6DGS: 6D Pose Estimation from a Single Image and a 3D Gaussian Splatting Model

0

Sign in to get full access
Overview
- The paper proposes a novel 6D pose estimation method called 6DGS, which uses a single image and a 3D Gaussian splatting model.
- It introduces a 3D Gaussian splatting-based representation to effectively capture 3D object geometry and appearance information.
- The method demonstrates state-of-the-art performance on several 6D pose estimation benchmarks.
Plain English Explanation
The paper presents a new way to estimate the 6D pose (position and orientation) of an object from a single image. The key idea is to use a 3D Gaussian splatting model, which can effectively capture the 3D shape and appearance of the object. This is done by representing the object as a collection of 3D "blobs" or Gaussian distributions, rather than just a set of 2D image pixels.
By using this 3D Gaussian representation, the method is able to more accurately estimate the object's 6D pose, even from a single image. This is important for tasks like augmented reality, robotic manipulation, and self-driving cars, where knowing the precise 3D position and orientation of objects is critical.
The paper shows that this 6DGS method outperforms other state-of-the-art 6D pose estimation techniques on several standard benchmarks. This suggests that the 3D Gaussian splatting approach is a promising new direction for this problem.
Technical Explanation
The 6DGS method works by first encoding the 3D object geometry and appearance into a compact 3D Gaussian splatting representation. This is done by fitting a set of 3D Gaussian distributions to the object's 3D shape and texture information, which can be obtained from a 3D model or other sources.
During inference, the method takes a single 2D image of the object and predicts the 6D pose (3D position and 3D orientation) by aligning the 3D Gaussian splatting model to the image features. This is accomplished through an iterative optimization process that minimizes the differences between the projected 3D Gaussian splatting model and the observed 2D image features.
The key innovation of 6DGS is this 3D Gaussian splatting representation, which allows the method to effectively capture the rich 3D structure of the object. This is in contrast to many previous 6D pose estimation approaches that rely on 2D image features or basic 3D shape primitives, which can struggle to represent complex 3D geometry.
Critical Analysis
The paper provides a thorough evaluation of the 6DGS method on several challenging 6D pose estimation benchmarks, demonstrating state-of-the-art performance. This suggests the 3D Gaussian splatting representation is a powerful tool for this task.
However, the paper does not address some potential limitations of the approach. For example, the method may struggle with highly occluded or partially visible objects, as the 3D Gaussian splatting model requires a relatively complete view of the object's geometry. Additionally, the iterative optimization process used for pose estimation may be computationally expensive, limiting the method's real-time applicability.
Further research could explore ways to make the 3D Gaussian splatting representation more robust to occlusions and partial views, as well as investigate more efficient pose estimation algorithms. Incorporating additional cues, such as semantic segmentation or instance-level information, may also help improve the method's performance.
Conclusion
The 6DGS method presented in this paper offers a novel way to estimate the 6D pose of objects from a single image, using a 3D Gaussian splatting representation to effectively capture the 3D structure of the target. The strong experimental results suggest this approach is a promising direction for 6D pose estimation, with potential applications in areas such as robotics, augmented reality, and autonomous driving.
While the paper demonstrates the method's capabilities, further research is needed to address some of its potential limitations and broaden its practical applicability. Nonetheless, the 6DGS technique represents an important advancement in the field of 3D object pose estimation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
6DGS: 6D Pose Estimation from a Single Image and a 3D Gaussian Splatting Model
Matteo Bortolon, Theodore Tsesmelis, Stuart James, Fabio Poiesi, Alessio Del Bue
We propose 6DGS to estimate the camera pose of a target RGB image given a 3D Gaussian Splatting (3DGS) model representing the scene. 6DGS avoids the iterative process typical of analysis-by-synthesis methods (e.g. iNeRF) that also require an initialization of the camera pose in order to converge. Instead, our method estimates a 6DoF pose by inverting the 3DGS rendering process. Starting from the object surface, we define a radiant Ellicell that uniformly generates rays departing from each ellipsoid that parameterize the 3DGS model. Each Ellicell ray is associated with the rendering parameters of each ellipsoid, which in turn is used to obtain the best bindings between the target image pixels and the cast rays. These pixel-ray bindings are then ranked to select the best scoring bundle of rays, which their intersection provides the camera center and, in turn, the camera rotation. The proposed solution obviates the necessity of an a priori pose for initialization, and it solves 6DoF pose estimation in closed form, without the need for iterations. Moreover, compared to the existing Novel View Synthesis (NVS) baselines for pose estimation, 6DGS can improve the overall average rotational accuracy by 12% and translation accuracy by 22% on real scenes, despite not requiring any initialization pose. At the same time, our method operates near real-time, reaching 15fps on consumer hardware.
