3SHNet: Boosting Image-Sentence Retrieval via Visual Semantic-Spatial Self-Highlighting

0
🏷️
Sign in to get full access
Overview
- This paper proposes a novel deep learning model called the Semantic-Spatial Self-Highlighting Network (3SHNet) for improved image-sentence retrieval.
- The key innovation is the integration of visual semantics and spatial information, which enhances the visual representation and enables efficient and generalizable cross-modal retrieval.
- The model utilizes segmentation-derived object regions and their corresponding semantic and spatial layouts to guide the retrieval process at both local and global levels.
Plain English Explanation
The researchers have developed a new deep learning system called 3SHNet that can effectively match images and text descriptions. This is an important task known as image-sentence retrieval, which has applications in areas like image search and content recommendation.
The core idea behind 3SHNet is to make better use of the visual information in the images. Typically, image-text matching models focus on the overall visual content, but 3SHNet also explicitly considers the specific objects present in the image and their spatial relationships. It does this by leveraging segmentation - a computer vision technique that identifies the different objects in an image.
By integrating this semantic and spatial information about the visual elements, 3SHNet is able to create a more detailed and informative representation of the image. This, in turn, allows the model to find stronger connections between the image and the corresponding textual description during retrieval.
Importantly, 3SHNet maintains independence between the visual and textual modalities, which helps make the system efficient and able to generalize well to new datasets. The model can also flexibly focus on either local (region-based) or global (grid-based) visual information to achieve accurate hybrid-level retrieval.
The researchers show that 3SHNet outperforms other state-of-the-art image-sentence retrieval methods on benchmark datasets, while also demonstrating strong cross-dataset generalization capabilities. This suggests the approach could be widely applicable in real-world applications.
Technical Explanation
The 3SHNet model proposed in this paper aims to enhance image-sentence retrieval by effectively integrating visual semantics and spatial information. It does this through a novel architecture that highlights the salient identification of prominent objects and their spatial layouts within the visual modality.
The key components of 3SHNet include:
-
Exploiting Object-Based Segmentation-Derived Semantic Features: The model leverages segmentation to extract object regions and their corresponding semantic and spatial layouts. This provides a detailed representation of the visual scene.
-
Contextual Encoder-Decoder Network for Visual Saliency Prediction: 3SHNet uses this saliency prediction network to identify the most prominent objects in the image, further enhancing the visual representation.
-
Modality-Independent Integration: The visual semantics and spatial information are combined with the textual representation in a modality-independent manner. This ensures efficiency and generalization across different datasets.
-
Hybrid-Level Retrieval Guidance: 3SHNet can flexibly focus on either local (region-based) or global (grid-based) visual information to achieve accurate hybrid-level retrieval.
The researchers evaluate 3SHNet on the MS-COCO and Flickr30K image-sentence retrieval benchmarks. Their results show significant improvements over state-of-the-art methods in terms of retrieval performance, efficiency, and cross-dataset generalization.
Critical Analysis
The paper provides a comprehensive technical explanation of the 3SHNet model and its key innovations. The integration of visual semantics and spatial information is a promising approach that aligns well with human cognitive processes for understanding and relating images and text.
However, the paper does not delve deeply into potential limitations or areas for further research. For example, it would be interesting to understand how 3SHNet handles more complex scenes with significant occlusion or clutter, and whether the performance gains hold true in those scenarios.
Additionally, the paper could have discussed potential computational or memory challenges associated with the use of segmentation and saliency prediction, and how those might be addressed. Exploring the model's robustness to noisy or incomplete segmentation inputs could also be a valuable direction for future work.
Overall, the 3SHNet approach is a solid contribution to the field of image-sentence retrieval, and the promising results suggest it could be a useful tool for various real-world applications. However, a more in-depth critical analysis of the method's limitations and potential future improvements would further strengthen the paper's impact.
Conclusion
The Semantic-Spatial Self-Highlighting Network (3SHNet) proposed in this paper represents a novel and effective approach to the challenge of image-sentence retrieval. By integrating visual semantics and spatial information, the model is able to create a more detailed and informative representation of the image content, leading to significant performance improvements on benchmark datasets.
The key innovations of 3SHNet, such as the leveraging of segmentation-derived features and the modality-independent integration, demonstrate the value of incorporating deeper visual understanding into cross-modal retrieval tasks. The model's ability to flexibly focus on local or global visual information is also a noteworthy capability.
