3D Pose-Based Temporal Action Segmentation for Figure Skating: A Fine-Grained and Jump Procedure-Aware Annotation Approach

0
Sign in to get full access
Overview
- The paper presents a 3D pose-based approach for temporal action segmentation in figure skating videos.
- It introduces a fine-grained and jump procedure-aware annotation method to capture the complex and nuanced movements in figure skating.
- The proposed approach aims to enable detailed analysis and understanding of figure skating performances.
Plain English Explanation
The paper focuses on developing a computer vision system to automatically analyze and segment the actions performed by figure skaters in videos. Figure skating is a sport that involves a lot of complex and precise movements, such as jumps, spins, and footwork. The researchers recognized that existing action segmentation methods were not well-suited for the nuances of figure skating, so they developed a new approach.
Their method uses 3D human pose estimation to track the movements of the skater's body. This allows the system to break down the performance into a series of discrete actions, like the different phases of a jump or the specific steps in a footwork sequence. To train the system, the researchers created a new dataset with fine-grained annotations that carefully label all these different elements of a figure skating routine.
By having this level of detail in the annotations and the analysis, the researchers hope the system can provide valuable insights for coaches, choreographers, and even the skaters themselves. It could help them better understand the technical execution of various elements and identify areas for improvement. Overall, this work represents an important step towards more comprehensive and nuanced computational analysis of figure skating and other high-precision athletic activities.
Technical Explanation
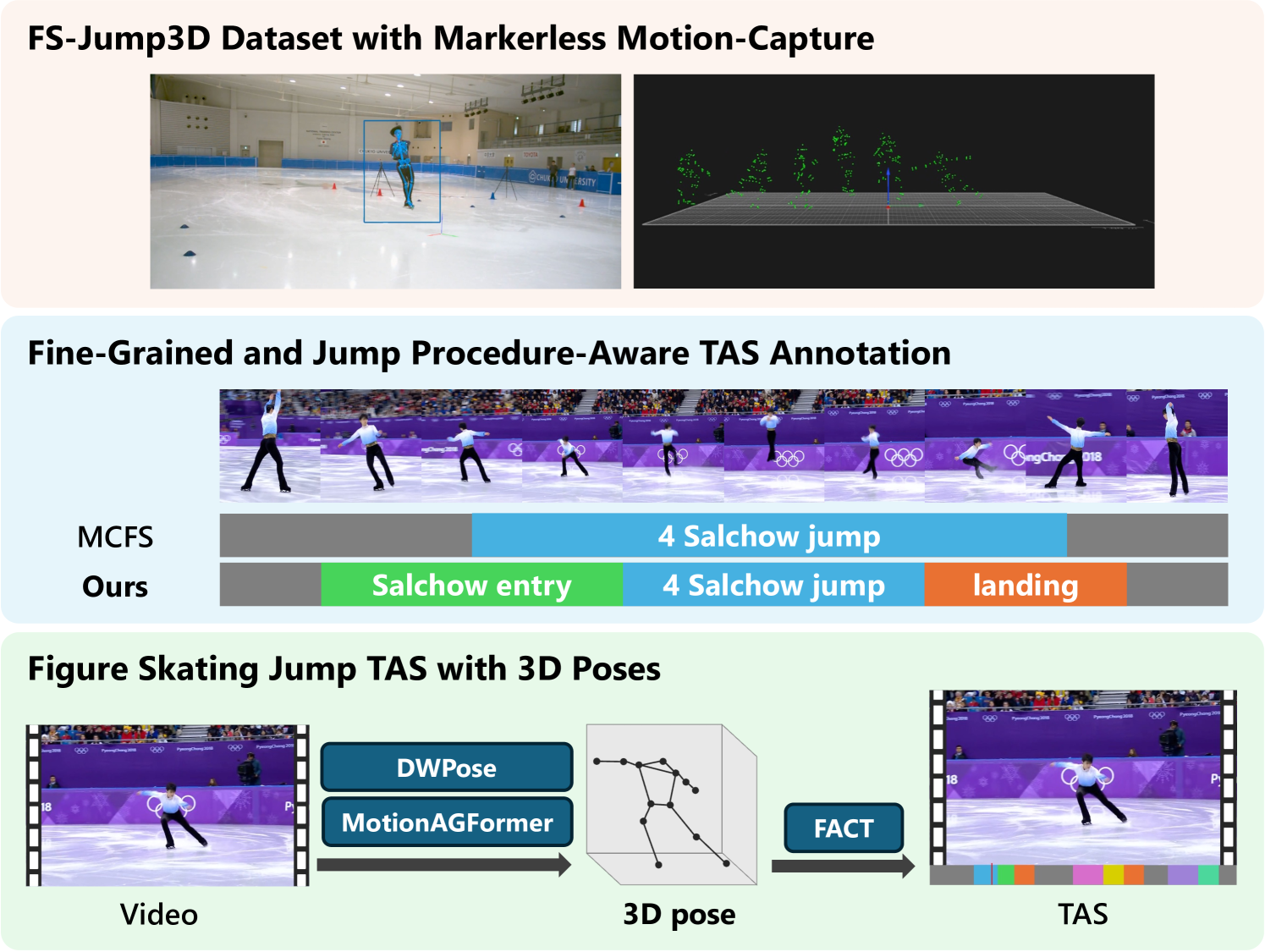
The paper presents a novel approach for temporal action segmentation in figure skating videos using 3D human pose estimation. They introduce a fine-grained and jump procedure-aware annotation method to capture the complex and nuanced movements in figure skating.
The researchers first collected a dataset of figure skating videos and used 3D pose estimation to extract the skater's body joint positions over time. They then developed a new annotation protocol that breaks down figure skating performances into a hierarchical structure of fine-grained action classes, including the different phases of jumps (e.g. take-off, rotation, landing), spins, and other technical elements.
