Fine-grained Action Analysis: A Multi-modality and Multi-task Dataset of Figure Skating

0

Sign in to get full access
Overview
- The paper presents a multi-modality and multi-task dataset for fine-grained action analysis, focusing on figure skating.
- The dataset includes video, audio, and motion capture data, along with annotations for action recognition and quality assessment.
- The researchers aim to advance the field of fine-grained action analysis by providing a comprehensive dataset and establishing benchmark tasks.
Plain English Explanation
The researchers have created a new dataset to help AI systems better understand and evaluate complex human actions, specifically in the context of figure skating. Figure skating involves intricate movements and techniques that are challenging to analyze in detail.
This dataset includes various types of data, such as video footage, audio recordings, and motion capture data, which can provide a more comprehensive view of the skaters' movements and performances. The researchers have also annotated the data, labeling the specific actions and assessing the quality of the skaters' performances.
By making this dataset publicly available, the researchers hope to encourage other researchers and developers to work on improving AI's ability to recognize and assess fine-grained actions, not just broad categories of movement. This could have applications in sports coaching, performance analysis, and other domains where a detailed understanding of human movement is crucial.
Technical Explanation
The paper presents a new multi-modality and multi-task dataset for fine-grained action analysis, focusing on the domain of figure skating. The dataset includes video, audio, and motion capture data collected from professional figure skating competitions and training sessions.
The researchers have annotated the dataset with labels for action recognition and quality assessment. The action recognition task involves identifying the specific techniques and elements performed by the skaters, such as jumps, spins, and step sequences. The quality assessment task requires evaluating the overall execution and performance of the skaters.
By providing this comprehensive dataset, the researchers aim to establish benchmark tasks for fine-grained action analysis and encourage further research in this area. Fine-grained action analysis is a challenging problem, as it requires understanding the nuances and subtleties of human movement, which can be difficult for traditional action recognition models to capture.
The dataset's multimodal nature, combining video, audio, and motion capture data, is intended to enable more holistic and accurate modeling of the complex movements and techniques involved in figure skating. The researchers also explore semi-supervised and active learning approaches to address the challenges of annotating large-scale fine-grained action datasets.
Critical Analysis
The paper presents a well-designed and comprehensive dataset for fine-grained action analysis in figure skating. The inclusion of multiple modalities, such as video, audio, and motion capture data, is a valuable contribution, as it can provide a more complete and nuanced understanding of the skaters' movements and performances.
However, the dataset is limited to a single domain, figure skating, which may limit the generalizability of the proposed methods to other fine-grained action domains. The researchers acknowledge this limitation and suggest that extending the dataset to other sports or activities could be a fruitful area for future research.
Additionally, the quality assessment task may be subjective and challenging to annotate consistently, as different judges or experts may have varying opinions on the execution and performance of the skaters. The researchers address this issue by involving multiple expert annotators, but the reliability and reproducibility of the quality assessments could be further investigated.
The [paper also mentions the potential for the dataset to be used in 360-degree and multi-modal scene understanding, which could expand the dataset's applications beyond fine-grained action analysis. However, the specific details and feasibility of this application are not explored in depth.
Conclusion
This paper presents a valuable multi-modality and multi-task dataset for fine-grained action analysis, focusing on the domain of figure skating. The dataset's comprehensive nature, including video, audio, and motion capture data, coupled with annotations for action recognition and quality assessment, provides a strong foundation for advancing research in this challenging field.
By establishing benchmark tasks and encouraging further exploration of fine-grained action analysis, the researchers hope to contribute to the development of more sophisticated AI systems capable of understanding and evaluating complex human movements and performances. The potential applications of this research range from sports coaching and performance analysis to broader domains where a detailed understanding of human actions is crucial.
