3D-GPT: Procedural 3D Modeling with Large Language Models
2310.12945
0
0
💬
Abstract
In the pursuit of efficient automated content creation, procedural generation, leveraging modifiable parameters and rule-based systems, emerges as a promising approach. Nonetheless, it could be a demanding endeavor, given its intricate nature necessitating a deep understanding of rules, algorithms, and parameters. To reduce workload, we introduce 3D-GPT, a framework utilizing large language models~(LLMs) for instruction-driven 3D modeling. 3D-GPT positions LLMs as proficient problem solvers, dissecting the procedural 3D modeling tasks into accessible segments and appointing the apt agent for each task. 3D-GPT integrates three core agents: the task dispatch agent, the conceptualization agent, and the modeling agent. They collaboratively achieve two objectives. First, it enhances concise initial scene descriptions, evolving them into detailed forms while dynamically adapting the text based on subsequent instructions. Second, it integrates procedural generation, extracting parameter values from enriched text to effortlessly interface with 3D software for asset creation. Our empirical investigations confirm that 3D-GPT not only interprets and executes instructions, delivering reliable results but also collaborates effectively with human designers. Furthermore, it seamlessly integrates with Blender, unlocking expanded manipulation possibilities. Our work highlights the potential of LLMs in 3D modeling, offering a basic framework for future advancements in scene generation and animation.
Create account to get full access
Overview
- Introduces a framework called 3D-GPT that leverages large language models (LLMs) for instruction-driven 3D modeling
- Aims to enhance the efficiency of 3D content creation and procedural generation by integrating LLMs as problem-solvers
- 3D-GPT consists of three core agents: task dispatch agent, conceptualization agent, and modeling agent, which work together to interpret instructions and generate 3D assets
Plain English Explanation
The paper presents a framework called 3D-GPT that uses large language models (LLMs) to simplify the process of creating 3D content and animations. Traditionally, 3D modeling and procedural generation can be a complex and time-consuming task, requiring a deep understanding of rules, algorithms, and parameters. 3D-GPT aims to reduce this workload by leveraging the problem-solving capabilities of LLMs.
The framework integrates three core agents: the task dispatch agent, the conceptualization agent, and the modeling agent. These agents work together to interpret instructions and generate 3D assets. First, the task dispatch agent takes a concise initial scene description and evolves it into a more detailed form, dynamically adapting the text based on subsequent instructions. Then, the conceptualization agent extracts parameter values from the enriched text, which the modeling agent uses to interface with 3D software and create the actual 3D assets.
By using LLMs in this way, the researchers aim to make 3D content creation and procedural generation more accessible and efficient, allowing designers to focus on their creative ideas rather than the technical details. The framework is also designed to integrate seamlessly with existing 3D software, like Blender, expanding the manipulation possibilities for 3D modeling and animation.
Technical Explanation
The 3D-GPT framework is designed to leverage the problem-solving capabilities of large language models (LLMs) to streamline the process of 3D content creation and procedural generation. The researchers argue that traditional 3D modeling and procedural generation can be a complex and demanding endeavor, requiring a deep understanding of rules, algorithms, and parameters.
To address this challenge, the 3D-GPT framework integrates three core agents:
- Task Dispatch Agent: This agent takes an initial, concise scene description and evolves it into a more detailed form, dynamically adapting the text based on subsequent instructions.
- Conceptualization Agent: This agent extracts parameter values from the enriched text, which the modeling agent can then use to interface with 3D software and create the actual 3D assets.
- Modeling Agent: This agent is responsible for the actual creation of 3D assets, using the parameter values provided by the conceptualization agent to generate the 3D content.
By dividing the 3D modeling task into these accessible segments and assigning the appropriate agent to each task, the 3D-GPT framework aims to enhance the efficiency and reliability of the overall 3D content creation process. The researchers evaluate the performance of 3D-GPT, demonstrating its ability to interpret and execute instructions, deliver reliable results, and collaborate effectively with human designers.
The framework is also designed to seamlessly integrate with Blender, a popular 3D modeling and animation software, unlocking expanded manipulation possibilities for 3D modeling and animation.
Critical Analysis
The 3D-GPT framework presents a promising approach to leveraging large language models for 3D content creation and procedural generation. However, the paper does not provide a detailed evaluation of the framework's performance, nor does it address potential limitations or areas for further research.
While the researchers demonstrate the framework's ability to interpret instructions and generate 3D assets, it would be helpful to understand the specific metrics used to evaluate the quality and fidelity of the generated content. Additionally, the paper does not discuss the computational resources required to run the 3D-GPT framework, which could be a significant consideration for real-world deployment.
