Object Gaussian for Monocular 6D Pose Estimation from Sparse Views

0

Sign in to get full access
Overview
- This paper proposes a novel object Gaussian representation for 6D pose estimation from monocular sparse views.
- The approach uses a Gaussian mixture model to capture the distribution of object keypoints, which allows for probabilistic pose estimation.
- Experiments show the method outperforms state-of-the-art techniques on challenging benchmarks.
Plain English Explanation
The paper introduces a new way to estimate the 6D (3D position and 3D orientation) pose of an object from a single camera view, even when only sparse observations of the object are available.
The key idea is to model the 3D locations of important points on the object's surface using a Gaussian mixture model. This statistical representation captures the uncertainty in where those points might be located, rather than just giving a single predicted position for each point.
By using this probabilistic Gaussian model, the system can reason about the full 6D pose of the object in a more robust way, even when only limited visual information is available from a single camera angle. The authors show that this approach outperforms other state-of-the-art methods for 6D object pose estimation, particularly in challenging scenarios with few observations of the object.
Technical Explanation
The paper proposes an "object Gaussian" representation to address the problem of 6D object pose estimation from monocular sparse views.
The core technical approach is to model the 3D locations of a set of keypoints on the surface of the object using a Gaussian mixture model (GMM). This GMM captures the uncertainty in the 3D position of each keypoint, rather than just predicting a single point location.
The authors then develop a neural network architecture that takes in a single RGB image and predicts the parameters of this object Gaussian representation. This allows the system to reason about the full 6D pose of the object (3D position and 3D orientation) in a probabilistic way, leveraging the uncertainty modeled by the Gaussian mixture.
Experiments on standard 6D pose estimation benchmarks show that this object Gaussian approach outperforms a range of state-of-the-art techniques, particularly in scenarios with sparse observations of the object from a single camera view.
Critical Analysis
The paper makes a compelling case for the object Gaussian representation as a powerful tool for 6D pose estimation from limited visual data. The probabilistic modeling of keypoint locations seems well-suited to handle the inherent uncertainty present in sparse views.
However, the paper does not extensively explore the limitations of the approach. For example, it is unclear how the method would scale to highly occluded or heavily cluttered scenes, where the assumptions of sparse but reliable keypoint observations may not hold.
Additionally, the computational and memory requirements of the Gaussian mixture model representation are not discussed in detail. Deploying such a probabilistic approach on resource-constrained platforms could be challenging.
Further research could investigate ways to make the object Gaussian representation more efficient, as well as explore its robustness to more extreme conditions beyond the evaluated benchmarks.
Conclusion
This paper presents a novel object Gaussian representation that enables robust 6D pose estimation from monocular sparse views. By modeling the 3D locations of object keypoints using a probabilistic Gaussian mixture, the approach can reason about the full 6D pose in a more principled way compared to prior techniques.
