Boosting 3D Object Detection with Semantic-Aware Multi-Branch Framework

0
Sign in to get full access
Overview
- The paper proposes a semantic-aware multi-branch framework to boost 3D object detection performance.
- It leverages semantic information to enhance the feature representation and improve object detection.
- The framework includes a semantic branch to capture object-level semantics and a point-level branch to extract local geometric features.
Plain English Explanation
The researchers have developed a new approach to improve the accuracy of 3D object detection, which is an important task in areas like self-driving cars and robotics. Their method takes advantage of semantic information, or the meaning and context of the objects in the 3D scene, to enhance the detection model's understanding of the 3D data.
Traditionally, 3D object detection models have relied primarily on the geometric shape and position of objects in the 3D point cloud data. However, the new framework adds a "semantic branch" that specifically learns to recognize the semantic category and attributes of the objects. This semantic information is then combined with the geometric features extracted by another branch of the model, allowing the system to better identify and localize the objects in the 3D scene.
By incorporating this semantic-aware approach, the researchers were able to demonstrate improved performance on standard 3D object detection benchmarks compared to existing methods. The semantic understanding helps the model make more accurate and reliable object detections, which could be valuable for applications like autonomous vehicles and robotic systems.
Technical Explanation
The paper introduces a semantic-aware multi-branch framework for 3D object detection. The key components of the framework are:
-
Semantic Branch: This branch is designed to capture the semantic information of the objects, such as their category and attributes. It takes the 3D point cloud as input and outputs semantic segmentation predictions for each point.
-
Geometric Branch: This branch focuses on extracting local geometric features from the 3D point cloud, which are important for accurately localizing and classifying the objects.
-
Feature Fusion: The outputs of the semantic and geometric branches are combined through a feature fusion module, allowing the model to leverage both semantic and geometric cues for improved object detection.
The researchers evaluate their framework on several popular 3D object detection benchmarks, including KITTI and nuScenes. They demonstrate that their semantic-aware approach outperforms existing 3D object detection methods, particularly in challenging scenarios with occlusion or sparse point clouds.
Critical Analysis
One of the key strengths of the proposed framework is its ability to incorporate semantic information to boost the performance of 3D object detection. This is an important advancement, as existing methods have largely focused on geometric features alone, which can be limited in complex real-world scenarios.
However, the paper does not provide a detailed analysis of the computational complexity or inference time of the multi-branch framework. This is an important consideration, especially for time-sensitive applications like autonomous driving.
Additionally, the paper could have discussed the potential limitations of the semantic segmentation task and how errors in this upstream task might impact the overall object detection performance. Further research could explore ways to make the framework more robust to imperfect semantic information.
Conclusion