This annotated dataset was used to train a deep learning model for temporal action segmentation. The model takes the 3D pose sequences as input and predicts the sequence of fine-grained actions performed by the skater. The researchers experimented with different neural network architectures and modeling approaches to optimize the segmentation accuracy.
The key insights from this work are:
- Existing action segmentation methods are not well-suited for the nuanced movements in figure skating, motivating the need for a specialized approach.
- The fine-grained and jump procedure-aware annotations provide rich labels that enable the model to learn the complex structure of figure skating performances.
- The 3D pose-based analysis allows the system to capture subtle body movements that are essential for understanding technical execution in figure skating.
Overall, this research demonstrates how specialized computer vision techniques can be developed to enable detailed analysis and understanding of highly technical sports like figure skating.
Critical Analysis
The paper makes a compelling case for the need to develop specialized action segmentation methods for figure skating and other sports with complex, fine-grained movements. The fine-grained annotation approach is a key strength, as it allows the model to learn the nuanced structure of figure skating routines.
However, one potential limitation is the reliance on 3D pose estimation, which can be sensitive to occlusions, camera viewpoint, and other factors that may affect pose estimation accuracy in real-world settings. It would be interesting to see how the approach could be extended to incorporate additional modalities, such as video or inertial measurement data, to provide more robust performance analysis.
Additionally, while the paper introduces the new dataset and demonstrates the effectiveness of the approach on it, further validation on a wider range of figure skating videos would help to assess the generalizability of the method. Comparisons to human expert annotations or other existing figure skating analysis tools could also provide useful insights.
Finally, the paper focuses primarily on the technical aspects of the approach, but it would be valuable to explore the practical implications and use cases for this technology, such as how it could be deployed to support coach-athlete collaboration, choreography design, or athlete training and development.
Conclusion
This paper presents an innovative approach for temporally segmenting figure skating performances using 3D human pose estimation and fine-grained, jump procedure-aware annotations. By capturing the complex, nuanced movements of figure skating in a structured way, the proposed method opens up new opportunities for detailed computational analysis and understanding of this technically demanding sport.