Furthermore, the paper does not address potential issues related to the use of large language models, such as bias, safety, or robustness. These are important factors to consider when deploying such systems in creative workflows.
Conclusion
The 3D-GPT framework presented in this paper demonstrates the potential of using large language models to simplify and enhance the process of 3D content creation and procedural generation. By integrating LLMs as problem-solvers and dividing the modeling task into accessible segments, the framework aims to reduce the workload and technical complexity for designers.
While the paper provides a promising proof of concept, further research is needed to fully explore the capabilities and limitations of this approach. Addressing issues related to performance metrics, computational resources, and the responsible use of large language models will be crucial for the practical deployment and wider adoption of 3D-GPT in real-world creative workflows.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
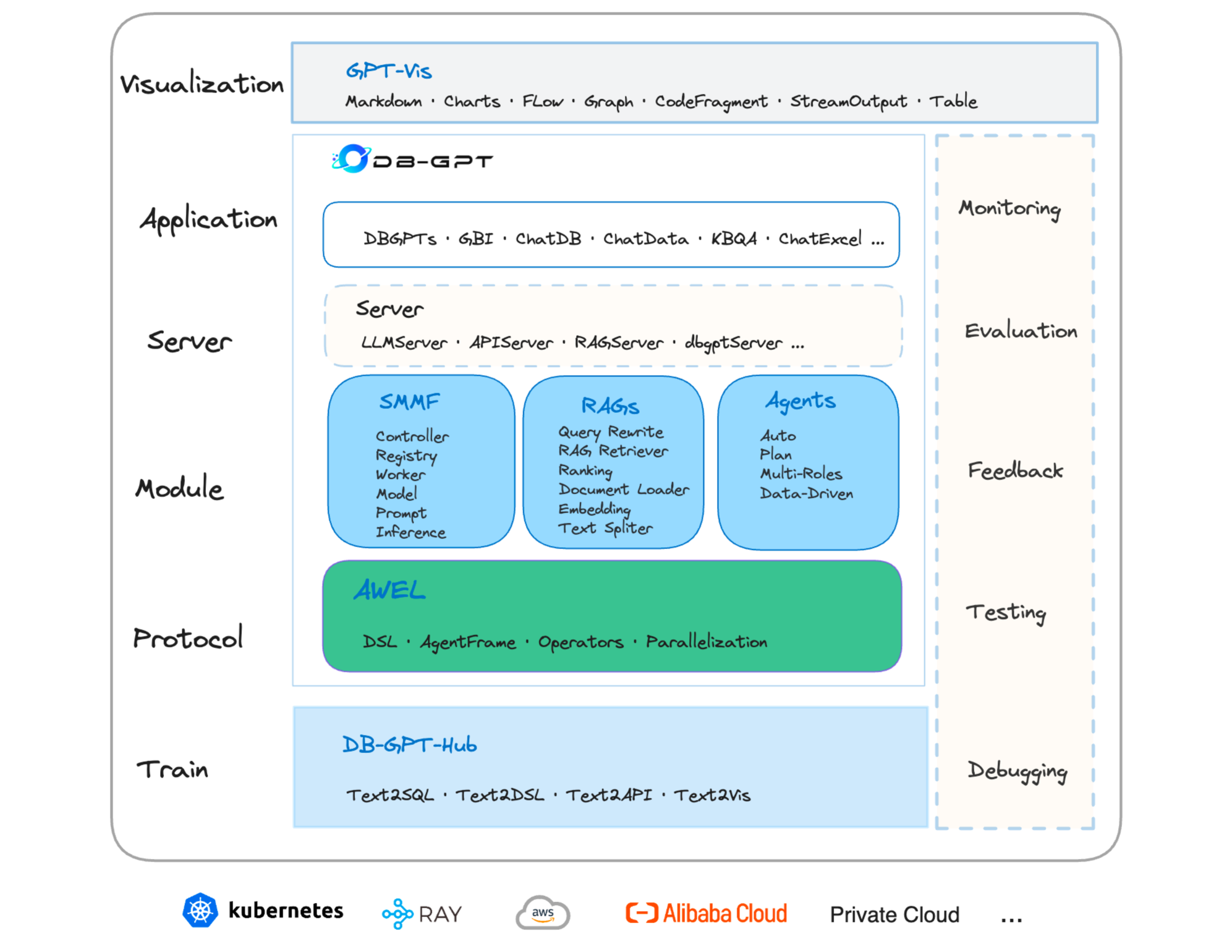
Demonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models
Siqiao Xue, Danrui Qi, Caigao Jiang, Wenhui Shi, Fangyin Cheng, Keting Chen, Hongjun Yang, Zhiping Zhang, Jianshan He, Hongyang Zhang, Ganglin Wei, Wang Zhao, Fan Zhou, Hong Yi, Shaodong Liu, Hongjun Yang, Faqiang Chen
0
0
The recent breakthroughs in large language models (LLMs) are positioned to transition many areas of software. The technologies of interacting with data particularly have an important entanglement with LLMs as efficient and intuitive data interactions are paramount. In this paper, we present DB-GPT, a revolutionary and product-ready Python library that integrates LLMs into traditional data interaction tasks to enhance user experience and accessibility. DB-GPT is designed to understand data interaction tasks described by natural language and provide context-aware responses powered by LLMs, making it an indispensable tool for users ranging from novice to expert. Its system design supports deployment across local, distributed, and cloud environments. Beyond handling basic data interaction tasks like Text-to-SQL with LLMs, it can handle complex tasks like generative data analysis through a Multi-Agents framework and the Agentic Workflow Expression Language (AWEL). The Service-oriented Multi-model Management Framework (SMMF) ensures data privacy and security, enabling users to employ DB-GPT with private LLMs. Additionally, DB-GPT offers a series of product-ready features designed to enable users to integrate DB-GPT within their product environments easily. The code of DB-GPT is available at Github(https://github.com/eosphoros-ai/DB-GPT) which already has over 10.7k stars. Please install DB-GPT for your own usage with the instructions(https://github.com/eosphoros-ai/DB-GPT#install) and watch a 5-minute introduction video on Youtube(https://youtu.be/n_8RI1ENyl4) to further investigate DB-GPT.
4/26/2024
💬
CityGPT: Empowering Urban Spatial Cognition of Large Language Models
Jie Feng, Yuwei Du, Tianhui Liu, Siqi Guo, Yuming Lin, Yong Li
0
0
