500xCompressor: Generalized Prompt Compression for Large Language Models

0

Sign in to get full access
Overview
- Introduces a novel prompt compression technique called "500xCompressor" that can significantly reduce the size of prompts for large language models
- Demonstrates that prompt compression can be achieved without sacrificing model performance on a variety of tasks
- Proposes a generalized framework for prompt compression that can be applied to different language models and applications
Plain English Explanation
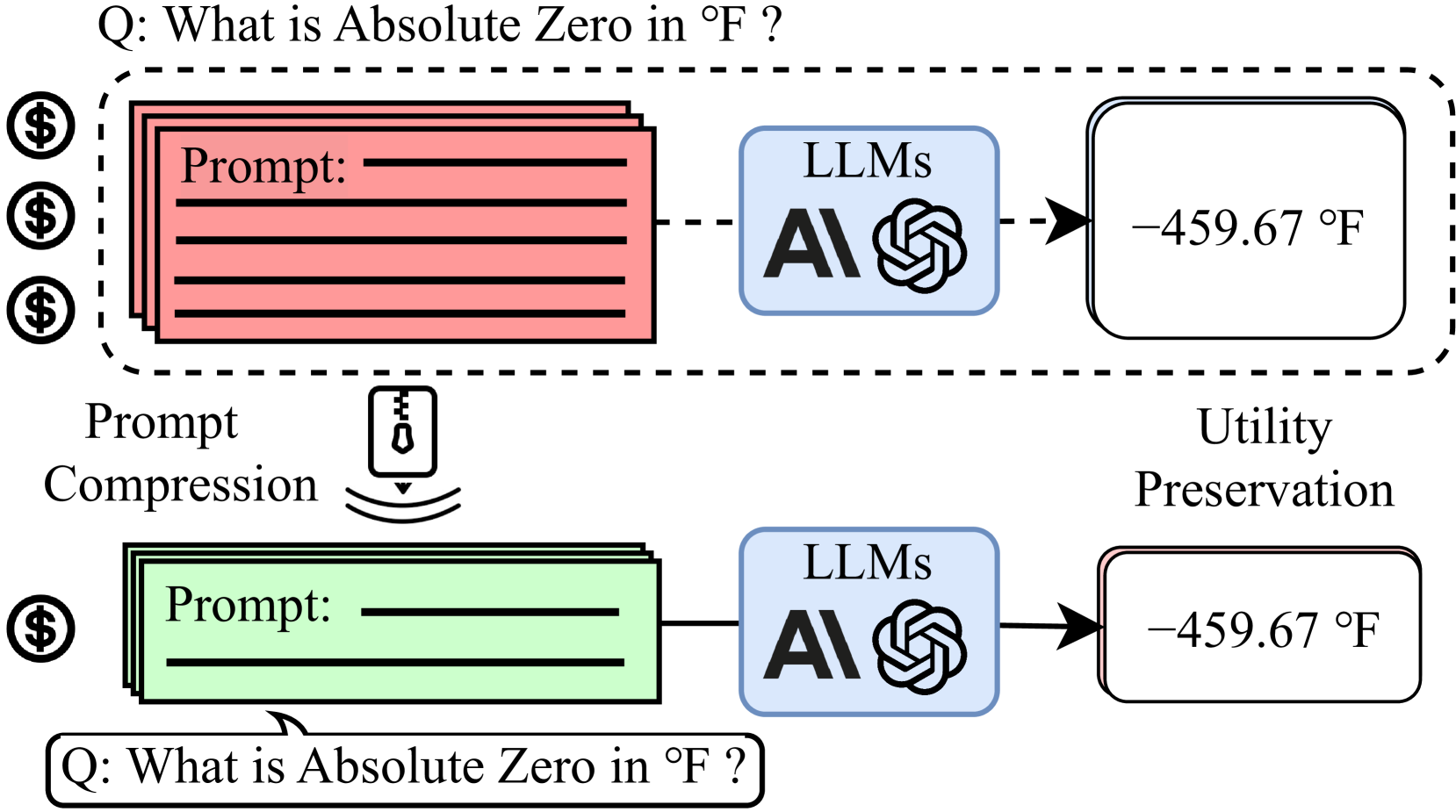
The paper presents a new method called "500xCompressor" that can dramatically reduce the size of prompts used to instruct large language models, such as GPT-3 or BERT, without compromising their performance. Prompts are the text that users provide to guide the language model in generating its output. However, these prompts can become very long, which can slow down the model's response time and limit its use in certain applications.