While the dataset is currently limited to the figure skating domain, the researchers' suggestions for expanding it to other sports or activities present exciting opportunities for future research. Overall, this work represents a significant step forward in the quest to build AI systems that can truly comprehend and appreciate the nuances of human movement and action.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fine-grained Action Analysis: A Multi-modality and Multi-task Dataset of Figure Skating
Sheng-Lan Liu, Yu-Ning Ding, Gang Yan, Si-Fan Zhang, Jin-Rong Zhang, Wen-Yue Chen, Xue-Hai Xu
The fine-grained action analysis of the existing action datasets is challenged by insufficient action categories, low fine granularities, limited modalities, and tasks. In this paper, we propose a Multi-modality and Multi-task dataset of Figure Skating (MMFS) which was collected from the World Figure Skating Championships. MMFS, which possesses action recognition and action quality assessment, captures RGB, skeleton, and is collected the score of actions from 11671 clips with 256 categories including spatial and temporal labels. The key contributions of our dataset fall into three aspects as follows. (1) Independently spatial and temporal categories are first proposed to further explore fine-grained action recognition and quality assessment. (2) MMFS first introduces the skeleton modality for complex fine-grained action quality assessment. (3) Our multi-modality and multi-task dataset encourage more action analysis models. To benchmark our dataset, we adopt RGB-based and skeleton-based baseline methods for action recognition and action quality assessment.
Read more4/10/2024
0
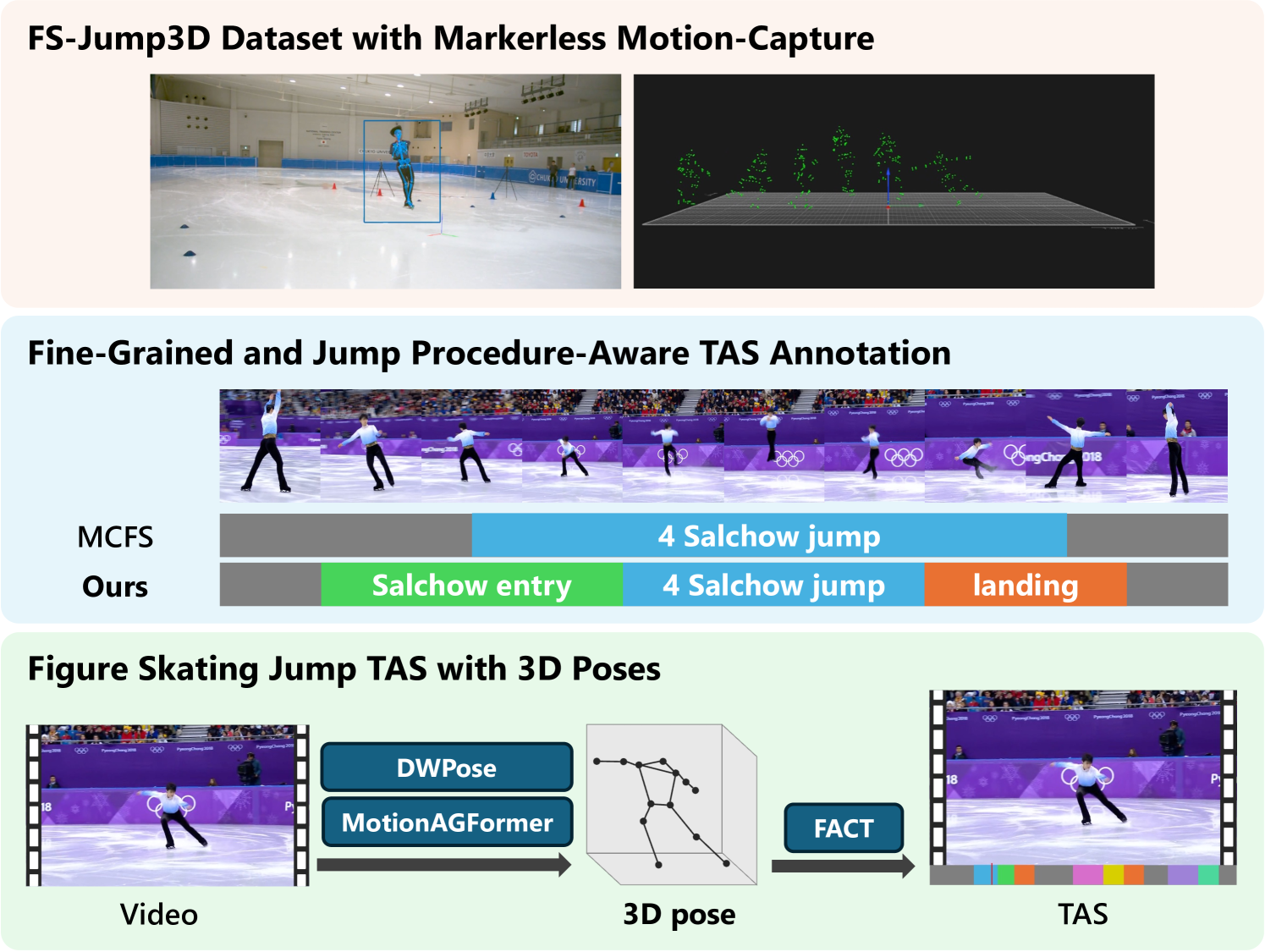
3D Pose-Based Temporal Action Segmentation for Figure Skating: A Fine-Grained and Jump Procedure-Aware Annotation Approach
Ryota Tanaka, Tomohiro Suzuki, Keisuke Fujii
Understanding human actions from videos is essential in many domains, including sports. In figure skating, technical judgments are performed by watching skaters' 3D movements, and its part of the judging procedure can be regarded as a Temporal Action Segmentation (TAS) task. TAS tasks in figure skating that automatically assign temporal semantics to video are actively researched. However, there is a lack of datasets and effective methods for TAS tasks requiring 3D pose data. In this study, we first created the FS-Jump3D dataset of complex and dynamic figure skating jumps using optical markerless motion capture. We also propose a new fine-grained figure skating jump TAS dataset annotation method with which TAS models can learn jump procedures. In the experimental results, we validated the usefulness of 3D pose features as input and the fine-grained dataset for the TAS model in figure skating. FS-Jump3D Dataset is available at https://github.com/ryota-skating/FS-Jump3D.
Read more8/30/2024

0
Multi-Modality Co-Learning for Efficient Skeleton-based Action Recognition
Jinfu Liu, Chen Chen, Mengyuan Liu
