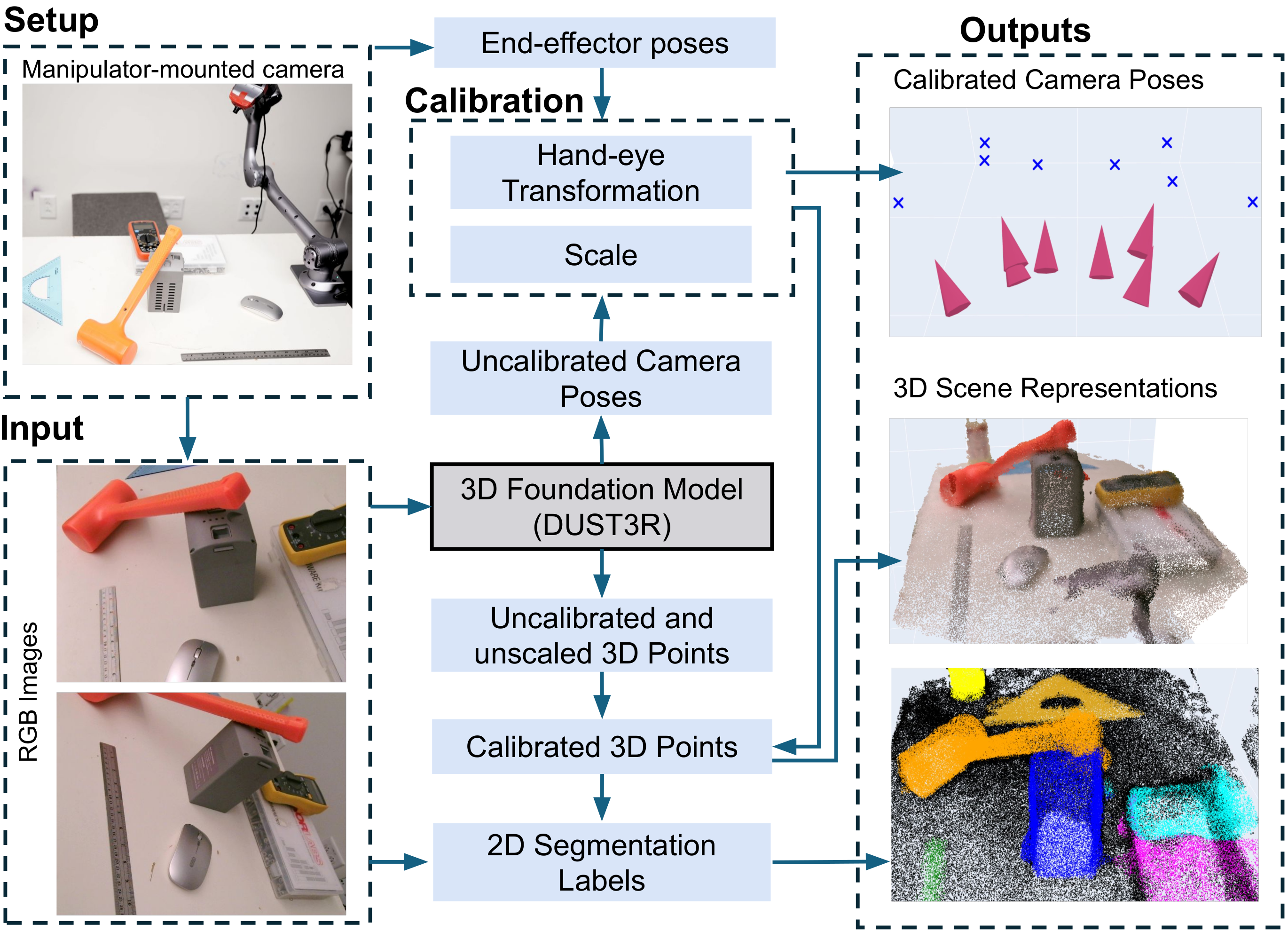
The paper presents a new way to tackle two important computer vision problems: reconstructing 3D scenes from images and calibrating the relationship between a robot's hand and its camera. Traditionally, these tasks have been approached separately, which can be inefficient and lead to problems.
The researchers' key idea is to use powerful 3D "foundation models" - machine learning models that have been trained on a vast amount of 3D data - to tackle both tasks simultaneously. These models can understand the 3D structure of a scene and the spatial relationships between objects, which is crucial for both reconstructing the scene and calibrating the hand-eye system.