Overall, the 3SHNet system showcases the potential for advanced computer vision and language techniques to enhance the way we interact with and navigate visual-textual content. As the field of image-sentence retrieval continues to evolve, approaches like 3SHNet could play an increasingly important role in powering more intuitive and effective multimedia search and recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
3SHNet: Boosting Image-Sentence Retrieval via Visual Semantic-Spatial Self-Highlighting
Xuri Ge, Songpei Xu, Fuhai Chen, Jie Wang, Guoxin Wang, Shan An, Joemon M. Jose
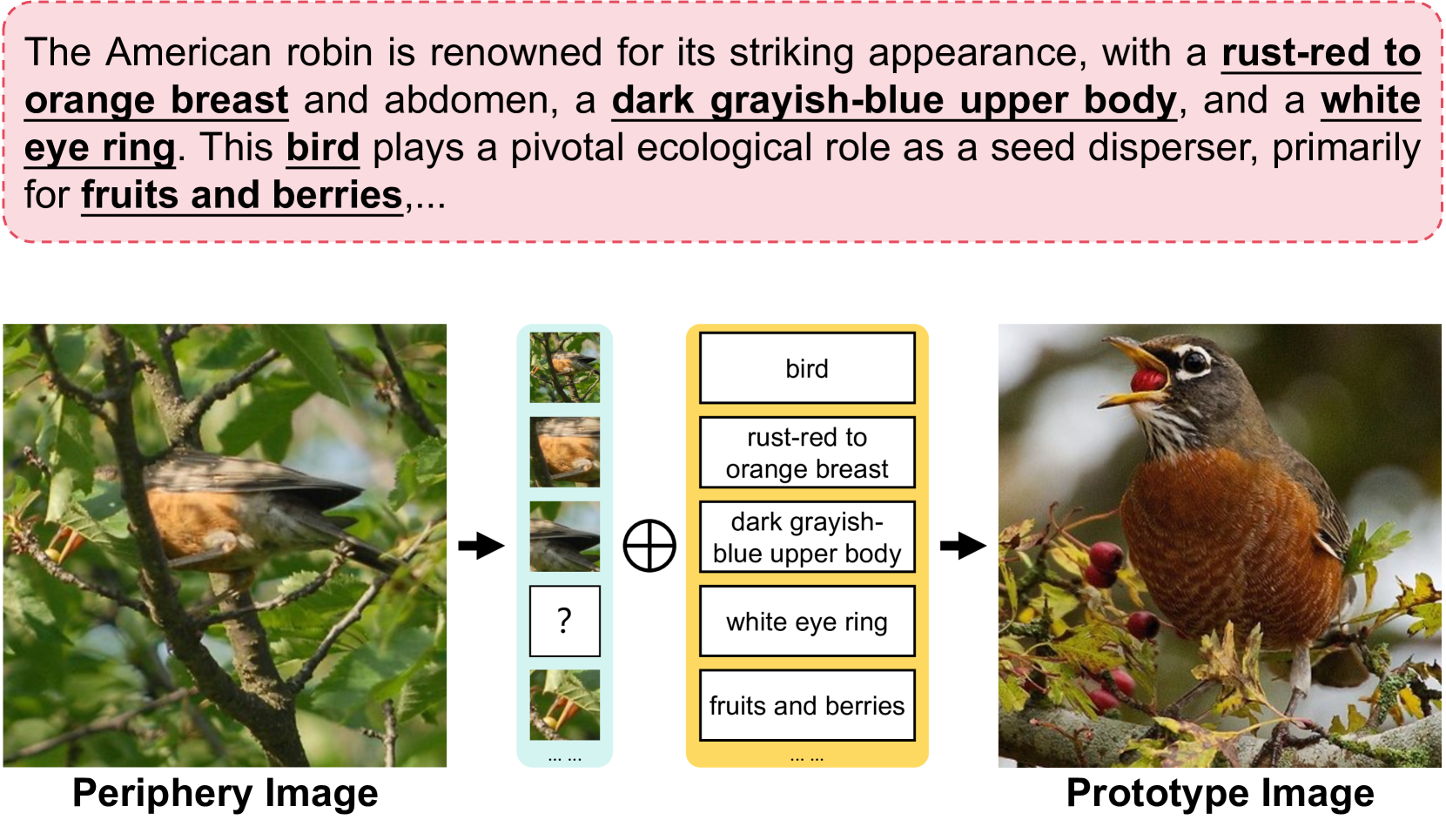
In this paper, we propose a novel visual Semantic-Spatial Self-Highlighting Network (termed 3SHNet) for high-precision, high-efficiency and high-generalization image-sentence retrieval. 3SHNet highlights the salient identification of prominent objects and their spatial locations within the visual modality, thus allowing the integration of visual semantics-spatial interactions and maintaining independence between two modalities. This integration effectively combines object regions with the corresponding semantic and position layouts derived from segmentation to enhance the visual representation. And the modality-independence guarantees efficiency and generalization. Additionally, 3SHNet utilizes the structured contextual visual scene information from segmentation to conduct the local (region-based) or global (grid-based) guidance and achieve accurate hybrid-level retrieval. Extensive experiments conducted on MS-COCO and Flickr30K benchmarks substantiate the superior performances, inference efficiency and generalization of the proposed 3SHNet when juxtaposed with contemporary state-of-the-art methodologies. Specifically, on the larger MS-COCO 5K test set, we achieve 16.3%, 24.8%, and 18.3% improvements in terms of rSum score, respectively, compared with the state-of-the-art methods using different image representations, while maintaining optimal retrieval efficiency. Moreover, our performance on cross-dataset generalization improves by 18.6%. Data and code are available at https://github.com/XuriGe1995/3SHNet.