Skeleton-based action recognition has garnered significant attention due to the utilization of concise and resilient skeletons. Nevertheless, the absence of detailed body information in skeletons restricts performance, while other multimodal methods require substantial inference resources and are inefficient when using multimodal data during both training and inference stages. To address this and fully harness the complementary multimodal features, we propose a novel multi-modality co-learning (MMCL) framework by leveraging the multimodal large language models (LLMs) as auxiliary networks for efficient skeleton-based action recognition, which engages in multi-modality co-learning during the training stage and keeps efficiency by employing only concise skeletons in inference. Our MMCL framework primarily consists of two modules. First, the Feature Alignment Module (FAM) extracts rich RGB features from video frames and aligns them with global skeleton features via contrastive learning. Second, the Feature Refinement Module (FRM) uses RGB images with temporal information and text instruction to generate instructive features based on the powerful generalization of multimodal LLMs. These instructive text features will further refine the classification scores and the refined scores will enhance the model's robustness and generalization in a manner similar to soft labels. Extensive experiments on NTU RGB+D, NTU RGB+D 120 and Northwestern-UCLA benchmarks consistently verify the effectiveness of our MMCL, which outperforms the existing skeleton-based action recognition methods. Meanwhile, experiments on UTD-MHAD and SYSU-Action datasets demonstrate the commendable generalization of our MMCL in zero-shot and domain-adaptive action recognition. Our code is publicly available at: https://github.com/liujf69/MMCL-Action.
Read more8/7/2024

0
Multi-Granularity Hand Action Detection
Ting Zhe, Jing Zhang, Yongqian Li, Yong Luo, Han Hu, Dacheng Tao
Detecting hand actions in videos is crucial for understanding video content and has diverse real-world applications. Existing approaches often focus on whole-body actions or coarse-grained action categories, lacking fine-grained hand-action localization information. To fill this gap, we introduce the FHA-Kitchens (Fine-Grained Hand Actions in Kitchen Scenes) dataset, providing both coarse- and fine-grained hand action categories along with localization annotations. This dataset comprises 2,377 video clips and 30,047 frames, annotated with approximately 200k bounding boxes and 880 action categories. Evaluation of existing action detection methods on FHA-Kitchens reveals varying generalization capabilities across different granularities. To handle multi-granularity in hand actions, we propose MG-HAD, an End-to-End Multi-Granularity Hand Action Detection method. It incorporates two new designs: Multi-dimensional Action Queries and Coarse-Fine Contrastive Denoising. Extensive experiments demonstrate MG-HAD's effectiveness for multi-granularity hand action detection, highlighting the significance of FHA-Kitchens for future research and real-world applications. The dataset and source code are available at https://github.com/superZ678/MG-HAD.
Read more8/13/2024