A3S: A General Active Clustering Method with Pairwise Constraints

0
Sign in to get full access
Overview
• This paper introduces A3S, a general active clustering method that incorporates pairwise constraints to improve clustering performance. • Active clustering aims to optimize the clustering process by strategically selecting data points to label, rather than labeling all data points. • Pairwise constraints refer to must-link (two points belong to the same cluster) and cannot-link (two points belong to different clusters) constraints provided by a human expert. • A3S leverages these pairwise constraints to guide the active selection of data points, leading to more efficient and accurate clustering.
Plain English Explanation
A general active clustering method with pairwise constraints is a new technique that can help improve the clustering of data points into groups. Clustering is the process of grouping similar data points together, and it's a common task in machine learning.
The key idea behind this new method, called A3S, is to selectively choose which data points to label, rather than labeling all of them. This selective labeling, known as active clustering, can lead to more efficient and accurate clustering results.
A3S also incorporates additional information in the form of pairwise constraints, which are provided by a human expert. These constraints specify which data points should be in the same group (must-link) and which should be in different groups (cannot-link). By using these pairwise constraints, A3S can further guide the active selection of data points to label, resulting in even better clustering performance.
The researchers demonstrate the effectiveness of A3S through experiments on various datasets, showing that it outperforms other active clustering methods, especially when pairwise constraints are available.
Technical Explanation
A3S: A General Active Clustering Method with Pairwise Constraints presents a novel active clustering framework that leverages pairwise constraints to guide the selection of data points to label.
The key components of the A3S method are:
- Clustering Model: A3S can work with any base clustering model, such as K-means or Gaussian mixture models.
- Pairwise Constraints: The method incorporates must-link and cannot-link constraints provided by a human expert, which specify which data points should be in the same or different clusters, respectively.
- Active Selection: A3S selects the most informative data points to label at each iteration, based on a combination of clustering uncertainty and pairwise constraint satisfaction.
The active selection strategy aims to maximize the information gained from each labeled data point, leading to more efficient clustering compared to labeling all data points.
The researchers evaluate A3S on various datasets and show that it outperforms other active clustering methods, especially when pairwise constraints are available. They also demonstrate that A3S can be combined with different base clustering algorithms to achieve superior performance.
Critical Analysis
The key strengths of the A3S method are its flexibility, as it can work with different base clustering algorithms, and its ability to effectively leverage pairwise constraints to guide the active selection of data points.
However, the paper does not discuss the potential limitations of the approach, such as the reliability and availability of pairwise constraints in real-world scenarios. The researchers also do not address the impact of the quality or quantity of pairwise constraints on the overall clustering performance.
Additionally, the paper could have provided more insights into the trade-offs between the benefits of active clustering and the effort required to obtain pairwise constraints from human experts. Exploring these aspects would help readers better understand the practical applicability and limitations of the A3S method.
Further research could investigate the robustness of A3S to noisy or incomplete pairwise constraints, as well as examine its performance on larger or more complex datasets. Incorporating methods to automatically generate pairwise constraints, such as edge-guided class-balanced active learning or towards adaptive pseudo-label learning, could also enhance the practical usability of the A3S framework.
Conclusion
A3S: A General Active Clustering Method with Pairwise Constraints introduces a novel active clustering approach that effectively leverages pairwise constraints to guide the selection of data points to label. By strategically choosing the most informative data points, A3S can achieve superior clustering performance compared to traditional methods, especially when pairwise constraints are available.
The versatility of A3S, its ability to work with different base clustering algorithms, and its demonstrated improvements in clustering accuracy make it a promising technique for a wide range of applications, from information-theoretic active correlation clustering to classification tree-based active learning. Further research and practical applications of A3S could yield valuable insights and advancements in the field of active clustering and semi-supervised learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A3S: A General Active Clustering Method with Pairwise Constraints
Xun Deng, Junlong Liu, Han Zhong, Fuli Feng, Chen Shen, Xiangnan He, Jieping Ye, Zheng Wang
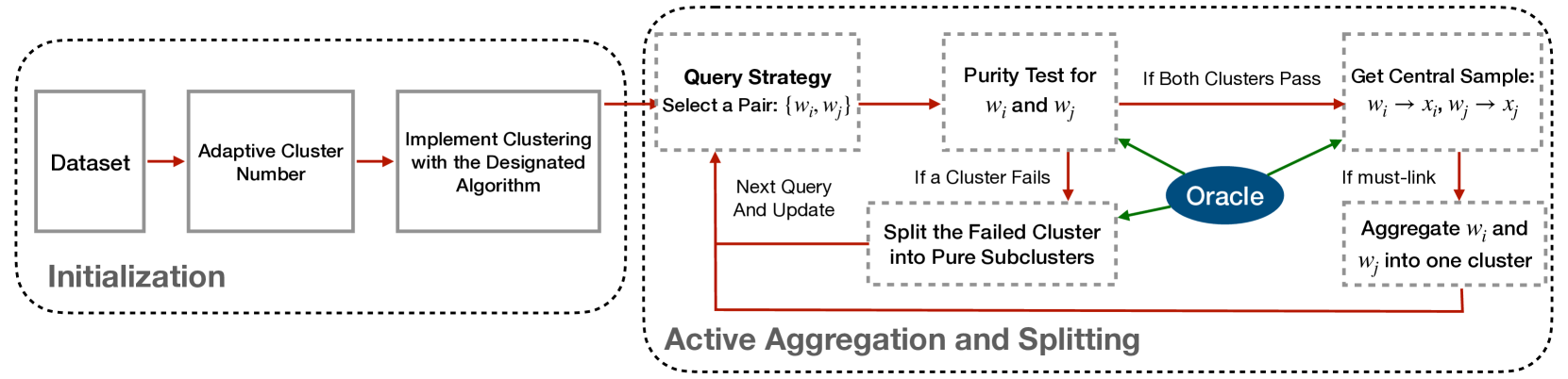
Active clustering aims to boost the clustering performance by integrating human-annotated pairwise constraints through strategic querying. Conventional approaches with semi-supervised clustering schemes encounter high query costs when applied to large datasets with numerous classes. To address these limitations, we propose a novel Adaptive Active Aggregation and Splitting (A3S) framework, falling within the cluster-adjustment scheme in active clustering. A3S features strategic active clustering adjustment on the initial cluster result, which is obtained by an adaptive clustering algorithm. In particular, our cluster adjustment is inspired by the quantitative analysis of Normalized mutual information gain under the information theory framework and can provably improve the clustering quality. The proposed A3S framework significantly elevates the performance and scalability of active clustering. In extensive experiments across diverse real-world datasets, A3S achieves desired results with significantly fewer human queries compared with existing methods.
Read more7/16/2024

