3D-GRAND: Towards Better Grounding and Less Hallucination for 3D-LLMs

0

Sign in to get full access
Overview
- This paper introduces 3D-GRAND, a new approach to improve the grounding and reduce hallucination in 3D large language models (3D-LLMs).
- 3D-LLMs are a new frontier in AI, aiming to combine natural language processing with 3D understanding for applications like 3D scene generation, robotic navigation, and virtual assistants.
- However, current 3D-LLMs struggle with grounding language to the 3D world and often hallucinate unrealistic content, limiting their real-world usefulness.
- The 3D-GRAND method aims to address these challenges by introducing grounded referent tokens and a 3D-aware language model pre-training approach.
Plain English Explanation
The paper presents a new technique called 3D-GRAND to improve the performance of 3D language models, which are a type of AI system that can understand and generate language while also working with 3D information. Current 3D language models have trouble connecting the language they use to the actual 3D world, and they sometimes create unrealistic or made-up content, which limits how useful they can be.
The 3D-GRAND method introduces two key ideas to address these problems:
-
Grounded referent tokens: These are special tokens that help the language model better ground the language it uses to actual 3D objects and scenes. This allows the model to avoid hallucinating unrealistic content.
-
3D-aware pre-training: The researchers pre-train the language model using a combination of text data and 3D visual data. This helps the model learn the connections between language and the 3D world more effectively.
By incorporating these innovations, the 3D-GRAND approach aims to create 3D language models that are better grounded in reality and produce more reliable and useful outputs. This could enable more advanced applications like 3D scene generation, robotic navigation, and virtual assistants that can understand and interact with the 3D world in a more natural and human-like way.
Technical Explanation
The paper introduces 3D-GRAND, a new approach to improve the grounding and reduce hallucination in 3D large language models (3D-LLMs). 3D-LLMs aim to combine natural language processing with 3D understanding for applications like 3D scene generation, robotic navigation, and virtual assistants.
The key innovations in 3D-GRAND are:
-
Grounded referent tokens: The researchers propose introducing special tokens called "grounded referent tokens" that represent specific 3D objects, entities, and concepts. These tokens help the language model ground its language outputs to the actual 3D world, reducing the tendency to hallucinate unrealistic content.
-
3D-aware pre-training: The 3D-GRAND approach pre-trains the language model using a combination of text data and 3D visual data. This helps the model learn the connections between language and the 3D world more effectively, leading to better grounding and less hallucination.
The researchers evaluate 3D-GRAND on various 3D language understanding and generation tasks, including 3D scene description, 3D object retrieval, and 3D-aware story generation. The results show that 3D-GRAND outperforms previous state-of-the-art 3D-LLM approaches in terms of grounding, faithfulness, and overall performance.
Critical Analysis
The 3D-GRAND approach presented in this paper is a promising step towards more grounded and reliable 3D language models. The use of grounded referent tokens and 3D-aware pre-training are innovative ideas that could help address the key challenges of poor grounding and hallucination that plague current 3D-LLMs.
However, the paper does not provide a detailed analysis of the limitations and potential issues with the 3D-GRAND approach. For example, it's unclear how scalable the grounded referent token approach is and how well it would generalize to a broader range of 3D concepts and entities. Additionally, the pre-training data and methodology used may introduce biases that could affect the model's performance in real-world scenarios.
Further research is needed to explore the generalization and robustness of the 3D-GRAND approach, as well as to investigate potential ways to make the method more efficient and adaptable. Careful evaluation of the model's outputs in diverse 3D environments and applications would also be valuable to understand its true capabilities and limitations.
Conclusion
The 3D-GRAND paper presents an innovative approach to improving the grounding and reducing the hallucination in 3D large language models (3D-LLMs). By introducing grounded referent tokens and 3D-aware pre-training, the researchers aim to create 3D-LLMs that are better connected to the actual 3D world, leading to more reliable and useful outputs.