Large language models(LLMs) with powerful language generation and reasoning capabilities have already achieved success in many domains, e.g., math and code generation. However, due to the lacking of physical world's corpus and knowledge during training, they usually fail to solve many real-life tasks in the urban space. In this paper, we propose CityGPT, a systematic framework for enhancing the capability of LLMs on understanding urban space and solving the related urban tasks by building a city-scale world model in the model. First, we construct a diverse instruction tuning dataset CityInstruction for injecting urban knowledge and enhancing spatial reasoning capability effectively. By using a mixture of CityInstruction and general instruction data, we fine-tune various LLMs (e.g., ChatGLM3-6B, Qwen1.5 and LLama3 series) to enhance their capability without sacrificing general abilities. To further validate the effectiveness of proposed methods, we construct a comprehensive benchmark CityEval to evaluate the capability of LLMs on diverse urban scenarios and problems. Extensive evaluation results demonstrate that small LLMs trained with CityInstruction can achieve competitive performance with commercial LLMs in the comprehensive evaluation of CityEval. The source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityGPT.
6/21/2024

Generating Games via LLMs: An Investigation with Video Game Description Language
Chengpeng Hu, Yunlong Zhao, Jialin Liu
0
0
Recently, the emergence of large language models (LLMs) has unlocked new opportunities for procedural content generation. However, recent attempts mainly focus on level generation for specific games with defined game rules such as Super Mario Bros. and Zelda. This paper investigates the game generation via LLMs. Based on video game description language, this paper proposes an LLM-based framework to generate game rules and levels simultaneously. Experiments demonstrate how the framework works with prompts considering different combinations of context. Our findings extend the current applications of LLMs and offer new insights for generating new games in the area of procedural content generation.
5/31/2024

Layout Generation Agents with Large Language Models
Yuichi Sasazawa, Yasuhiro Sogawa
0
0
In recent years, there has been an increasing demand for customizable 3D virtual spaces. Due to the significant human effort required to create these virtual spaces, there is a need for efficiency in virtual space creation. While existing studies have proposed methods for automatically generating layouts such as floor plans and furniture arrangements, these methods only generate text indicating the layout structure based on user instructions, without utilizing the information obtained during the generation process. In this study, we propose an agent-driven layout generation system using the GPT-4V multimodal large language model and validate its effectiveness. Specifically, the language model manipulates agents to sequentially place objects in the virtual space, thus generating layouts that reflect user instructions. Experimental results confirm that our proposed method can generate virtual spaces reflecting user instructions with a high success rate. Additionally, we successfully identified elements contributing to the improvement in behavior generation performance through ablation study.
5/15/2024