When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models
2405.10255
0
0

Abstract
As large language models (LLMs) evolve, their integration with 3D spatial data (3D-LLMs) has seen rapid progress, offering unprecedented capabilities for understanding and interacting with physical spaces. This survey provides a comprehensive overview of the methodologies enabling LLMs to process, understand, and generate 3D data. Highlighting the unique advantages of LLMs, such as in-context learning, step-by-step reasoning, open-vocabulary capabilities, and extensive world knowledge, we underscore their potential to significantly advance spatial comprehension and interaction within embodied Artificial Intelligence (AI) systems. Our investigation spans various 3D data representations, from point clouds to Neural Radiance Fields (NeRFs). It examines their integration with LLMs for tasks such as 3D scene understanding, captioning, question-answering, and dialogue, as well as LLM-based agents for spatial reasoning, planning, and navigation. The paper also includes a brief review of other methods that integrate 3D and language. The meta-analysis presented in this paper reveals significant progress yet underscores the necessity for novel approaches to harness the full potential of 3D-LLMs. Hence, with this paper, we aim to chart a course for future research that explores and expands the capabilities of 3D-LLMs in understanding and interacting with the complex 3D world. To support this survey, we have established a project page where papers related to our topic are organized and listed: https://github.com/ActiveVisionLab/Awesome-LLM-3D.
Create account to get full access
Overview
- This paper surveys and analyzes the use of multi-modal large language models (LLMs) for 3D understanding tasks.
- It explores how LLMs, which have shown impressive capabilities in language and vision domains, can be applied to 3D scene understanding.
- The paper covers a range of 3D tasks, including object detection, semantic segmentation, and reconstruction, and evaluates the performance of various LLM-based approaches.
Plain English Explanation
Large language models (LLMs) like GPT-3 and DALL-E have demonstrated remarkable abilities in processing natural language and generating human-like text. Recently, researchers have started exploring how these powerful models can also be used for tasks related to the 3D world, such as understanding the contents of 3D scenes, detecting objects, and even reconstructing 3D shapes.
This paper provides a comprehensive survey and analysis of these efforts, examining how LLMs can be leveraged for various 3D understanding tasks. The authors look at different approaches that combine LLMs with other techniques, like computer vision and reinforcement learning, to tackle problems like object detection, semantic segmentation (labeling the different elements in a scene), and 3D reconstruction.
By exploring the strengths and limitations of these LLM-based methods, the paper offers insights into the potential of using large language models to make sense of the 3D world around us. This could have applications in areas like robotics, virtual and augmented reality, and even autonomous vehicles, where understanding the 3D environment is crucial.
Technical Explanation
The paper begins by discussing the recent advancements in multi-modal large language models and their potential for 3D scene understanding tasks. It highlights how these models, which are trained on vast amounts of data spanning language, images, and other modalities, can potentially leverage their rich representations to tackle 3D-related problems.
The authors then provide a comprehensive survey of the various LLM-based approaches for 3D tasks, including object detection, semantic segmentation, and 3D reconstruction. They examine how these models are designed, the specific architectural choices and training strategies employed, and the performance of these systems on benchmark datasets.
A key focus of the paper is the evaluation of the spatial understanding capabilities of LLMs. The authors assess the models' ability to reason about 3D relationships, spatial awareness, and visual-linguistic grounding, which are crucial for 3D scene understanding.
The paper also discusses [the use of LLMs in a more unified scene representation and reconstruction framework, where the models are tasked with jointly understanding and reconstructing 3D environments from various input modalities.
Additionally, the authors explore the potential of integrating 3D reasoning and situated cognition into LLMs, allowing the models to reason about the physical world and take appropriate actions within it.
Critical Analysis
The paper provides a thorough and well-researched analysis of the current state of LLM-based 3D understanding. It acknowledges the limitations of existing approaches, such as the difficulty in capturing detailed 3D geometry and the need for further advancements in spatial reasoning.
The authors also note that the field is still relatively new, and there is significant room for improvement in terms of model performance, generalization, and robustness. They highlight the need for larger and more diverse 3D datasets, as well as the development of more sophisticated architectural designs and training strategies to better leverage the capabilities of LLMs.
Furthermore, the paper raises important questions about the interpretability and explainability of these LLM-based systems, which is crucial for their deployment in real-world applications where transparency and accountability are paramount.
Conclusion
This paper provides a timely and valuable contribution to the emerging field of 3D scene understanding using multi-modal large language models. By surveying the current state of the art and conducting a meta-analysis of various approaches, the authors have shed light on the potential and challenges of applying these powerful models to the 3D world.
