AutoSoccerPose: Automated 3D posture Analysis of Soccer Shot Movements

0
Sign in to get full access
Overview
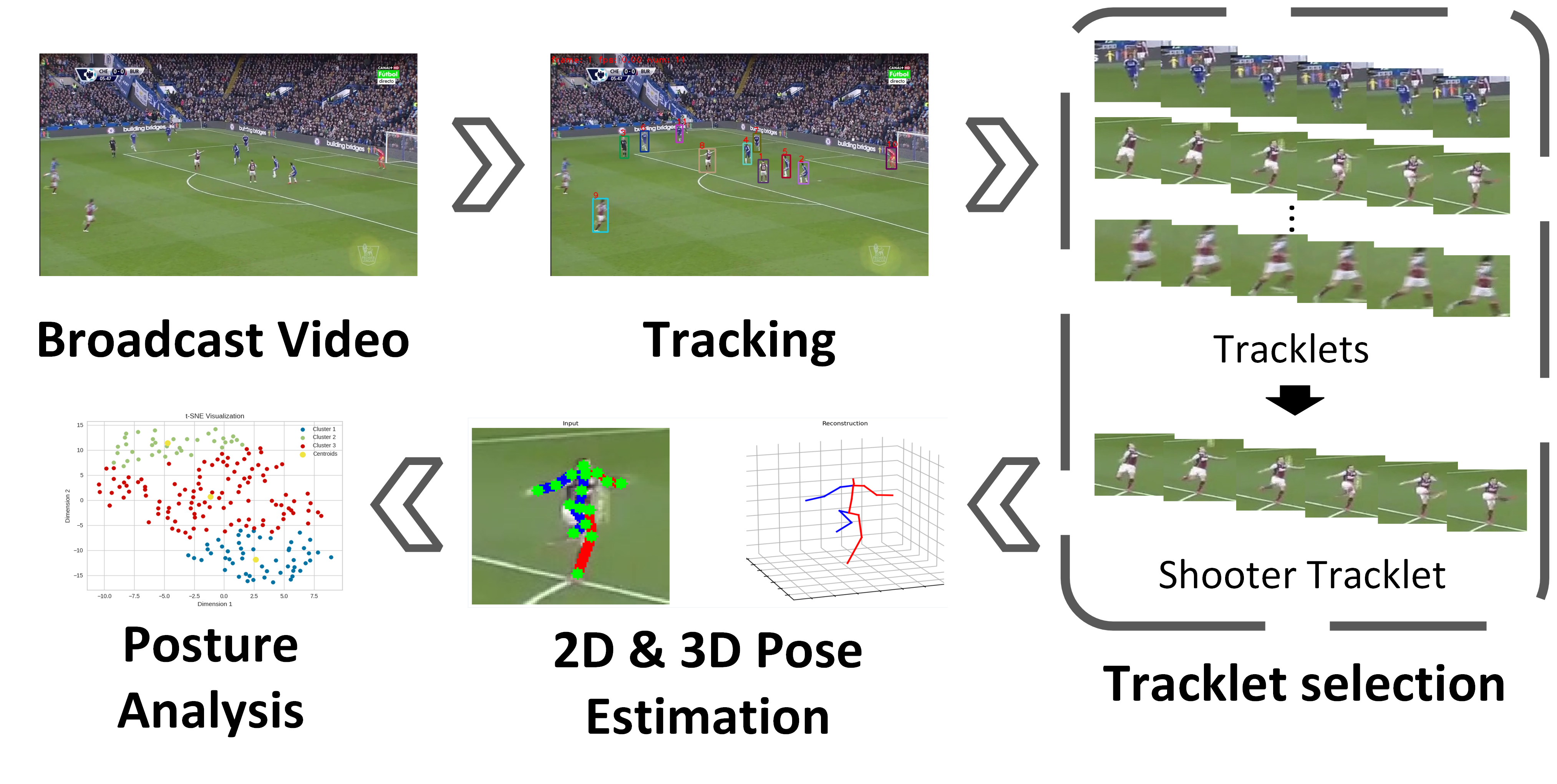
- This paper presents "AutoSoccerPose", a system for automated 3D posture analysis of soccer shot movements.
- The goal is to provide detailed biomechanical insights into soccer shooting techniques by using 3D human pose estimation methods.
- The system uses multi-view video recordings of soccer players to reconstruct their 3D body poses during shots on goal.
Plain English Explanation
The researchers developed a system called "AutoSoccerPose" that can analyze the 3D body positions and movements of soccer players as they take shots on goal. By using multiple video cameras to record the players from different angles, the system is able to reconstruct a 3D model of the player's body during the shooting motion. This allows the researchers to gather detailed information about the biomechanics and technique used by the players, which could be valuable for coaching, training, and injury prevention. The core idea is to leverage advanced 3D pose estimation methods to gain novel insights into the complex movements involved in soccer shooting.
Technical Explanation
The paper first reviews related work on 3D human pose estimation and multi-person 3D pose analysis. It then presents the AutoSoccerPose system, which uses multi-view video recordings of soccer players to reconstruct their 3D body poses during shot attempts. The system combines 2D pose estimation on individual camera views with multi-view 3D triangulation to obtain the final 3D pose. Key technical innovations include anomaly detection to handle occlusions and a self-supervised training approach to improve robustness. Experiments on a new soccer dataset demonstrate the system's ability to provide detailed biomechanical analysis of shooting motions.