The experimental results demonstrate the effectiveness of this approach, particularly in challenging scenarios with limited visual observations. While some potential limitations remain to be explored, the object Gaussian concept represents an interesting and promising direction for advancing the state of the art in 6D object pose estimation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Object Gaussian for Monocular 6D Pose Estimation from Sparse Views
Luqing Luo, Shichu Sun, Jiangang Yang, Linfang Zheng, Jinwei Du, Jian Liu
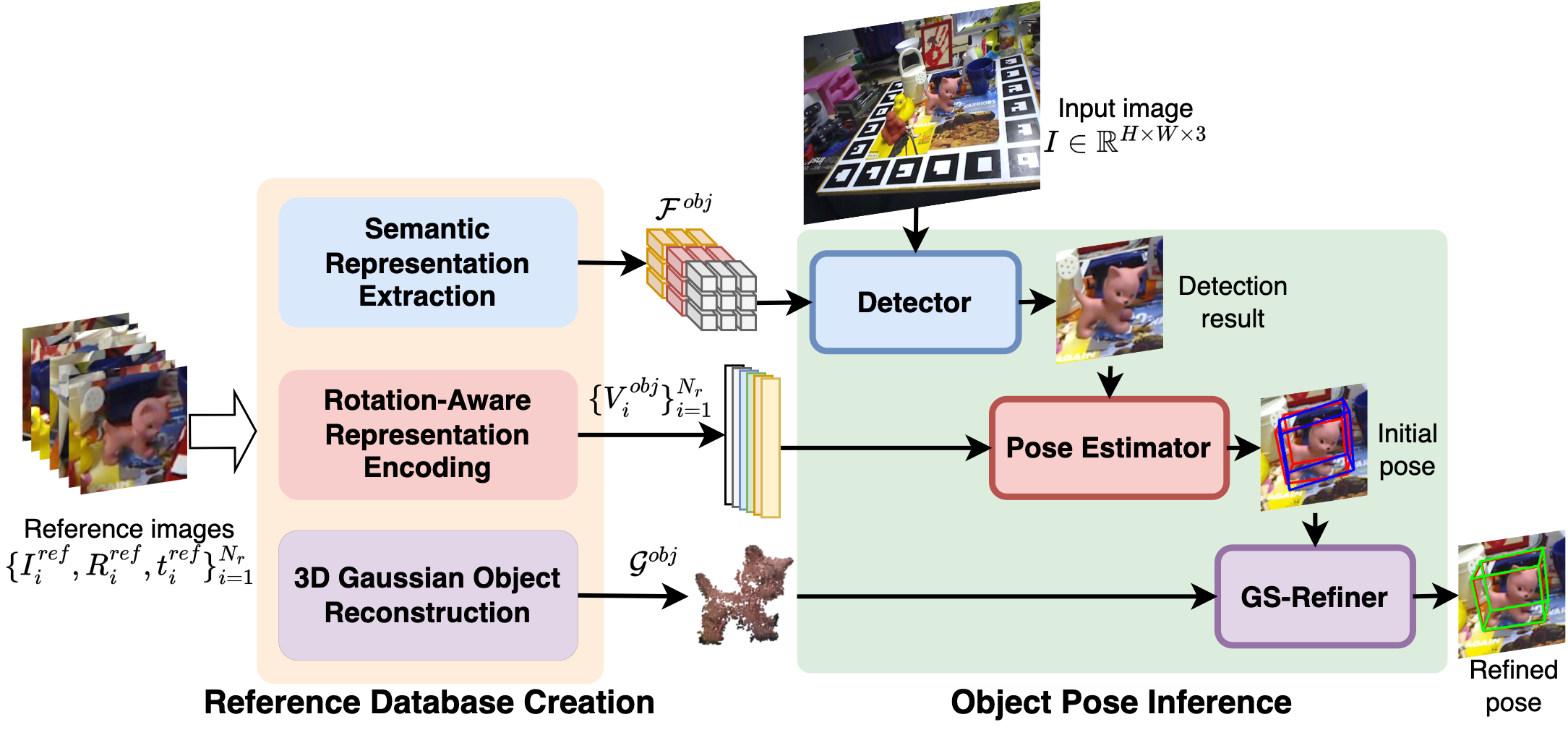
Monocular object pose estimation, as a pivotal task in computer vision and robotics, heavily depends on accurate 2D-3D correspondences, which often demand costly CAD models that may not be readily available. Object 3D reconstruction methods offer an alternative, among which recent advancements in 3D Gaussian Splatting (3DGS) afford a compelling potential. Yet its performance still suffers and tends to overfit with fewer input views. Embracing this challenge, we introduce SGPose, a novel framework for sparse view object pose estimation using Gaussian-based methods. Given as few as ten views, SGPose generates a geometric-aware representation by starting with a random cuboid initialization, eschewing reliance on Structure-from-Motion (SfM) pipeline-derived geometry as required by traditional 3DGS methods. SGPose removes the dependence on CAD models by regressing dense 2D-3D correspondences between images and the reconstructed model from sparse input and random initialization, while the geometric-consistent depth supervision and online synthetic view warping are key to the success. Experiments on typical benchmarks, especially on the Occlusion LM-O dataset, demonstrate that SGPose outperforms existing methods even under sparse view constraints, under-scoring its potential in real-world applications.