The insights and findings presented in this work have significant implications for the development of robust and versatile 3D understanding systems, with applications ranging from robotics and augmented reality to autonomous vehicles and beyond. As the field continues to evolve, this paper serves as an important reference point and a catalyst for further research and innovation in this exciting and rapidly progressing area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Language-Image Models with 3D Understanding
Jang Hyun Cho, Boris Ivanovic, Yulong Cao, Edward Schmerling, Yue Wang, Xinshuo Weng, Boyi Li, Yurong You, Philipp Krahenbuhl, Yan Wang, Marco Pavone
0
0
Multi-modal large language models (MLLMs) have shown incredible capabilities in a variety of 2D vision and language tasks. We extend MLLMs' perceptual capabilities to ground and reason about images in 3-dimensional space. To that end, we first develop a large-scale pre-training dataset for 2D and 3D called LV3D by combining multiple existing 2D and 3D recognition datasets under a common task formulation: as multi-turn question-answering. Next, we introduce a new MLLM named Cube-LLM and pre-train it on LV3D. We show that pure data scaling makes a strong 3D perception capability without 3D specific architectural design or training objective. Cube-LLM exhibits intriguing properties similar to LLMs: (1) Cube-LLM can apply chain-of-thought prompting to improve 3D understanding from 2D context information. (2) Cube-LLM can follow complex and diverse instructions and adapt to versatile input and output formats. (3) Cube-LLM can be visually prompted such as 2D box or a set of candidate 3D boxes from specialists. Our experiments on outdoor benchmarks demonstrate that Cube-LLM significantly outperforms existing baselines by 21.3 points of AP-BEV on the Talk2Car dataset for 3D grounded reasoning and 17.7 points on the DriveLM dataset for complex reasoning about driving scenarios, respectively. Cube-LLM also shows competitive results in general MLLM benchmarks such as refCOCO for 2D grounding with (87.0) average score, as well as visual question answering benchmarks such as VQAv2, GQA, SQA, POPE, etc. for complex reasoning. Our project is available at https://janghyuncho.github.io/Cube-LLM.
5/7/2024

Reason3D: Searching and Reasoning 3D Segmentation via Large Language Model
Kuan-Chih Huang, Xiangtai Li, Lu Qi, Shuicheng Yan, Ming-Hsuan Yang
0
0
Recent advancements in multimodal large language models (LLMs) have shown their potential in various domains, especially concept reasoning. Despite these developments, applications in understanding 3D environments remain limited. This paper introduces Reason3D, a novel LLM designed for comprehensive 3D understanding. Reason3D takes point cloud data and text prompts as input to produce textual responses and segmentation masks, facilitating advanced tasks like 3D reasoning segmentation, hierarchical searching, express referring, and question answering with detailed mask outputs. Specifically, we propose a hierarchical mask decoder to locate small objects within expansive scenes. This decoder initially generates a coarse location estimate covering the object's general area. This foundational estimation facilitates a detailed, coarse-to-fine segmentation strategy that significantly enhances the precision of object identification and segmentation. Experiments validate that Reason3D achieves remarkable results on large-scale ScanNet and Matterport3D datasets for 3D express referring, 3D question answering, and 3D reasoning segmentation tasks. Code and models are available at: https://github.com/KuanchihHuang/Reason3D.
5/28/2024
💬
Can Large Language Models Create New Knowledge for Spatial Reasoning Tasks?
Thomas Greatrix, Roger Whitaker, Liam Turner, Walter Colombo
0
0
The potential for Large Language Models (LLMs) to generate new information offers a potential step change for research and innovation. This is challenging to assert as it can be difficult to determine what an LLM has previously seen during training, making newness difficult to substantiate. In this paper we observe that LLMs are able to perform sophisticated reasoning on problems with a spatial dimension, that they are unlikely to have previously directly encountered. While not perfect, this points to a significant level of understanding that state-of-the-art LLMs can now achieve, supporting the proposition that LLMs are able to yield significant emergent properties. In particular, Claude 3 is found to perform well in this regard.