The proposed semantic-aware multi-branch framework represents a promising approach for improving 3D object detection. By leveraging semantic information in addition to geometric features, the model can better understand and localize objects in 3D scenes. This could have significant implications for a wide range of applications, from autonomous vehicles to robotic systems, where accurate 3D perception is crucial. While the paper provides a strong technical foundation, future work could explore ways to further enhance the efficiency and robustness of the framework.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Boosting 3D Object Detection with Semantic-Aware Multi-Branch Framework
Hao Jing, Anhong Wang, Lijun Zhao, Yakun Yang, Donghan Bu, Jing Zhang, Yifan Zhang, Junhui Hou
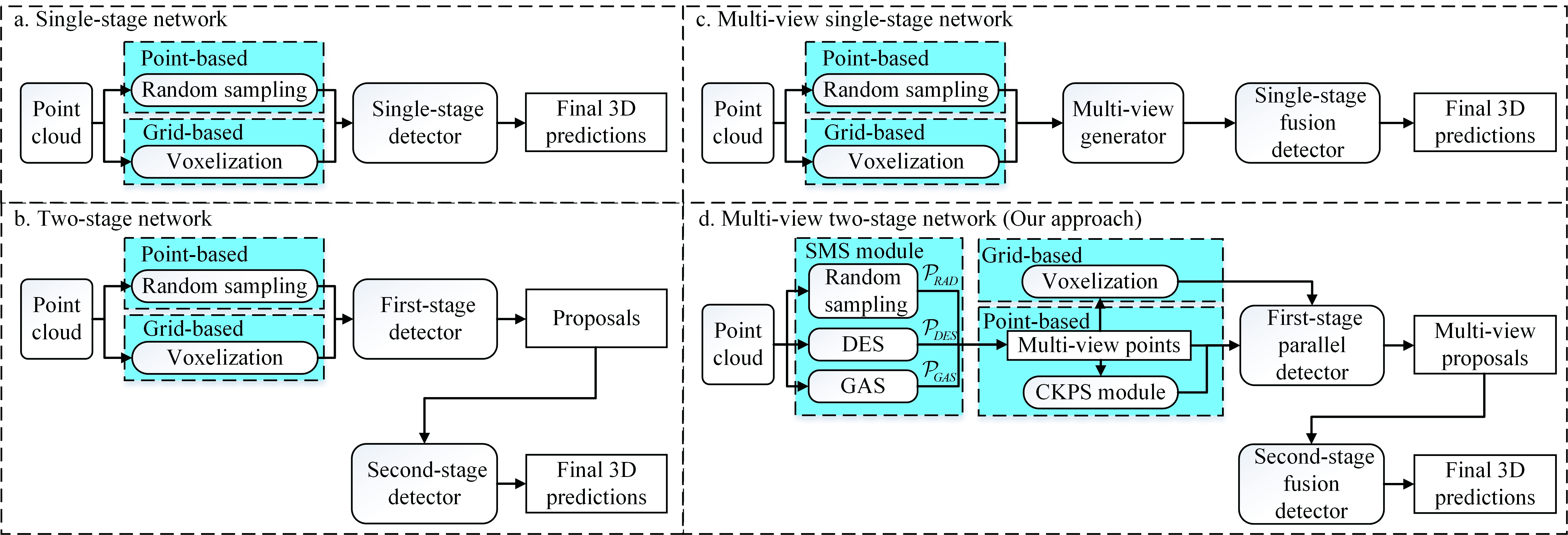
In autonomous driving, LiDAR sensors are vital for acquiring 3D point clouds, providing reliable geometric information. However, traditional sampling methods of preprocessing often ignore semantic features, leading to detail loss and ground point interference in 3D object detection. To address this, we propose a multi-branch two-stage 3D object detection framework using a Semantic-aware Multi-branch Sampling (SMS) module and multi-view consistency constraints. The SMS module includes random sampling, Density Equalization Sampling (DES) for enhancing distant objects, and Ground Abandonment Sampling (GAS) to focus on non-ground points. The sampled multi-view points are processed through a Consistent KeyPoint Selection (CKPS) module to generate consistent keypoint masks for efficient proposal sampling. The first-stage detector uses multi-branch parallel learning with multi-view consistency loss for feature aggregation, while the second-stage detector fuses multi-view data through a Multi-View Fusion Pooling (MVFP) module to precisely predict 3D objects. The experimental results on KITTI 3D object detection benchmark dataset show that our method achieves excellent detection performance improvement for a variety of backbones, especially for low-performance backbones with the simple network structures.
Read more7/9/2024

0
Sparse Points to Dense Clouds: Enhancing 3D Detection with Limited LiDAR Data
Aakash Kumar, Chen Chen, Ajmal Mian, Neils Lobo, Mubarak Shah
3D detection is a critical task that enables machines to identify and locate objects in three-dimensional space. It has a broad range of applications in several fields, including autonomous driving, robotics and augmented reality. Monocular 3D detection is attractive as it requires only a single camera, however, it lacks the accuracy and robustness required for real world applications. High resolution LiDAR on the other hand, can be expensive and lead to interference problems in heavy traffic given their active transmissions. We propose a balanced approach that combines the advantages of monocular and point cloud-based 3D detection. Our method requires only a small number of 3D points, that can be obtained from a low-cost, low-resolution sensor. Specifically, we use only 512 points, which is just 1% of a full LiDAR frame in the KITTI dataset. Our method reconstructs a complete 3D point cloud from this limited 3D information combined with a single image. The reconstructed 3D point cloud and corresponding image can be used by any multi-modal off-the-shelf detector for 3D object detection. By using the proposed network architecture with an off-the-shelf multi-modal 3D detector, the accuracy of 3D detection improves by 20% compared to the state-of-the-art monocular detection methods and 6% to 9% compare to the baseline multi-modal methods on KITTI and JackRabbot datasets.