Read more4/29/2024

0
Learning Spatial-Semantic Features for Robust Video Object Segmentation
Xin Li, Deshui Miao, Zhenyu He, Yaowei Wang, Huchuan Lu, Ming-Hsuan Yang
Tracking and segmenting multiple similar objects with complex or separate parts in long-term videos is inherently challenging due to the ambiguity of target parts and identity confusion caused by occlusion, background clutter, and long-term variations. In this paper, we propose a robust video object segmentation framework equipped with spatial-semantic features and discriminative object queries to address the above issues. Specifically, we construct a spatial-semantic network comprising a semantic embedding block and spatial dependencies modeling block to associate the pretrained ViT features with global semantic features and local spatial features, providing a comprehensive target representation. In addition, we develop a masked cross-attention module to generate object queries that focus on the most discriminative parts of target objects during query propagation, alleviating noise accumulation and ensuring effective long-term query propagation. The experimental results show that the proposed method set a new state-of-the-art performance on multiple datasets, including the DAVIS2017 test (89.1%), YoutubeVOS 2019 (88.5%), MOSE (75.1%), LVOS test (73.0%), and LVOS val (75.1%), which demonstrate the effectiveness and generalization capacity of the proposed method. We will make all source code and trained models publicly available.
Read more7/11/2024
👁️
0
Semantic-guided modeling of spatial relation and object co-occurrence for indoor scene recognition
Chuanxin Song, Hanbo Wu, Xin Ma
Exploring the semantic context in scene images is essential for indoor scene recognition. However, due to the diverse intra-class spatial layouts and the coexisting inter-class objects, modeling contextual relationships to adapt various image characteristics is a great challenge. Existing contextual modeling methods for scene recognition exhibit two limitations: 1) They typically model only one type of spatial relationship (order or metric) among objects within scenes, with limited exploration of diverse spatial layouts. 2) They often overlook the differences in coexisting objects across different scenes, suppressing scene recognition performance. To overcome these limitations, we propose SpaCoNet, which simultaneously models Spatial relation and Co-occurrence of objects guided by semantic segmentation. Firstly, the Semantic Spatial Relation Module (SSRM) is constructed to model scene spatial features. With the help of semantic segmentation, this module decouples spatial information from the scene image and thoroughly explores all spatial relationships among objects in an end-to-end manner, thereby obtaining semantic-based spatial features. Secondly, both spatial features from the SSRM and deep features from the Image Feature Extraction Module are allocated to each object, so as to distinguish the coexisting object across different scenes. Finally, utilizing the discriminative features above, we design a Global-Local Dependency Module to explore the long-range co-occurrence among objects, and further generate a semantic-guided feature representation for indoor scene recognition. Experimental results on three widely used scene datasets demonstrate the effectiveness and generality of the proposed method.
Read more8/9/2024
0
Simple Semantic-Aided Few-Shot Learning
Hai Zhang, Junzhe Xu, Shanlin Jiang, Zhenan He
Learning from a limited amount of data, namely Few-Shot Learning, stands out as a challenging computer vision task. Several works exploit semantics and design complicated semantic fusion mechanisms to compensate for rare representative features within restricted data. However, relying on naive semantics such as class names introduces biases due to their brevity, while acquiring extensive semantics from external knowledge takes a huge time and effort. This limitation severely constrains the potential of semantics in Few-Shot Learning. In this paper, we design an automatic way called Semantic Evolution to generate high-quality semantics. The incorporation of high-quality semantics alleviates the need for complex network structures and learning algorithms used in previous works. Hence, we employ a simple two-layer network termed Semantic Alignment Network to transform semantics and visual features into robust class prototypes with rich discriminative features for few-shot classification. The experimental results show our framework outperforms all previous methods on six benchmarks, demonstrating a simple network with high-quality semantics can beat intricate multi-modal modules on few-shot classification tasks. Code is available at https://github.com/zhangdoudou123/SemFew.
Read more4/10/2024