3D Small Object Detection with Dynamic Spatial Pruning

0
🔎
Sign in to get full access
Overview
- The researchers propose an efficient feature pruning strategy for 3D small object detection.
- Conventional 3D object detection methods struggle with small objects due to weak geometric information.
- Increasing spatial resolution can improve small object detection, but is computationally expensive.
- The researchers present a multi-level 3D detector called DSPDet3D that achieves high accuracy on small objects while reducing redundant computation.
Plain English Explanation
The paper focuses on improving 3D object detection, which is the task of identifying and locating objects in 3D space from sensor data like lidar. The researchers point out that current 3D object detection methods have trouble with small objects, like cups or chairs, because there are only a few sensor points representing these small items.
One way to improve small object detection would be to use a higher resolution 3D feature representation, which would capture more detail. However, the researchers explain that this increased resolution comes with a big computational cost that makes it impractical.
To get the benefits of high resolution without the high costs, the researchers developed a new 3D object detector called DSPDet3D. This detector has a special module that dynamically prunes the 3D feature representation, focusing computing power only on areas likely to contain small objects. This allows DSPDet3D to achieve high accuracy on small objects while being much more efficient than brute force high resolution approaches.
The researchers show that DSPDet3D outperforms other 3D detectors on small object detection benchmarks. It can also generalize well, detecting a wide range of objects in large building scenes using only training data from smaller room scenes.
Technical Explanation
The key technical innovation in this work is the "Dynamic Spatial Pruning" (DSP) strategy that selectively focuses the 3D feature representation on areas likely to contain small objects.
The researchers first observe that the main computational cost in 3D detectors comes from the upsampling operations in the decoder, which expand the feature maps to higher resolutions. To address this, they derive a theoretical DSP strategy that prunes the 3D feature maps in a cascading manner, based on the spatial distribution of objects in the scene.
The DSPDet3D architecture implements this DSP strategy with a dedicated DSP module. This module progressively focuses the 3D features on smaller spatial regions that are more likely to contain small objects, while discarding irrelevant spatial areas. This allows DSPDet3D to achieve high-resolution feature representations for small objects without the full computational cost.
Experiments on the ScanNet and TO-SCENE benchmarks show that DSPDet3D outperforms other 3D detectors on small object detection, while also being efficient enough to process large building-scale scenes in under 2 seconds on a single GPU. The researchers also demonstrate that a DSPDet3D model trained only on smaller room scenes can generalize well to larger building environments, highlighting the effectiveness of the DSP strategy.
Critical Analysis
The key strength of this work is the clever DSP strategy that allows high-resolution 3D features for small objects without the usual computational overhead. This is an important practical innovation for 3D object detection, which has struggled with small objects.
However, the paper does not provide much insight into the underlying reasons why the DSP strategy is effective. The theoretical derivation is not explained in depth, making it difficult to fully understand the intuition behind the approach.
Additionally, the experiments are limited to indoor scene datasets like ScanNet and TO-SCENE. It would be valuable to see how well the DSPDet3D approach generalizes to more diverse outdoor environments with a wider range of object scales.
Further research could also explore the limits of the DSP strategy - there may be scenes or object sizes where the pruning becomes too aggressive and starts to degrade performance. Investigating these edge cases would help provide a more complete understanding of the method's strengths and weaknesses.
Overall, this is a promising work that tackles an important problem in 3D object detection. The DSP-based architecture demonstrates strong results, but could benefit from deeper technical explanations and more comprehensive evaluation to fully assess its capabilities.
Conclusion
This paper presents an efficient 3D object detection method called DSPDet3D that addresses the challenge of small object detection. By dynamically pruning the 3D feature representation to focus computing power on areas likely to contain small objects, DSPDet3D achieves high accuracy on small objects while being significantly more efficient than brute force high-resolution approaches.
The key innovation is the Dynamic Spatial Pruning (DSP) strategy, which selectively discards irrelevant spatial areas in a cascading manner. This allows DSPDet3D to maintain high-resolution features for small objects without the heavy computational burden.