Read more4/11/2024
0
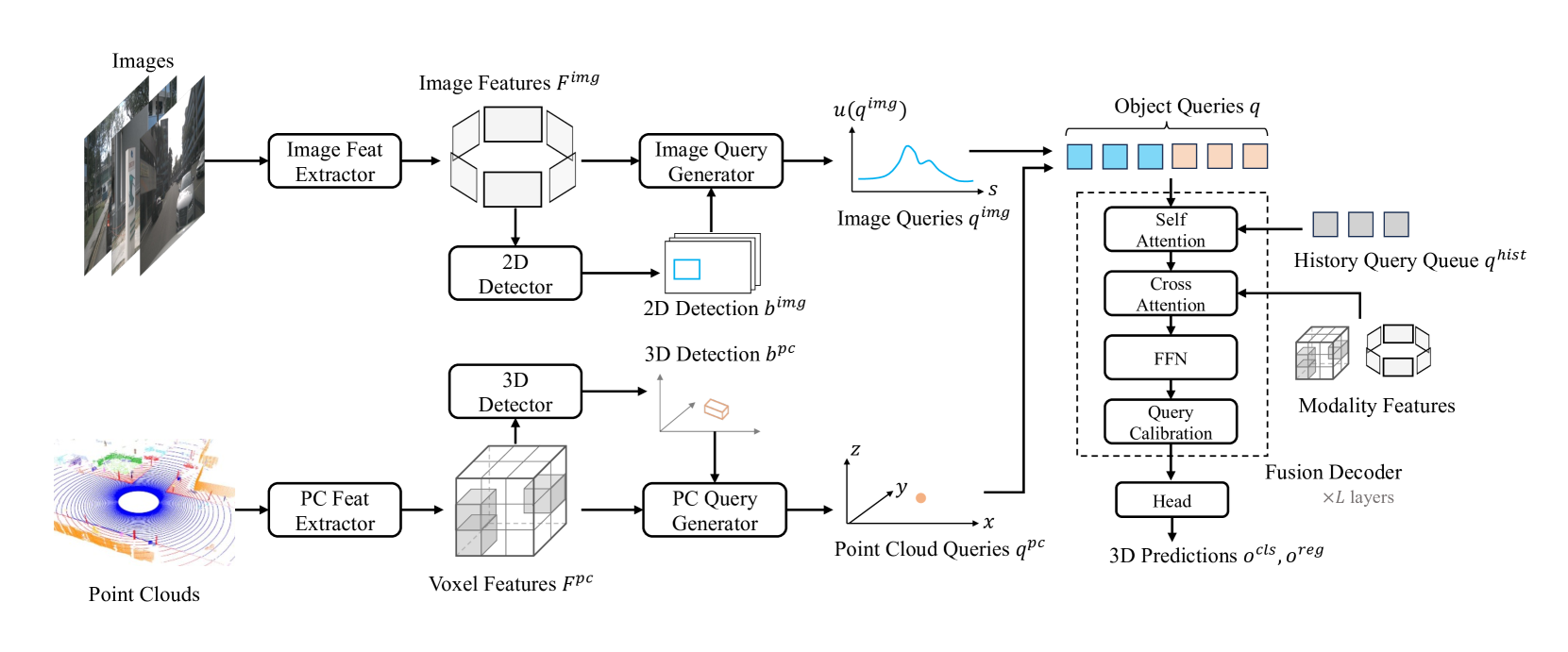
MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection
Zitian Wang, Zehao Huang, Yulu Gao, Naiyan Wang, Si Liu
The rise of autonomous vehicles has significantly increased the demand for robust 3D object detection systems. While cameras and LiDAR sensors each offer unique advantages--cameras provide rich texture information and LiDAR offers precise 3D spatial data--relying on a single modality often leads to performance limitations. This paper introduces MV2DFusion, a multi-modal detection framework that integrates the strengths of both worlds through an advanced query-based fusion mechanism. By introducing an image query generator to align with image-specific attributes and a point cloud query generator, MV2DFusion effectively combines modality-specific object semantics without biasing toward one single modality. Then the sparse fusion process can be accomplished based on the valuable object semantics, ensuring efficient and accurate object detection across various scenarios. Our framework's flexibility allows it to integrate with any image and point cloud-based detectors, showcasing its adaptability and potential for future advancements. Extensive evaluations on the nuScenes and Argoverse2 datasets demonstrate that MV2DFusion achieves state-of-the-art performance, particularly excelling in long-range detection scenarios.