The 500xCompressor technique works by identifying the most important parts of a prompt and compressing them into a much smaller form. This compressed prompt can then be fed into the language model, which can still generate the desired output. The researchers show that this compression can be achieved with negligible impact on the model's accuracy across a variety of tasks, including text generation, question answering, and sentiment analysis.
This approach provides a generalized framework that can be applied to different language models and use cases. By dramatically reducing the size of prompts, 500xCompressor could enable new applications for large language models, such as running them on resource-constrained devices or using them in low-bandwidth communication scenarios.
Technical Explanation
The 500xCompressor technique works by first encoding the input prompt into a fixed-size vector representation using a pre-trained encoder model. This encoded vector is then passed through a series of learned compression layers that gradually reduce its dimensionality while preserving the most important information.
The compressed vector is then decoded back into a shortened prompt that can be fed into the target language model. The researchers use a multi-task training approach, where the compression model is jointly optimized to preserve the language model's performance on various downstream tasks.
Experiments show that 500xCompressor can achieve compression ratios of up to 500x, reducing prompts from thousands of tokens to just a few, without significantly impacting the language model's accuracy. The researchers also demonstrate that this approach generalizes well to different language models and tasks, making it a versatile tool for prompt compression.
Critical Analysis
The 500xCompressor approach is a promising step towards enabling more efficient use of large language models. By reducing prompt sizes, it could unlock new applications for these powerful models, such as running them on edge devices or in low-bandwidth settings.
However, the paper does not address the potential security and privacy implications of this technique. Compressing prompts could make it easier for adversaries to extract sensitive information or construct prompts that exploit language model vulnerabilities. The authors should discuss these risks and potential mitigation strategies.
Additionally, the paper focuses on compression ratios and task performance, but does not provide a detailed analysis of the runtime or memory efficiency of the 500xCompressor model itself. Further research is needed to understand the practical deployment implications of this approach.
Conclusion
The 500xCompressor technique represents a significant advance in prompt compression for large language models. By drastically reducing prompt sizes without sacrificing performance, it could enable a wide range of new applications for these powerful AI systems. As the use of language models continues to grow, techniques like 500xCompressor will become increasingly important for ensuring their efficient and responsible deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
500xCompressor: Generalized Prompt Compression for Large Language Models
Zongqian Li, Yixuan Su, Nigel Collier
Prompt compression is crucial for enhancing inference speed, reducing costs, and improving user experience. However, current methods face challenges such as low compression ratios and potential data leakage during evaluation. To address these issues, we propose 500xCompressor, a method that compresses extensive natural language contexts into a minimum of one single special token. The 500xCompressor introduces approximately 0.3% additional parameters and achieves compression ratios ranging from 6x to 480x. It is designed to compress any text, answer various types of questions, and could be utilized by the original large language model (LLM) without requiring fine-tuning. Initially, 500xCompressor was pretrained on the Arxiv Corpus, followed by fine-tuning on the ArxivQA dataset, and subsequently evaluated on strictly unseen and classical question answering (QA) datasets. The results demonstrate that the LLM retained 62.26-72.89% of its capabilities compared to using non-compressed prompts. This study also shows that not all the compressed tokens are equally utilized and that K V values have significant advantages over embeddings in preserving information at high compression ratios. The highly compressive nature of natural language prompts, even for fine-grained complex information, suggests promising potential for future applications and further research into developing a new LLM language.