By unifying these two tasks, the approach can be more efficient and effective than traditional methods that treat them independently. This could have important applications in robotics, where accurate hand-eye calibration is essential for manipulating objects in the real world based on camera input.
Technical Explanation
The paper introduces a novel framework that leverages 3D foundation models to enable dense scene reconstruction and hand-eye calibration in a unified manner. Traditional approaches have typically addressed these two tasks separately, leading to increased complexity and suboptimal performance.
The proposed method utilizes the powerful 3D understanding capabilities of 3D foundation models, such as those explored in previous research, to jointly model the scene geometry and the hand-eye relationship. This is achieved by training the foundation model on a diverse dataset of 3D scenes, including both hand-held objects and wider environments.
The key innovation of the paper is the development of a training procedure that allows the 3D foundation model to learn both the scene representation and the hand-eye calibration parameters simultaneously. This is in contrast to previous methods that have typically addressed these tasks sequentially or in isolation.
The authors demonstrate the effectiveness of their approach through extensive experiments, showcasing improvements in both scene reconstruction quality and hand-eye calibration accuracy compared to state-of-the-art baselines. The unified framework can potentially simplify and enhance a wide range of robotics applications that rely on accurate 3D understanding and hand-eye coordination, such as visual tracking and control of quadrotors.
Critical Analysis
The paper presents a compelling approach that unifies scene representation and hand-eye calibration using 3D foundation models. However, the authors acknowledge several limitations and areas for future research.
One key limitation is the reliance on a diverse, high-quality dataset of 3D scenes and hand-eye interactions. The performance of the proposed method may be sensitive to the quantity and quality of the training data, which can be challenging to acquire in practice, especially for complex robotic applications.
Additionally, the authors note that the computational and memory requirements of the 3D foundation model may pose challenges for real-time deployment, particularly in resource-constrained environments. Exploring ways to optimize the model's efficiency or develop lightweight variants could be an important area for future research.
Another potential concern is the generalization capabilities of the unified framework. The authors demonstrate its effectiveness on a range of test scenarios, but it remains to be seen how well the approach would scale to more diverse and complex real-world settings, where the distribution of input data may differ significantly from the training distribution.
Despite these limitations, the paper presents a novel and promising direction for integrating 3D understanding and hand-eye coordination, which could have significant implications for advancing robotic perception and manipulation capabilities. Further research and refinement of the proposed approach, as well as exploration of its broader applicability, could lead to valuable contributions to the field of 3D computer vision and robotics.
Conclusion
This research paper introduces a unified framework that leverages 3D foundation models to jointly address the challenges of scene representation and hand-eye calibration. By combining these two essential capabilities, the proposed approach has the potential to simplify and enhance a wide range of robotic applications that rely on accurate 3D understanding and spatial awareness.
The key innovation is the development of a training procedure that allows the 3D foundation model to learn both the scene geometry and the hand-eye relationship simultaneously, in contrast to traditional methods that have treated these tasks separately. The authors demonstrate the effectiveness of their approach through extensive experiments, showcasing improvements in both scene reconstruction and hand-eye calibration performance.
While the paper acknowledges several limitations, such as the reliance on high-quality training data and computational efficiency, the presented research represents an important step towards more integrated and versatile computer vision and robotics systems. Further exploration and refinement of this unified framework could lead to significant advancements in the field, with potential applications ranging from enhanced robotic manipulation to more seamless human-machine interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unifying Scene Representation and Hand-Eye Calibration with 3D Foundation Models
Weiming Zhi, Haozhan Tang, Tianyi Zhang, Matthew Johnson-Roberson
Representing the environment is a central challenge in robotics, and is essential for effective decision-making. Traditionally, before capturing images with a manipulator-mounted camera, users need to calibrate the camera using a specific external marker, such as a checkerboard or AprilTag. However, recent advances in computer vision have led to the development of emph{3D foundation models}. These are large, pre-trained neural networks that can establish fast and accurate multi-view correspondences with very few images, even in the absence of rich visual features. This paper advocates for the integration of 3D foundation models into scene representation approaches for robotic systems equipped with manipulator-mounted RGB cameras. Specifically, we propose the Joint Calibration and Representation (JCR) method. JCR uses RGB images, captured by a manipulator-mounted camera, to simultaneously construct an environmental representation and calibrate the camera relative to the robot's end-effector, in the absence of specific calibration markers. The resulting 3D environment representation is aligned with the robot's coordinate frame and maintains physically accurate scales. We demonstrate that JCR can build effective scene representations using a low-cost RGB camera attached to a manipulator, without prior calibration.
