Demonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models
2404.10209
0
0
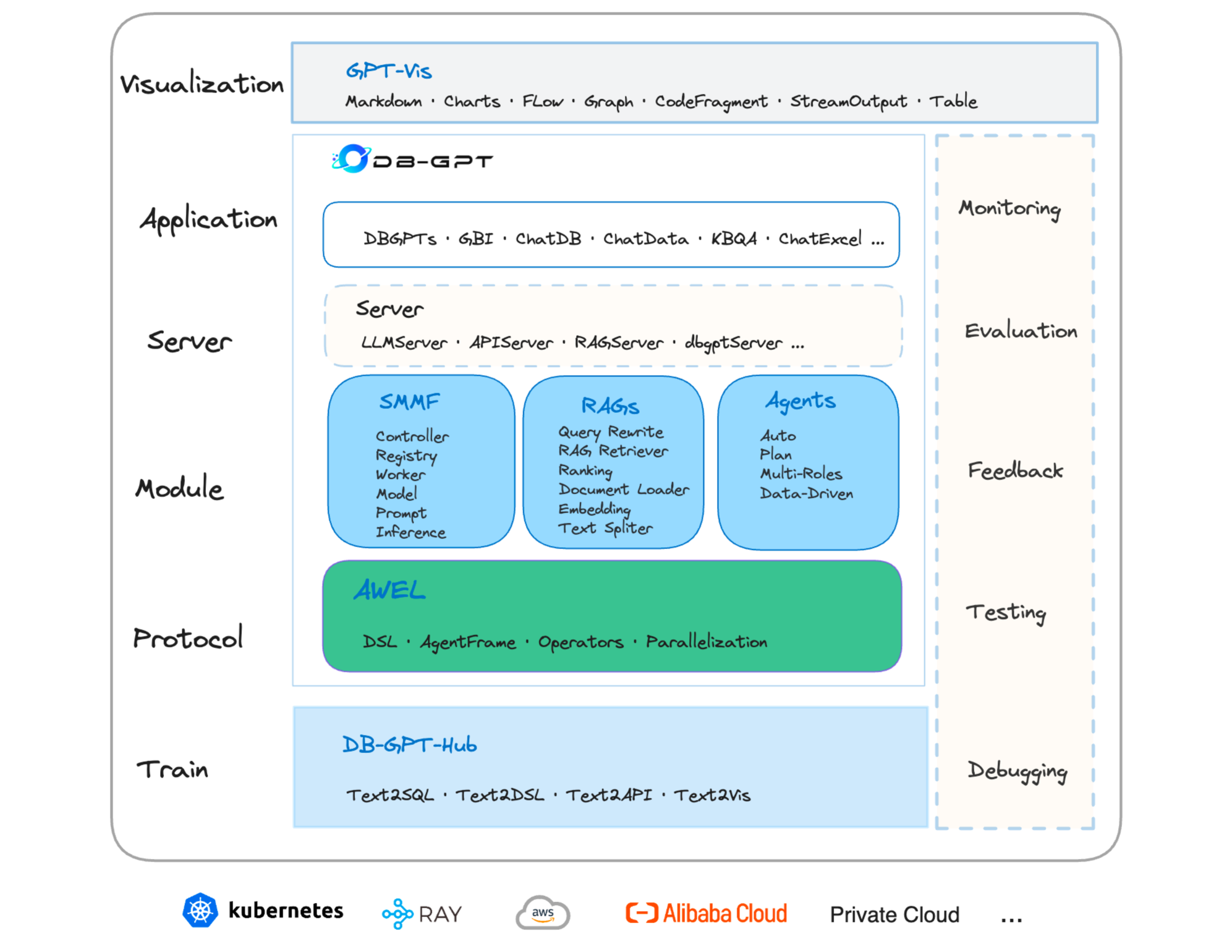
Abstract
The recent breakthroughs in large language models (LLMs) are positioned to transition many areas of software. The technologies of interacting with data particularly have an important entanglement with LLMs as efficient and intuitive data interactions are paramount. In this paper, we present DB-GPT, a revolutionary and product-ready Python library that integrates LLMs into traditional data interaction tasks to enhance user experience and accessibility. DB-GPT is designed to understand data interaction tasks described by natural language and provide context-aware responses powered by LLMs, making it an indispensable tool for users ranging from novice to expert. Its system design supports deployment across local, distributed, and cloud environments. Beyond handling basic data interaction tasks like Text-to-SQL with LLMs, it can handle complex tasks like generative data analysis through a Multi-Agents framework and the Agentic Workflow Expression Language (AWEL). The Service-oriented Multi-model Management Framework (SMMF) ensures data privacy and security, enabling users to employ DB-GPT with private LLMs. Additionally, DB-GPT offers a series of product-ready features designed to enable users to integrate DB-GPT within their product environments easily. The code of DB-GPT is available at Github(https://github.com/eosphoros-ai/DB-GPT) which already has over 10.7k stars. Please install DB-GPT for your own usage with the instructions(https://github.com/eosphoros-ai/DB-GPT#install) and watch a 5-minute introduction video on Youtube(https://youtu.be/n_8RI1ENyl4) to further investigate DB-GPT.