Experiments show DSPDet3D outperforming other 3D detectors on small object benchmarks, while also demonstrating the ability to generalize from smaller room scenes to larger building-scale environments. This work represents an important step forward in making 3D object detection more robust and practical, particularly for applications involving a wide range of object sizes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
3D Small Object Detection with Dynamic Spatial Pruning
Xiuwei Xu, Zhihao Sun, Ziwei Wang, Hongmin Liu, Jie Zhou, Jiwen Lu
In this paper, we propose an efficient feature pruning strategy for 3D small object detection. Conventional 3D object detection methods struggle on small objects due to the weak geometric information from a small number of points. Although increasing the spatial resolution of feature representations can improve the detection performance on small objects, the additional computational overhead is unaffordable. With in-depth study, we observe the growth of computation mainly comes from the upsampling operation in the decoder of 3D detector. Motivated by this, we present a multi-level 3D detector named DSPDet3D which benefits from high spatial resolution to achieves high accuracy on small object detection, while reducing redundant computation by only focusing on small object areas. Specifically, we theoretically derive a dynamic spatial pruning (DSP) strategy to prune the redundant spatial representation of 3D scene in a cascade manner according to the distribution of objects. Then we design DSP module following this strategy and construct DSPDet3D with this efficient module. On ScanNet and TO-SCENE dataset, our method achieves leading performance on small object detection. Moreover, DSPDet3D trained with only ScanNet rooms can generalize well to scenes in larger scale. It takes less than 2s to directly process a whole building consisting of more than 4500k points while detecting out almost all objects, ranging from cups to beds, on a single RTX 3090 GPU. Project page: https://xuxw98.github.io/DSPDet3D/.
Read more7/16/2024

0
SparseDet: A Simple and Effective Framework for Fully Sparse LiDAR-based 3D Object Detection
Lin Liu, Ziying Song, Qiming Xia, Feiyang Jia, Caiyan Jia, Lei Yang, Hongyu Pan
LiDAR-based sparse 3D object detection plays a crucial role in autonomous driving applications due to its computational efficiency advantages. Existing methods either use the features of a single central voxel as an object proxy, or treat an aggregated cluster of foreground points as an object proxy. However, the former lacks the ability to aggregate contextual information, resulting in insufficient information expression in object proxies. The latter relies on multi-stage pipelines and auxiliary tasks, which reduce the inference speed. To maintain the efficiency of the sparse framework while fully aggregating contextual information, in this work, we propose SparseDet which designs sparse queries as object proxies. It introduces two key modules, the Local Multi-scale Feature Aggregation (LMFA) module and the Global Feature Aggregation (GFA) module, aiming to fully capture the contextual information, thereby enhancing the ability of the proxies to represent objects. Where LMFA sub-module achieves feature fusion across different scales for sparse key voxels %which does this through via coordinate transformations and using nearest neighbor relationships to capture object-level details and local contextual information, GFA sub-module uses self-attention mechanisms to selectively aggregate the features of the key voxels across the entire scene for capturing scene-level contextual information. Experiments on nuScenes and KITTI demonstrate the effectiveness of our method. Specifically, on nuScene, SparseDet surpasses the previous best sparse detector VoxelNeXt by 2.2% mAP with 13.5 FPS, and on KITTI, it surpasses VoxelNeXt by 1.12% $mathbf{AP_{3D}}$ on hard level tasks with 17.9 FPS.