Read more8/13/2024
0
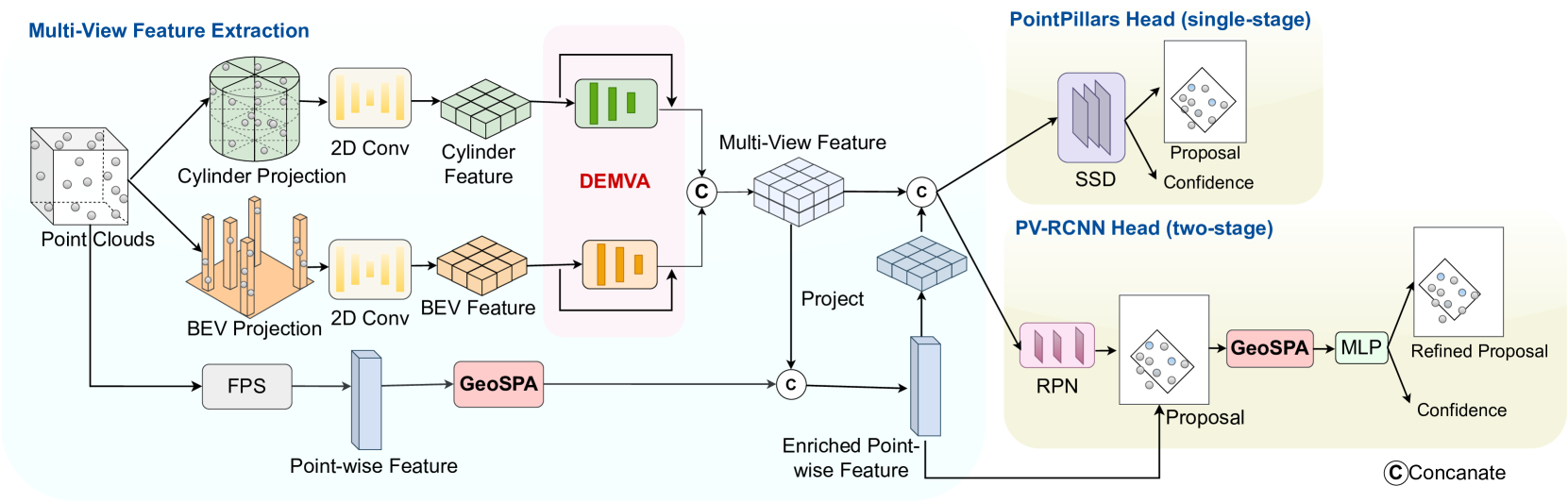
MUFASA: Multi-View Fusion and Adaptation Network with Spatial Awareness for Radar Object Detection
Xiangyuan Peng, Miao Tang, Huawei Sun, Kay Bierzynski, Lorenzo Servadei, Robert Wille
In recent years, approaches based on radar object detection have made significant progress in autonomous driving systems due to their robustness under adverse weather compared to LiDAR. However, the sparsity of radar point clouds poses challenges in achieving precise object detection, highlighting the importance of effective and comprehensive feature extraction technologies. To address this challenge, this paper introduces a comprehensive feature extraction method for radar point clouds. This study first enhances the capability of detection networks by using a plug-and-play module, GeoSPA. It leverages the Lalonde features to explore local geometric patterns. Additionally, a distributed multi-view attention mechanism, DEMVA, is designed to integrate the shared information across the entire dataset with the global information of each individual frame. By employing the two modules, we present our method, MUFASA, which enhances object detection performance through improved feature extraction. The approach is evaluated on the VoD and TJ4DRaDSet datasets to demonstrate its effectiveness. In particular, we achieve state-of-the-art results among radar-based methods on the VoD dataset with the mAP of 50.24%.
Read more8/2/2024