Read more4/19/2024

0
3D Foundation Models Enable Simultaneous Geometry and Pose Estimation of Grasped Objects
Weiming Zhi, Haozhan Tang, Tianyi Zhang, Matthew Johnson-Roberson
Humans have the remarkable ability to use held objects as tools to interact with their environment. For this to occur, humans internally estimate how hand movements affect the object's movement. We wish to endow robots with this capability. We contribute methodology to jointly estimate the geometry and pose of objects grasped by a robot, from RGB images captured by an external camera. Notably, our method transforms the estimated geometry into the robot's coordinate frame, while not requiring the extrinsic parameters of the external camera to be calibrated. Our approach leverages 3D foundation models, large models pre-trained on huge datasets for 3D vision tasks, to produce initial estimates of the in-hand object. These initial estimations do not have physically correct scales and are in the camera's frame. Then, we formulate, and efficiently solve, a coordinate-alignment problem to recover accurate scales, along with a transformation of the objects to the coordinate frame of the robot. Forward kinematics mappings can subsequently be defined from the manipulator's joint angles to specified points on the object. These mappings enable the estimation of points on the held object at arbitrary configurations, enabling robot motion to be designed with respect to coordinates on the grasped objects. We empirically evaluate our approach on a robot manipulator holding a diverse set of real-world objects.
Read more7/16/2024

0
Unifying 3D Representation and Control of Diverse Robots with a Single Camera
Sizhe Lester Li, Annan Zhang, Boyuan Chen, Hanna Matusik, Chao Liu, Daniela Rus, Vincent Sitzmann
Mirroring the complex structures and diverse functions of natural organisms is a long-standing challenge in robotics. Modern fabrication techniques have dramatically expanded feasible hardware, yet deploying these systems requires control software to translate desired motions into actuator commands. While conventional robots can easily be modeled as rigid links connected via joints, it remains an open challenge to model and control bio-inspired robots that are often multi-material or soft, lack sensing capabilities, and may change their material properties with use. Here, we introduce Neural Jacobian Fields, an architecture that autonomously learns to model and control robots from vision alone. Our approach makes no assumptions about the robot's materials, actuation, or sensing, requires only a single camera for control, and learns to control the robot without expert intervention by observing the execution of random commands. We demonstrate our method on a diverse set of robot manipulators, varying in actuation, materials, fabrication, and cost. Our approach achieves accurate closed-loop control and recovers the causal dynamic structure of each robot. By enabling robot control with a generic camera as the only sensor, we anticipate our work will dramatically broaden the design space of robotic systems and serve as a starting point for lowering the barrier to robotic automation.
Read more7/12/2024

0
New!CtRNet-X: Camera-to-Robot Pose Estimation in Real-world Conditions Using a Single Camera
Jingpei Lu, Zekai Liang, Tristin Xie, Florian Ritcher, Shan Lin, Sainan Liu, Michael C. Yip
Camera-to-robot calibration is crucial for vision-based robot control and requires effort to make it accurate. Recent advancements in markerless pose estimation methods have eliminated the need for time-consuming physical setups for camera-to-robot calibration. While the existing markerless pose estimation methods have demonstrated impressive accuracy without the need for cumbersome setups, they rely on the assumption that all the robot joints are visible within the camera's field of view. However, in practice, robots usually move in and out of view, and some portion of the robot may stay out-of-frame during the whole manipulation task due to real-world constraints, leading to a lack of sufficient visual features and subsequent failure of these approaches. To address this challenge and enhance the applicability to vision-based robot control, we propose a novel framework capable of estimating the robot pose with partially visible robot manipulators. Our approach leverages the Vision-Language Models for fine-grained robot components detection, and integrates it into a keypoint-based pose estimation network, which enables more robust performance in varied operational conditions. The framework is evaluated on both public robot datasets and self-collected partial-view datasets to demonstrate our robustness and generalizability. As a result, this method is effective for robot pose estimation in a wider range of real-world manipulation scenarios.
Read more9/17/2024