Critical Analysis
The paper makes a compelling case for the value of automated 3D pose analysis in understanding complex sports movements like soccer shooting. By going beyond 2D video analysis, the system can provide much richer insights into the underlying biomechanics. However, the current implementation still has some limitations, such as the need for multi-view camera setups and potential issues with occlusions. Further research is needed to make the system more robust and practical for real-world coaching and training applications. Additionally, the ethical implications of such detailed biomechanical monitoring should be carefully considered.
Conclusion
The AutoSoccerPose system represents an innovative application of 3D human pose estimation technology to the domain of sports biomechanics. By providing automated, detailed analysis of soccer shooting movements, it has the potential to significantly advance our understanding of optimal technique and injury risk factors. While further development is needed, this research highlights the growing importance of computer vision and machine learning in sports science and performance analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AutoSoccerPose: Automated 3D posture Analysis of Soccer Shot Movements
Calvin Yeung, Kenjiro Ide, Keisuke Fujii
Image understanding is a foundational task in computer vision, with recent applications emerging in soccer posture analysis. However, existing publicly available datasets lack comprehensive information, notably in the form of posture sequences and 2D pose annotations. Moreover, current analysis models often rely on interpretable linear models (e.g., PCA and regression), limiting their capacity to capture non-linear spatiotemporal relationships in complex and diverse scenarios. To address these gaps, we introduce the 3D Shot Posture (3DSP) dataset in soccer broadcast videos, which represents the most extensive sports image dataset with 2D pose annotations to our knowledge. Additionally, we present the 3DSP-GRAE (Graph Recurrent AutoEncoder) model, a non-linear approach for embedding pose sequences. Furthermore, we propose AutoSoccerPose, a pipeline aimed at semi-automating 2D and 3D pose estimation and posture analysis. While achieving full automation proved challenging, we provide a foundational baseline, extending its utility beyond the scope of annotated data. We validate AutoSoccerPose on SoccerNet and 3DSP datasets, and present posture analysis results based on 3DSP. The dataset, code, and models are available at: https://github.com/calvinyeungck/3D-Shot-Posture-Dataset.
Read more5/21/2024
🌿
0
PoseScript: Linking 3D Human Poses and Natural Language
Ginger Delmas, Philippe Weinzaepfel, Thomas Lucas, Francesc Moreno-Noguer, Gr'egory Rogez
Natural language plays a critical role in many computer vision applications, such as image captioning, visual question answering, and cross-modal retrieval, to provide fine-grained semantic information. Unfortunately, while human pose is key to human understanding, current 3D human pose datasets lack detailed language descriptions. To address this issue, we have introduced the PoseScript dataset. This dataset pairs more than six thousand 3D human poses from AMASS with rich human-annotated descriptions of the body parts and their spatial relationships. Additionally, to increase the size of the dataset to a scale that is compatible with data-hungry learning algorithms, we have proposed an elaborate captioning process that generates automatic synthetic descriptions in natural language from given 3D keypoints. This process extracts low-level pose information, known as posecodes, using a set of simple but generic rules on the 3D keypoints. These posecodes are then combined into higher level textual descriptions using syntactic rules. With automatic annotations, the amount of available data significantly scales up (100k), making it possible to effectively pretrain deep models for finetuning on human captions. To showcase the potential of annotated poses, we present three multi-modal learning tasks that utilize the PoseScript dataset. Firstly, we develop a pipeline that maps 3D poses and textual descriptions into a joint embedding space, allowing for cross-modal retrieval of relevant poses from large-scale datasets. Secondly, we establish a baseline for a text-conditioned model generating 3D poses. Thirdly, we present a learned process for generating pose descriptions. These applications demonstrate the versatility and usefulness of annotated poses in various tasks and pave the way for future research in the field.
Read more9/11/2024
📊
0
Multi-person 3D pose estimation from unlabelled data
Daniel Rodriguez-Criado, Pilar Bachiller, George Vogiatzis, Luis J. Manso
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
Read more4/10/2024
0
Open-Pose 3D Zero-Shot Learning: Benchmark and Challenges
Weiguang Zhao, Guanyu Yang, Rui Zhang, Chenru Jiang, Chaolong Yang, Yuyao Yan, Amir Hussain, Kaizhu Huang
With the explosive 3D data growth, the urgency of utilizing zero-shot learning to facilitate data labeling becomes evident. Recently, methods transferring language or language-image pre-training models like Contrastive Language-Image Pre-training (CLIP) to 3D vision have made significant progress in the 3D zero-shot classification task. These methods primarily focus on 3D object classification with an aligned pose; such a setting is, however, rather restrictive, which overlooks the recognition of 3D objects with open poses typically encountered in real-world scenarios, such as an overturned chair or a lying teddy bear. To this end, we propose a more realistic and challenging scenario named open-pose 3D zero-shot classification, focusing on the recognition of 3D objects regardless of their orientation. First, we revisit the current research on 3D zero-shot classification, and propose two benchmark datasets specifically designed for the open-pose setting. We empirically validate many of the most popular methods in the proposed open-pose benchmark. Our investigations reveal that most current 3D zero-shot classification models suffer from poor performance, indicating a substantial exploration room towards the new direction. Furthermore, we study a concise pipeline with an iterative angle refinement mechanism that automatically optimizes one ideal angle to classify these open-pose 3D objects. In particular, to make validation more compelling and not just limited to existing CLIP-based methods, we also pioneer the exploration of knowledge transfer based on Diffusion models. While the proposed solutions can serve as a new benchmark for open-pose 3D zero-shot classification, we discuss the complexities and challenges of this scenario that remain for further research development. The code is available publicly at https://github.com/weiguangzhao/Diff-OP3D.
Read more4/17/2024