Create account to get full access
Overview
- This paper introduces DB-GPT, a next-generation data interaction system powered by large language models.
- DB-GPT aims to enhance data exploration, analysis, and management through natural language interactions.
- The system combines natural language processing, knowledge graph integration, and task-oriented dialogue capabilities.
Plain English Explanation
DB-GPT is a new kind of data analysis tool that uses advanced language models to make interacting with data much more natural and intuitive. Instead of having to learn complex software or programming, users can simply ask questions in plain English and the system will understand their intent, access relevant data, and provide helpful information.
The key innovation in DB-GPT is the integration of large language models, which are AI systems trained on massive amounts of text data to understand and generate human-like language. By harnessing these powerful language understanding capabilities, DB-GPT can engage in more natural, conversational interactions around data. Users can ask follow-up questions, get clarification, and explore data in an iterative, exploratory way - similar to how they might interact with another person.
Overall, the goal of DB-GPT is to make data exploration and analysis much more accessible and intuitive for a wide range of users, not just highly technical data analysts. By lowering the barrier to effective data interaction, the system aims to empower more people to gain insights and make informed decisions from their data.
Technical Explanation
At the core of the DB-GPT system is a large language model that has been trained on vast amounts of text data to develop a deep understanding of natural language. This language model forms the "brain" of the system, allowing it to comprehend user queries, engage in contextual dialogue, and generate relevant and coherent responses.
To further enhance the system's data understanding and task-completion capabilities, DB-GPT integrates structured knowledge bases. These knowledge bases provide additional contextual information and domain-specific knowledge that the language model can draw upon during its interactions.
The system is designed with an application layer that handles the user-facing dialogue interactions. This layer is responsible for interpreting the user's natural language inputs, formulating appropriate queries to the data sources, and generating relevant responses. The application layer also coordinates with other system components, such as a task planner and dialog manager, to ensure smooth, multi-turn conversations.
In the backend, DB-GPT integrates with various data sources, such as databases, knowledge graphs, and other structured data repositories. The system can seamlessly access and reason over this data to provide informative and actionable responses to user queries.
One key aspect of the system is its ability to dynamically generate personalized responses and adapt its conversational style to the individual user. This helps to create a more natural and engaging interaction, tailored to the user's preferences and communication style.
Critical Analysis
The authors acknowledge several limitations and areas for further research in the DB-GPT system. One key challenge is ensuring the system's responses are consistently accurate, relevant, and trustworthy, particularly when dealing with complex or ambiguous queries. Robustness and reliability will be important areas for continued development and evaluation.
Additionally, the integration of structured knowledge bases, while beneficial, also introduces potential issues around knowledge representation, ontology alignment, and knowledge base curation. Ensuring the knowledge bases are comprehensive, up-to-date, and well-aligned with the data sources will be an ongoing challenge.
Another area for further research is the development of more sophisticated dialogue management and task planning capabilities to handle longer, more open-ended conversations. As the system becomes more advanced, maintaining coherence and context across multiple turns of dialogue will be crucial.
Overall, the DB-GPT system represents an exciting step forward in making data interaction more accessible and intuitive for a broad range of users. However, realizing the full potential of this technology will require continued research and development to address the various technical and practical challenges.
Conclusion
The DB-GPT system introduced in this paper represents a promising approach to enhancing data exploration, analysis, and management through the use of large language models and structured knowledge integration. By enabling more natural, conversational interactions with data, the system aims to empower a wider range of users to gain insights and make informed decisions.