Read more8/7/2024
0
Learning to Compress Prompt in Natural Language Formats
Yu-Neng Chuang, Tianwei Xing, Chia-Yuan Chang, Zirui Liu, Xun Chen, Xia Hu
Large language models (LLMs) are great at processing multiple natural language processing tasks, but their abilities are constrained by inferior performance with long context, slow inference speed, and the high cost of computing the results. Deploying LLMs with precise and informative context helps users process large-scale datasets more effectively and cost-efficiently. Existing works rely on compressing long prompt contexts into soft prompts. However, soft prompt compression encounters limitations in transferability across different LLMs, especially API-based LLMs. To this end, this work aims to compress lengthy prompts in the form of natural language with LLM transferability. This poses two challenges: (i) Natural Language (NL) prompts are incompatible with back-propagation, and (ii) NL prompts lack flexibility in imposing length constraints. In this work, we propose a Natural Language Prompt Encapsulation (Nano-Capsulator) framework compressing original prompts into NL formatted Capsule Prompt while maintaining the prompt utility and transferability. Specifically, to tackle the first challenge, the Nano-Capsulator is optimized by a reward function that interacts with the proposed semantics preserving loss. To address the second question, the Nano-Capsulator is optimized by a reward function featuring length constraints. Experimental results demonstrate that the Capsule Prompt can reduce 81.4% of the original length, decrease inference latency up to 4.5x, and save 80.1% of budget overheads while providing transferability across diverse LLMs and different datasets.
Read more4/3/2024

0
Prompt Compression with Context-Aware Sentence Encoding for Fast and Improved LLM Inference
Barys Liskavets, Maxim Ushakov, Shuvendu Roy, Mark Klibanov, Ali Etemad, Shane Luke
Large language models (LLMs) have triggered a new stream of research focusing on compressing the context length to reduce the computational cost while ensuring the retention of helpful information for LLMs to answer the given question. Token-based removal methods are one of the most prominent approaches in this direction, but risk losing the semantics of the context caused by intermediate token removal, especially under high compression ratios, while also facing challenges in computational efficiency. In this work, we propose context-aware prompt compression (CPC), a sentence-level prompt compression technique where its key innovation is a novel context-aware sentence encoder that provides a relevance score for each sentence for a given question. To train this encoder, we generate a new dataset consisting of questions, positives, and negative pairs where positives are sentences relevant to the question, while negatives are irrelevant context sentences. We train the encoder in a contrastive setup to learn context-aware sentence representations. Our method considerably outperforms prior works on prompt compression on benchmark datasets and is up to 10.93x faster at inference compared to the best token-level compression method. We also find better improvement for shorter length constraints in most benchmarks, showing the effectiveness of our proposed solution in the compression of relevant information in a shorter context. Finally, we release the code and the dataset for quick reproducibility and further development: https://github.com/Workday/cpc.
Read more9/5/2024

0
LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Ruhle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, Dongmei Zhang
This paper focuses on task-agnostic prompt compression for better generalizability and efficiency. Considering the redundancy in natural language, existing approaches compress prompts by removing tokens or lexical units according to their information entropy obtained from a causal language model such as LLaMa-7B. The challenge is that information entropy may be a suboptimal compression metric: (i) it only leverages unidirectional context and may fail to capture all essential information needed for prompt compression; (ii) it is not aligned with the prompt compression objective. To address these issues, we propose a data distillation procedure to derive knowledge from an LLM to compress prompts without losing crucial information, and meantime, introduce an extractive text compression dataset. We formulate prompt compression as a token classification problem to guarantee the faithfulness of the compressed prompt to the original one, and use a Transformer encoder as the base architecture to capture all essential information for prompt compression from the full bidirectional context. Our approach leads to lower latency by explicitly learning the compression objective with smaller models such as XLM-RoBERTa-large and mBERT. We evaluate our method on both in-domain and out-of-domain datasets, including MeetingBank, LongBench, ZeroScrolls, GSM8K, and BBH. Despite its small size, our model shows significant performance gains over strong baselines and demonstrates robust generalization ability across different LLMs. Additionally, our model is 3x-6x faster than existing prompt compression methods, while accelerating the end-to-end latency by 1.6x-2.9x with compression ratios of 2x-5x. Our code is available at https://aka.ms/LLMLingua-2.
Read more8/13/2024