This work represents an important step forward in the development of 3D-LLMs, which have the potential to enable a wide range of applications, from 3D scene generation and robotic navigation to virtual assistants that can understand and interact with the 3D environment. While the 3D-GRAND approach shows promise, further research is needed to fully realize the potential of this technology and address its current limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
3D-GRAND: Towards Better Grounding and Less Hallucination for 3D-LLMs
Jianing Yang, Xuweiyi Chen, Nikhil Madaan, Madhavan Iyengar, Shengyi Qian, David F. Fouhey, Joyce Chai
The integration of language and 3D perception is crucial for developing embodied agents and robots that comprehend and interact with the physical world. While large language models (LLMs) have demonstrated impressive language understanding and generation capabilities, their adaptation to 3D environments (3D-LLMs) remains in its early stages. A primary challenge is the absence of large-scale datasets that provide dense grounding between language and 3D scenes. In this paper, we introduce 3D-GRAND, a pioneering large-scale dataset comprising 40,087 household scenes paired with 6.2 million densely-grounded scene-language instructions. Our results show that instruction tuning with 3D-GRAND significantly enhances grounding capabilities and reduces hallucinations in 3D-LLMs. As part of our contributions, we propose a comprehensive benchmark 3D-POPE to systematically evaluate hallucination in 3D-LLMs, enabling fair comparisons among future models. Our experiments highlight a scaling effect between dataset size and 3D-LLM performance, emphasizing the critical role of large-scale 3D-text datasets in advancing embodied AI research. Notably, our results demonstrate early signals for effective sim-to-real transfer, indicating that models trained on large synthetic data can perform well on real-world 3D scans. Through 3D-GRAND and 3D-POPE, we aim to equip the embodied AI community with essential resources and insights, setting the stage for more reliable and better-grounded 3D-LLMs. Project website: https://3d-grand.github.io
Read more6/13/2024
0
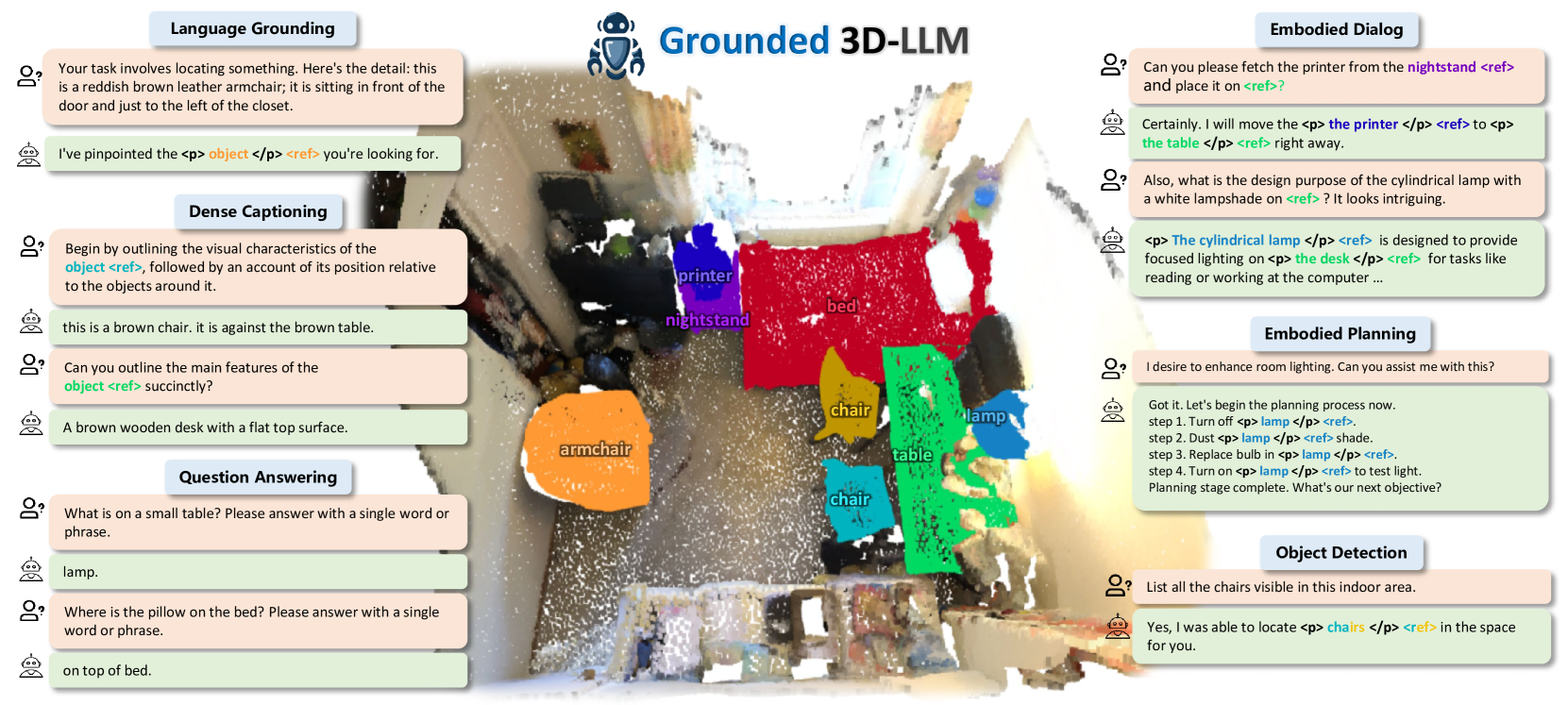
Grounded 3D-LLM with Referent Tokens
Yilun Chen, Shuai Yang, Haifeng Huang, Tai Wang, Ruiyuan Lyu, Runsen Xu, Dahua Lin, Jiangmiao Pang
Prior studies on 3D scene understanding have primarily developed specialized models for specific tasks or required task-specific fine-tuning. In this study, we propose Grounded 3D-LLM, which explores the potential of 3D large multi-modal models (3D LMMs) to consolidate various 3D vision tasks within a unified generative framework. The model uses scene referent tokens as special noun phrases to reference 3D scenes, enabling the handling of sequences that interleave 3D and textual data. It offers a natural approach for translating 3D vision tasks into language formats using task-specific instruction templates. To facilitate the use of referent tokens in subsequent language modeling, we have curated large-scale grounded language datasets that offer finer scene-text correspondence at the phrase level by bootstrapping existing object labels. Subsequently, we introduced Contrastive LAnguage-Scene Pre-training (CLASP) to effectively leverage this data, thereby integrating 3D vision with language models. Our comprehensive evaluation covers open-ended tasks like dense captioning and 3D QA, alongside close-ended tasks such as object detection and language grounding. Experiments across multiple 3D benchmarks reveal the leading performance and the broad applicability of Grounded 3D-LLM. Code and datasets will be released on the project page: https://groundedscenellm.github.io/grounded_3d-llm.github.io.