0
Information-Theoretic Active Correlation Clustering
Linus Aronsson, Morteza Haghir Chehreghani
We study correlation clustering where the pairwise similarities are not known in advance. For this purpose, we employ active learning to query pairwise similarities in a cost-efficient way. We propose a number of effective information-theoretic acquisition functions based on entropy and information gain. We extensively investigate the performance of our methods in different settings and demonstrate their superior performance compared to the alternatives.
Read more5/24/2024
0
Adaptive Self-supervised Robust Clustering for Unstructured Data with Unknown Cluster Number
Chen-Lu Ding, Jiancan Wu, Wei Lin, Shiyang Shen, Xiang Wang, Yancheng Yuan
We introduce a novel self-supervised deep clustering approach tailored for unstructured data without requiring prior knowledge of the number of clusters, termed Adaptive Self-supervised Robust Clustering (ASRC). In particular, ASRC adaptively learns the graph structure and edge weights to capture both local and global structural information. The obtained graph enables us to learn clustering-friendly feature representations by an enhanced graph auto-encoder with contrastive learning technique. It further leverages the clustering results adaptively obtained by robust continuous clustering (RCC) to generate prototypes for negative sampling, which can further contribute to promoting consistency among positive pairs and enlarging the gap between positive and negative samples. ASRC obtains the final clustering results by applying RCC to the learned feature representations with their consistent graph structure and edge weights. Extensive experiments conducted on seven benchmark datasets demonstrate the efficacy of ASRC, demonstrating its superior performance over other popular clustering models. Notably, ASRC even outperforms methods that rely on prior knowledge of the number of clusters, highlighting its effectiveness in addressing the challenges of clustering unstructured data.
Read more7/31/2024

0
ESA: Annotation-Efficient Active Learning for Semantic Segmentation
Jinchao Ge, Zeyu Zhang, Minh Hieu Phan, Bowen Zhang, Akide Liu, Yang Zhao
Active learning enhances annotation efficiency by selecting the most revealing samples for labeling, thereby reducing reliance on extensive human input. Previous methods in semantic segmentation have centered on individual pixels or small areas, neglecting the rich patterns in natural images and the power of advanced pre-trained models. To address these challenges, we propose three key contributions: Firstly, we introduce Entity-Superpixel Annotation (ESA), an innovative and efficient active learning strategy which utilizes a class-agnostic mask proposal network coupled with super-pixel grouping to capture local structural cues. Additionally, our method selects a subset of entities within each image of the target domain, prioritizing superpixels with high entropy to ensure comprehensive representation. Simultaneously, it focuses on a limited number of key entities, thereby optimizing for efficiency. By utilizing an annotator-friendly design that capitalizes on the inherent structure of images, our approach significantly outperforms existing pixel-based methods, achieving superior results with minimal queries, specifically reducing click cost by 98% and enhancing performance by 1.71%. For instance, our technique requires a mere 40 clicks for annotation, a stark contrast to the 5000 clicks demanded by conventional methods.
Read more8/27/2024