The findings demonstrate the importance of developing specialized computer vision techniques for high-precision athletic activities, and the potential of this work to provide valuable insights for coaches, choreographers, and skaters themselves. As the field of sports analytics continues to evolve, approaches like this that can extract rich, interpretable data from video footage will likely become increasingly important tools for enhancing athlete training, performance, and the overall spectator experience.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
3D Pose-Based Temporal Action Segmentation for Figure Skating: A Fine-Grained and Jump Procedure-Aware Annotation Approach
Ryota Tanaka, Tomohiro Suzuki, Keisuke Fujii
Understanding human actions from videos is essential in many domains, including sports. In figure skating, technical judgments are performed by watching skaters' 3D movements, and its part of the judging procedure can be regarded as a Temporal Action Segmentation (TAS) task. TAS tasks in figure skating that automatically assign temporal semantics to video are actively researched. However, there is a lack of datasets and effective methods for TAS tasks requiring 3D pose data. In this study, we first created the FS-Jump3D dataset of complex and dynamic figure skating jumps using optical markerless motion capture. We also propose a new fine-grained figure skating jump TAS dataset annotation method with which TAS models can learn jump procedures. In the experimental results, we validated the usefulness of 3D pose features as input and the fine-grained dataset for the TAS model in figure skating. FS-Jump3D Dataset is available at https://github.com/ryota-skating/FS-Jump3D.
Read more8/30/2024

0
Fine-grained Action Analysis: A Multi-modality and Multi-task Dataset of Figure Skating
Sheng-Lan Liu, Yu-Ning Ding, Gang Yan, Si-Fan Zhang, Jin-Rong Zhang, Wen-Yue Chen, Xue-Hai Xu
The fine-grained action analysis of the existing action datasets is challenged by insufficient action categories, low fine granularities, limited modalities, and tasks. In this paper, we propose a Multi-modality and Multi-task dataset of Figure Skating (MMFS) which was collected from the World Figure Skating Championships. MMFS, which possesses action recognition and action quality assessment, captures RGB, skeleton, and is collected the score of actions from 11671 clips with 256 categories including spatial and temporal labels. The key contributions of our dataset fall into three aspects as follows. (1) Independently spatial and temporal categories are first proposed to further explore fine-grained action recognition and quality assessment. (2) MMFS first introduces the skeleton modality for complex fine-grained action quality assessment. (3) Our multi-modality and multi-task dataset encourage more action analysis models. To benchmark our dataset, we adopt RGB-based and skeleton-based baseline methods for action recognition and action quality assessment.
Read more4/10/2024

0
ActionPose: Pretraining 3D Human Pose Estimation with the Dark Knowledge of Action
Longyun Liao, Rong Zheng
2D-to-3D human pose lifting is an ill-posed problem due to depth ambiguity and occlusion. Existing methods relying on spatial and temporal consistency alone are insufficient to resolve these problems because they lack semantic information of the motions. To overcome this, we propose ActionPose, a framework that leverages action knowledge by aligning motion embeddings with text embeddings of fine-grained action labels. ActionPose operates in two stages: pretraining and fine-tuning. In the pretraining stage, the model learns to recognize actions and reconstruct 3D poses from masked and noisy 2D poses. During the fine-tuning stage, the model is further refined using real-world 3D human pose estimation datasets without action labels. Additionally, our framework incorporates masked body parts and masked time windows in motion modeling to mitigate the effects of ambiguous boundaries between actions in both temporal and spatial domains. Experiments demonstrate the effectiveness of ActionPose, achieving state-of-the-art performance in 3D pose estimation on public datasets, including Human3.6M and MPI-INF-3DHP. Specifically, ActionPose achieves an MPJPE of 36.7mm on Human3.6M with detected 2D poses as input and 15.5mm on MPI-INF-3DHP with ground-truth 2D poses as input.