Read more6/18/2024
0
Boosting 3D Object Detection with Semantic-Aware Multi-Branch Framework
Hao Jing, Anhong Wang, Lijun Zhao, Yakun Yang, Donghan Bu, Jing Zhang, Yifan Zhang, Junhui Hou
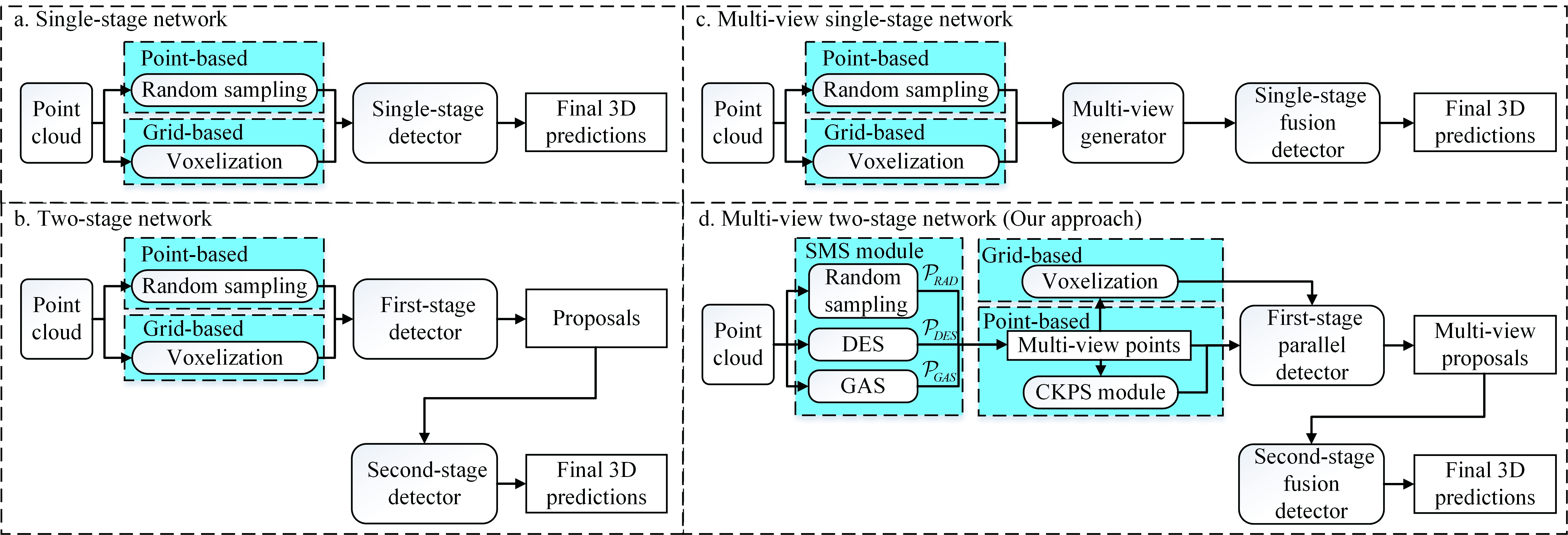
In autonomous driving, LiDAR sensors are vital for acquiring 3D point clouds, providing reliable geometric information. However, traditional sampling methods of preprocessing often ignore semantic features, leading to detail loss and ground point interference in 3D object detection. To address this, we propose a multi-branch two-stage 3D object detection framework using a Semantic-aware Multi-branch Sampling (SMS) module and multi-view consistency constraints. The SMS module includes random sampling, Density Equalization Sampling (DES) for enhancing distant objects, and Ground Abandonment Sampling (GAS) to focus on non-ground points. The sampled multi-view points are processed through a Consistent KeyPoint Selection (CKPS) module to generate consistent keypoint masks for efficient proposal sampling. The first-stage detector uses multi-branch parallel learning with multi-view consistency loss for feature aggregation, while the second-stage detector fuses multi-view data through a Multi-View Fusion Pooling (MVFP) module to precisely predict 3D objects. The experimental results on KITTI 3D object detection benchmark dataset show that our method achieves excellent detection performance improvement for a variety of backbones, especially for low-performance backbones with the simple network structures.
Read more7/9/2024

0
Sparse Points to Dense Clouds: Enhancing 3D Detection with Limited LiDAR Data
Aakash Kumar, Chen Chen, Ajmal Mian, Neils Lobo, Mubarak Shah
3D detection is a critical task that enables machines to identify and locate objects in three-dimensional space. It has a broad range of applications in several fields, including autonomous driving, robotics and augmented reality. Monocular 3D detection is attractive as it requires only a single camera, however, it lacks the accuracy and robustness required for real world applications. High resolution LiDAR on the other hand, can be expensive and lead to interference problems in heavy traffic given their active transmissions. We propose a balanced approach that combines the advantages of monocular and point cloud-based 3D detection. Our method requires only a small number of 3D points, that can be obtained from a low-cost, low-resolution sensor. Specifically, we use only 512 points, which is just 1% of a full LiDAR frame in the KITTI dataset. Our method reconstructs a complete 3D point cloud from this limited 3D information combined with a single image. The reconstructed 3D point cloud and corresponding image can be used by any multi-modal off-the-shelf detector for 3D object detection. By using the proposed network architecture with an off-the-shelf multi-modal 3D detector, the accuracy of 3D detection improves by 20% compared to the state-of-the-art monocular detection methods and 6% to 9% compare to the baseline multi-modal methods on KITTI and JackRabbot datasets.
Read more4/11/2024