Read more5/20/2024

0
SceneVerse: Scaling 3D Vision-Language Learning for Grounded Scene Understanding
Baoxiong Jia, Yixin Chen, Huangyue Yu, Yan Wang, Xuesong Niu, Tengyu Liu, Qing Li, Siyuan Huang
3D vision-language grounding, which focuses on aligning language with the 3D physical environment, stands as a cornerstone in the development of embodied agents. In comparison to recent advancements in the 2D domain, grounding language in 3D scenes faces several significant challenges: (i) the inherent complexity of 3D scenes due to the diverse object configurations, their rich attributes, and intricate relationships; (ii) the scarcity of paired 3D vision-language data to support grounded learning; and (iii) the absence of a unified learning framework to distill knowledge from grounded 3D data. In this work, we aim to address these three major challenges in 3D vision-language by examining the potential of systematically upscaling 3D vision-language learning in indoor environments. We introduce the first million-scale 3D vision-language dataset, SceneVerse, encompassing about 68K 3D indoor scenes and comprising 2.5M vision-language pairs derived from both human annotations and our scalable scene-graph-based generation approach. We demonstrate that this scaling allows for a unified pre-training framework, Grounded Pre-training for Scenes (GPS), for 3D vision-language learning. Through extensive experiments, we showcase the effectiveness of GPS by achieving state-of-the-art performance on all existing 3D visual grounding benchmarks. The vast potential of SceneVerse and GPS is unveiled through zero-shot transfer experiments in the challenging 3D vision-language tasks. Project website: https://scene-verse.github.io.
Read more9/25/2024

0
Empowering 3D Visual Grounding with Reasoning Capabilities
Chenming Zhu, Tai Wang, Wenwei Zhang, Kai Chen, Xihui Liu
Although great progress has been made in 3D visual grounding, current models still rely on explicit textual descriptions for grounding and lack the ability to reason human intentions from implicit instructions. We propose a new task called 3D reasoning grounding and introduce a new benchmark ScanReason which provides over 10K question-answer-location pairs from five reasoning types that require the synerization of reasoning and grounding. We further design our approach, ReGround3D, composed of the visual-centric reasoning module empowered by Multi-modal Large Language Model (MLLM) and the 3D grounding module to obtain accurate object locations by looking back to the enhanced geometry and fine-grained details from the 3D scenes. A chain-of-grounding mechanism is proposed to further boost the performance with interleaved reasoning and grounding steps during inference. Extensive experiments on the proposed benchmark validate the effectiveness of our proposed approach.
Read more7/18/2024