Read more9/4/2024
0
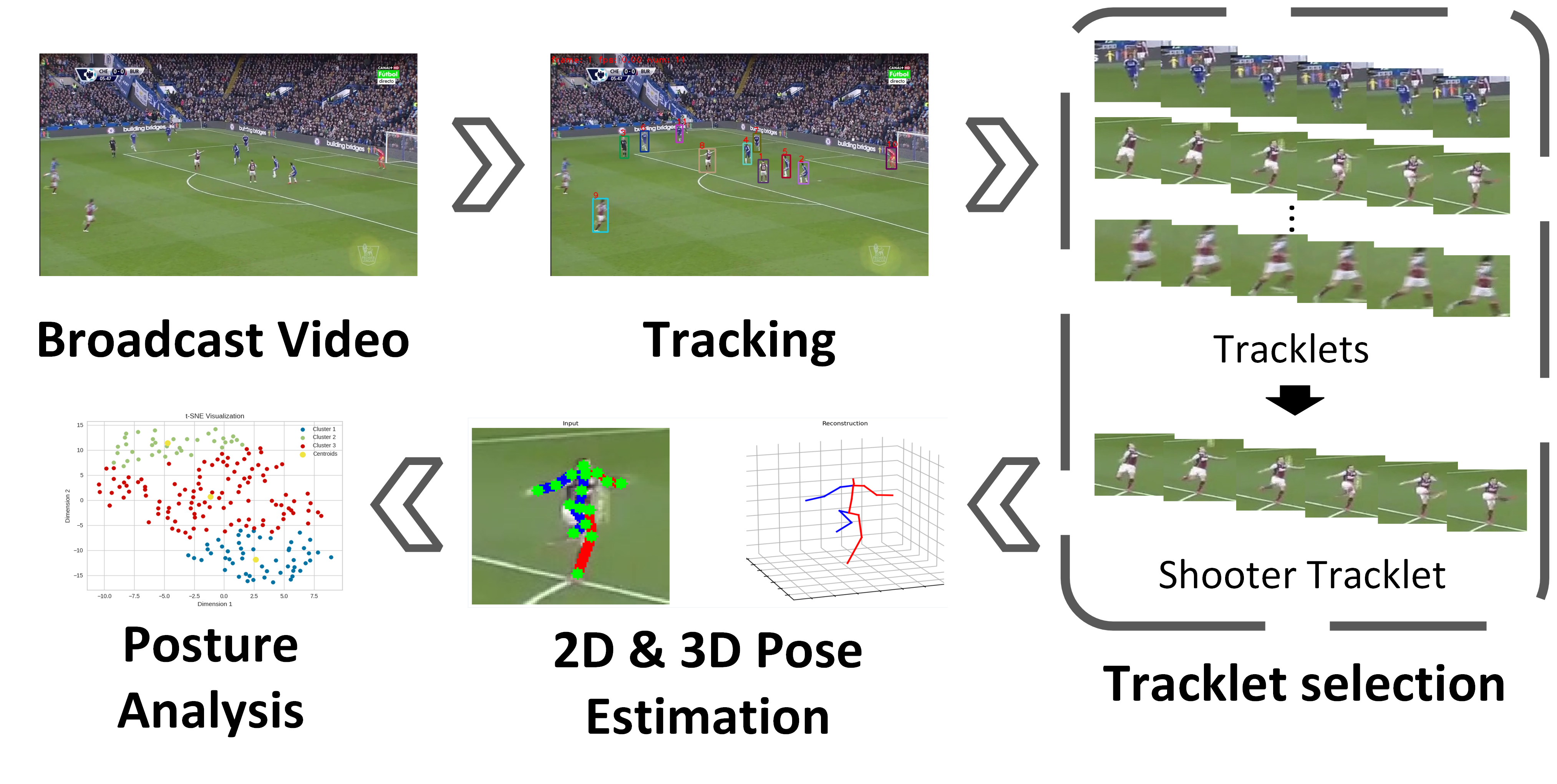
AutoSoccerPose: Automated 3D posture Analysis of Soccer Shot Movements
Calvin Yeung, Kenjiro Ide, Keisuke Fujii
Image understanding is a foundational task in computer vision, with recent applications emerging in soccer posture analysis. However, existing publicly available datasets lack comprehensive information, notably in the form of posture sequences and 2D pose annotations. Moreover, current analysis models often rely on interpretable linear models (e.g., PCA and regression), limiting their capacity to capture non-linear spatiotemporal relationships in complex and diverse scenarios. To address these gaps, we introduce the 3D Shot Posture (3DSP) dataset in soccer broadcast videos, which represents the most extensive sports image dataset with 2D pose annotations to our knowledge. Additionally, we present the 3DSP-GRAE (Graph Recurrent AutoEncoder) model, a non-linear approach for embedding pose sequences. Furthermore, we propose AutoSoccerPose, a pipeline aimed at semi-automating 2D and 3D pose estimation and posture analysis. While achieving full automation proved challenging, we provide a foundational baseline, extending its utility beyond the scope of annotated data. We validate AutoSoccerPose on SoccerNet and 3DSP datasets, and present posture analysis results based on 3DSP. The dataset, code, and models are available at: https://github.com/calvinyeungck/3D-Shot-Posture-Dataset.
Read more5/21/2024