Read more9/5/2024
🏋️
0
A Construct-Optimize Approach to Sparse View Synthesis without Camera Pose
Kaiwen Jiang, Yang Fu, Mukund Varma T, Yash Belhe, Xiaolong Wang, Hao Su, Ravi Ramamoorthi
Novel view synthesis from a sparse set of input images is a challenging problem of great practical interest, especially when camera poses are absent or inaccurate. Direct optimization of camera poses and usage of estimated depths in neural radiance field algorithms usually do not produce good results because of the coupling between poses and depths, and inaccuracies in monocular depth estimation. In this paper, we leverage the recent 3D Gaussian splatting method to develop a novel construct-and-optimize method for sparse view synthesis without camera poses. Specifically, we construct a solution progressively by using monocular depth and projecting pixels back into the 3D world. During construction, we optimize the solution by detecting 2D correspondences between training views and the corresponding rendered images. We develop a unified differentiable pipeline for camera registration and adjustment of both camera poses and depths, followed by back-projection. We also introduce a novel notion of an expected surface in Gaussian splatting, which is critical to our optimization. These steps enable a coarse solution, which can then be low-pass filtered and refined using standard optimization methods. We demonstrate results on the Tanks and Temples and Static Hikes datasets with as few as three widely-spaced views, showing significantly better quality than competing methods, including those with approximate camera pose information. Moreover, our results improve with more views and outperform previous InstantNGP and Gaussian Splatting algorithms even when using half the dataset. Project page: https://raymondjiangkw.github.io/cogs.github.io/
Read more6/12/2024
0
GS-Pose: Generalizable Segmentation-based 6D Object Pose Estimation with 3D Gaussian Splatting
Dingding Cai, Janne Heikkila, Esa Rahtu
This paper introduces GS-Pose, a unified framework for localizing and estimating the 6D pose of novel objects. GS-Pose begins with a set of posed RGB images of a previously unseen object and builds three distinct representations stored in a database. At inference, GS-Pose operates sequentially by locating the object in the input image, estimating its initial 6D pose using a retrieval approach, and refining the pose with a render-and-compare method. The key insight is the application of the appropriate object representation at each stage of the process. In particular, for the refinement step, we leverage 3D Gaussian splatting, a novel differentiable rendering technique that offers high rendering speed and relatively low optimization time. Off-the-shelf toolchains and commodity hardware, such as mobile phones, can be used to capture new objects to be added to the database. Extensive evaluations on the LINEMOD and OnePose-LowTexture datasets demonstrate excellent performance, establishing the new state-of-the-art. Project page: https://dingdingcai.github.io/gs-pose.
Read more8/15/2024

0
Optimizing 3D Gaussian Splatting for Sparse Viewpoint Scene Reconstruction
Shen Chen, Jiale Zhou, Lei Li
3D Gaussian Splatting (3DGS) has emerged as a promising approach for 3D scene representation, offering a reduction in computational overhead compared to Neural Radiance Fields (NeRF). However, 3DGS is susceptible to high-frequency artifacts and demonstrates suboptimal performance under sparse viewpoint conditions, thereby limiting its applicability in robotics and computer vision. To address these limitations, we introduce SVS-GS, a novel framework for Sparse Viewpoint Scene reconstruction that integrates a 3D Gaussian smoothing filter to suppress artifacts. Furthermore, our approach incorporates a Depth Gradient Profile Prior (DGPP) loss with a dynamic depth mask to sharpen edges and 2D diffusion with Score Distillation Sampling (SDS) loss to enhance geometric consistency in novel view synthesis. Experimental evaluations on the MipNeRF-360 and SeaThru-NeRF datasets demonstrate that SVS-GS markedly improves 3D reconstruction from sparse viewpoints, offering a robust and efficient solution for scene understanding in robotics and computer vision applications.
Read more9/6/2024