Read more7/23/2024
0
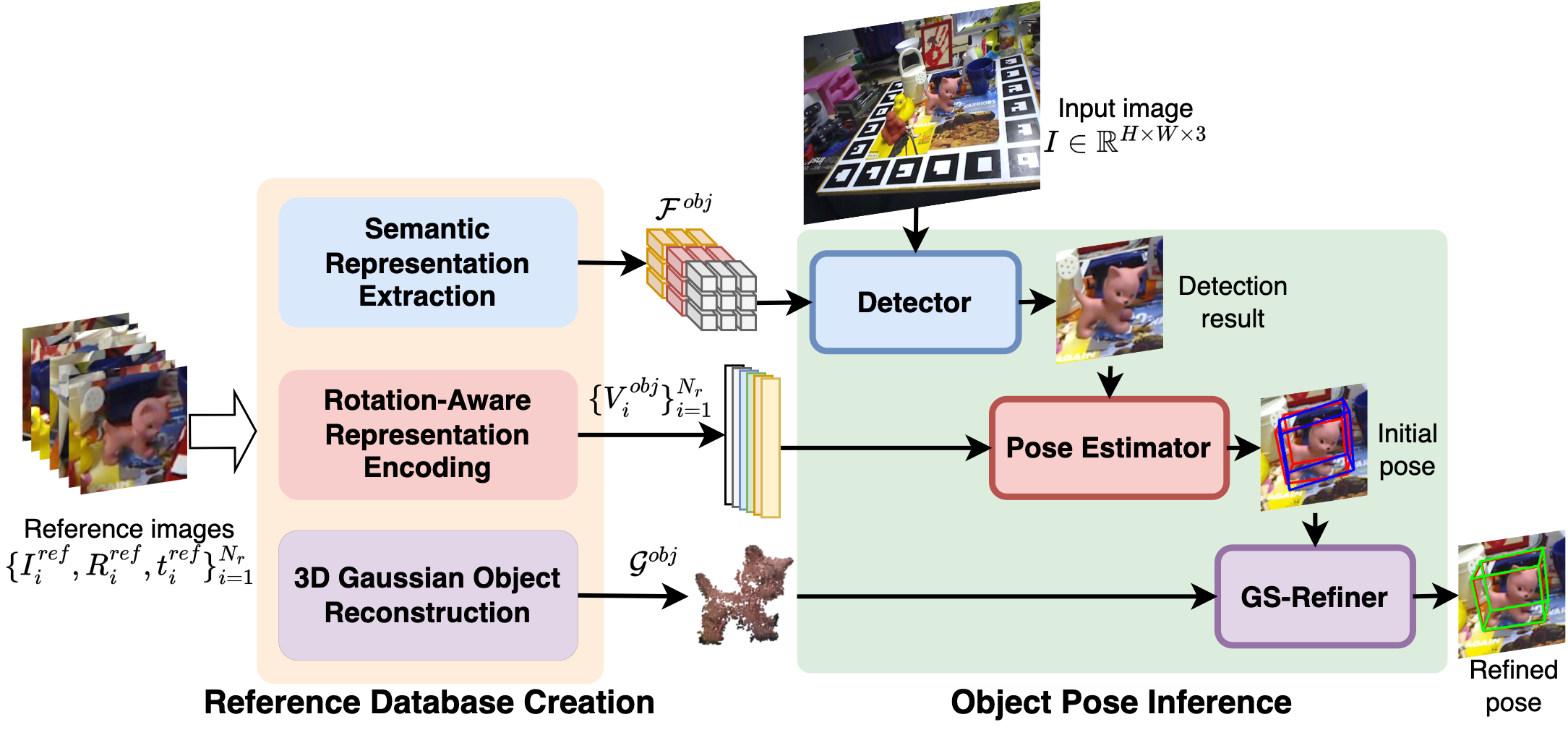
GS-Pose: Generalizable Segmentation-based 6D Object Pose Estimation with 3D Gaussian Splatting
Dingding Cai, Janne Heikkila, Esa Rahtu
This paper introduces GS-Pose, a unified framework for localizing and estimating the 6D pose of novel objects. GS-Pose begins with a set of posed RGB images of a previously unseen object and builds three distinct representations stored in a database. At inference, GS-Pose operates sequentially by locating the object in the input image, estimating its initial 6D pose using a retrieval approach, and refining the pose with a render-and-compare method. The key insight is the application of the appropriate object representation at each stage of the process. In particular, for the refinement step, we leverage 3D Gaussian splatting, a novel differentiable rendering technique that offers high rendering speed and relatively low optimization time. Off-the-shelf toolchains and commodity hardware, such as mobile phones, can be used to capture new objects to be added to the database. Extensive evaluations on the LINEMOD and OnePose-LowTexture datasets demonstrate excellent performance, establishing the new state-of-the-art. Project page: https://dingdingcai.github.io/gs-pose.
Read more8/15/2024

0
GSLoc: Efficient Camera Pose Refinement via 3D Gaussian Splatting
Changkun Liu, Shuai Chen, Yash Bhalgat, Siyan Hu, Zirui Wang, Ming Cheng, Victor Adrian Prisacariu, Tristan Braud
We leverage 3D Gaussian Splatting (3DGS) as a scene representation and propose a novel test-time camera pose refinement framework, GSLoc. This framework enhances the localization accuracy of state-of-the-art absolute pose regression and scene coordinate regression methods. The 3DGS model renders high-quality synthetic images and depth maps to facilitate the establishment of 2D-3D correspondences. GSLoc obviates the need for training feature extractors or descriptors by operating directly on RGB images, utilizing the 3D vision foundation