5/24/2024
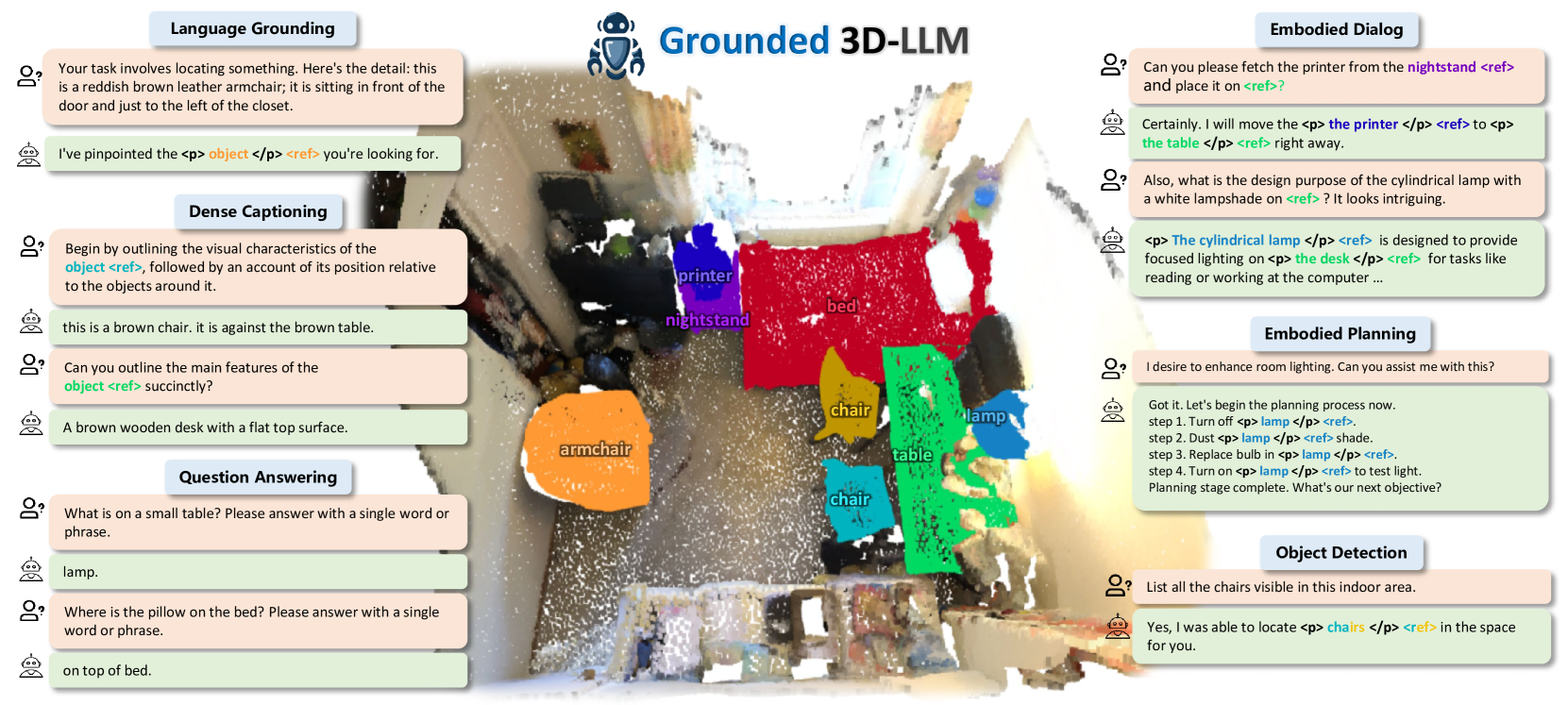
Grounded 3D-LLM with Referent Tokens
Yilun Chen, Shuai Yang, Haifeng Huang, Tai Wang, Ruiyuan Lyu, Runsen Xu, Dahua Lin, Jiangmiao Pang
0
0
Prior studies on 3D scene understanding have primarily developed specialized models for specific tasks or required task-specific fine-tuning. In this study, we propose Grounded 3D-LLM, which explores the potential of 3D large multi-modal models (3D LMMs) to consolidate various 3D vision tasks within a unified generative framework. The model uses scene referent tokens as special noun phrases to reference 3D scenes, enabling the handling of sequences that interleave 3D and textual data. It offers a natural approach for translating 3D vision tasks into language formats using task-specific instruction templates. To facilitate the use of referent tokens in subsequent language modeling, we have curated large-scale grounded language datasets that offer finer scene-text correspondence at the phrase level by bootstrapping existing object labels. Subsequently, we introduced Contrastive LAnguage-Scene Pre-training (CLASP) to effectively leverage this data, thereby integrating 3D vision with language models. Our comprehensive evaluation covers open-ended tasks like dense captioning and 3D QA, alongside close-ended tasks such as object detection and language grounding. Experiments across multiple 3D benchmarks reveal the leading performance and the broad applicability of Grounded 3D-LLM. Code and datasets will be released on the project page: https://groundedscenellm.github.io/grounded_3d-llm.github.io.
5/20/2024