While the authors acknowledge several areas for further development, the core ideas behind DB-GPT demonstrate the potential of combining advanced language understanding, task-oriented dialogue, and structured data access. As this technology continues to evolve, it could have significant implications for how people interact with and derive value from their data in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
3D-GPT: Procedural 3D Modeling with Large Language Models
Chunyi Sun, Junlin Han, Weijian Deng, Xinlong Wang, Zishan Qin, Stephen Gould
0
0
In the pursuit of efficient automated content creation, procedural generation, leveraging modifiable parameters and rule-based systems, emerges as a promising approach. Nonetheless, it could be a demanding endeavor, given its intricate nature necessitating a deep understanding of rules, algorithms, and parameters. To reduce workload, we introduce 3D-GPT, a framework utilizing large language models~(LLMs) for instruction-driven 3D modeling. 3D-GPT positions LLMs as proficient problem solvers, dissecting the procedural 3D modeling tasks into accessible segments and appointing the apt agent for each task. 3D-GPT integrates three core agents: the task dispatch agent, the conceptualization agent, and the modeling agent. They collaboratively achieve two objectives. First, it enhances concise initial scene descriptions, evolving them into detailed forms while dynamically adapting the text based on subsequent instructions. Second, it integrates procedural generation, extracting parameter values from enriched text to effortlessly interface with 3D software for asset creation. Our empirical investigations confirm that 3D-GPT not only interprets and executes instructions, delivering reliable results but also collaborates effectively with human designers. Furthermore, it seamlessly integrates with Blender, unlocking expanded manipulation possibilities. Our work highlights the potential of LLMs in 3D modeling, offering a basic framework for future advancements in scene generation and animation.
5/30/2024
✨
DiagGPT: An LLM-based and Multi-agent Dialogue System with Automatic Topic Management for Flexible Task-Oriented Dialogue
Lang Cao
0
0
A significant application of Large Language Models (LLMs), like ChatGPT, is their deployment as chat agents, which respond to human inquiries across a variety of domains. While current LLMs proficiently answer general questions, they often fall short in complex diagnostic scenarios such as legal, medical, or other specialized consultations. These scenarios typically require Task-Oriented Dialogue (TOD), where an AI chat agent must proactively pose questions and guide users toward specific goals or task completion. Previous fine-tuning models have underperformed in TOD and the full potential of conversational capability in current LLMs has not yet been fully explored. In this paper, we introduce DiagGPT (Dialogue in Diagnosis GPT), an innovative approach that extends LLMs to more TOD scenarios. In addition to guiding users to complete tasks, DiagGPT can effectively manage the status of all topics throughout the dialogue development. This feature enhances user experience and offers a more flexible interaction in TOD. Our experiments demonstrate that DiagGPT exhibits outstanding performance in conducting TOD with users, showing its potential for practical applications in various fields.
4/16/2024
📈
ZzzGPT: An Interactive GPT Approach to Enhance Sleep Quality
Yonchanok Khaokaew, Kaixin Ji, Thuc Hanh Nguyen, Hiruni Kegalle, Marwah Alaofi, Hao Xue, Flora D. Salim
0
0
This paper explores the intersection of technology and sleep pattern comprehension, presenting a cutting-edge two-stage framework that harnesses the power of Large Language Models (LLMs). The primary objective is to deliver precise sleep predictions paired with actionable feedback, addressing the limitations of existing solutions. This innovative approach involves leveraging the GLOBEM dataset alongside synthetic data generated by LLMs. The results highlight significant improvements, underlining the efficacy of merging advanced machine-learning techniques with a user-centric design ethos. Through this exploration, we bridge the gap between technological sophistication and user-friendly design, ensuring that our framework yields accurate predictions and translates them into actionable insights.
5/8/2024
PatentGPT: A Large Language Model for Intellectual Property
Zilong Bai, Ruiji Zhang, Linqing Chen, Qijun Cai, Yuan Zhong, Cong Wang, Yan Fang, Jie Fang, Jing Sun, Weikuan Wang, Lizhi Zhou, Haoran Hua, Tian Qiu, Chaochao Wang, Cheng Sun, Jianping Lu, Yixin Wang, Yubin Xia, Meng Hu, Haowen Liu, Peng Xu, Licong Xu, Fu Bian, Xiaolong Gu, Lisha Zhang, Weilei Wang, Changyang Tu
0
0
In recent years, large language models(LLMs) have attracted significant attention due to their exceptional performance across a multitude of natural language process tasks, and have been widely applied in various fields. However, the application of large language models in the Intellectual Property (IP) domain is challenging due to the strong need for specialized knowledge, privacy protection, processing of extremely long text in this field. In this technical report, we present for the first time a low-cost, standardized procedure for training IP-oriented LLMs, meeting the unique requirements of the IP domain. Using this standard process, we have trained the PatentGPT series models based on open-source pretrained models. By evaluating them on the open-source IP-oriented benchmark MOZIP, our domain-specific LLMs outperforms GPT-4, indicating the effectiveness of the proposed training procedure and the expertise of the PatentGPT models in the IP domain. Remarkably, our model surpassed GPT-4 on the 2019 China Patent Agent Qualification Examination, scoring 65 and matching human expert levels. Additionally, the PatentGPT model, which utilizes the SMoE architecture, achieves performance comparable to that of GPT-4 in the IP domain and demonstrates a better cost-performance ratio on long-text tasks, potentially serving as an alternative to GPT-4 within the IP domain.
6/6/2024