model, MASt3R, for precise 2D matching. To improve the robustness of our model in challenging outdoor environments, we incorporate an exposure-adaptive module within the 3DGS framework. Consequently, GSLoc enables efficient pose refinement given a single RGB query and a coarse initial pose estimation. Our proposed approach surpasses leading NeRF-based optimization methods in both accuracy and runtime across indoor and outdoor visual localization benchmarks, achieving state-of-the-art accuracy on two indoor datasets.
Read more8/22/2024

0
Object Gaussian for Monocular 6D Pose Estimation from Sparse Views
Luqing Luo, Shichu Sun, Jiangang Yang, Linfang Zheng, Jinwei Du, Jian Liu
Monocular object pose estimation, as a pivotal task in computer vision and robotics, heavily depends on accurate 2D-3D correspondences, which often demand costly CAD models that may not be readily available. Object 3D reconstruction methods offer an alternative, among which recent advancements in 3D Gaussian Splatting (3DGS) afford a compelling potential. Yet its performance still suffers and tends to overfit with fewer input views. Embracing this challenge, we introduce SGPose, a novel framework for sparse view object pose estimation using Gaussian-based methods. Given as few as ten views, SGPose generates a geometric-aware representation by starting with a random cuboid initialization, eschewing reliance on Structure-from-Motion (SfM) pipeline-derived geometry as required by traditional 3DGS methods. SGPose removes the dependence on CAD models by regressing dense 2D-3D correspondences between images and the reconstructed model from sparse input and random initialization, while the geometric-consistent depth supervision and online synthetic view warping are key to the success. Experiments on typical benchmarks, especially on the Occlusion LM-O dataset, demonstrate that SGPose outperforms existing methods even under sparse view constraints, under-scoring its potential in real-world applications.
Read more9/5/2024