Information-Theoretic Active Correlation Clustering

0

Sign in to get full access
Overview
- This paper presents new acquisition functions for active correlation clustering, which is a technique for organizing data into meaningful groups.
- The authors propose several acquisition functions that aim to improve the efficiency and effectiveness of the active clustering process.
- They evaluate the performance of their proposed acquisition functions on various real-world datasets and compare them to existing methods.
Plain English Explanation
Active correlation clustering is a way of organizing data into groups or "clusters" that are related to each other. This can be useful for tasks like customer segmentation, image classification, and bioinformatics.
The key challenge is figuring out the best way to select which data points to ask the user about in order to quickly learn the underlying structure of the data and create accurate clusters. The authors of this paper tested several new "acquisition functions" - algorithms that decide which data points to focus on.
Their goal was to develop acquisition functions that could identify the most informative data points to label, leading to better clustering results with fewer user inputs. This could make active correlation clustering more practical and useful in real-world applications where obtaining labeled data can be time-consuming and costly.
The authors evaluated their proposed acquisition functions on several real-world datasets and found that they outperformed existing methods in terms of clustering accuracy and efficiency. This suggests their techniques could be valuable tools for researchers and practitioners working on problems that involve grouping data into meaningful categories.
Technical Explanation
The paper focuses on the problem of active correlation clustering, which aims to group data points into clusters by actively querying a user for labels on selected data points. The authors propose several new acquisition functions to guide this active learning process:
- Information Gain: Selects the data point that would provide the most information gain about the cluster assignments.
- Diversity: Selects data points that are dissimilar to previously queried points, to explore different regions of the data space.
- Additive Effect: Selects data points whose labels are expected to have the greatest positive impact on the clustering objective.
- Margin: Selects data points with the least confidence in their cluster assignments.
The authors evaluate these acquisition functions on several real-world datasets and compare their performance to existing active correlation clustering methods. They find that the proposed acquisition functions generally outperform the baselines in terms of clustering accuracy and the number of queries required to achieve a target performance level.
Critical Analysis
The paper provides a thorough evaluation of the proposed acquisition functions and demonstrates their effectiveness on a range of datasets. However, there are a few potential limitations and areas for further research:
-
The authors only consider pairwise constraints (must-link and cannot-link) in the active correlation clustering framework. It would be interesting to explore how these acquisition functions perform when additional types of constraints or side information are available.
-
The paper focuses on the single-query setting, where only one data point is queried at a time. In practice, it may be more efficient to query multiple data points simultaneously. Extending the proposed methods to the batch-query setting could be an interesting direction for future work.
-
The authors do not provide a theoretical analysis of the proposed acquisition functions. A better understanding of the properties and convergence guarantees of these methods could lend further insights into their strengths and limitations.
Overall, the paper presents a valuable contribution to the field of active correlation clustering by introducing several effective acquisition functions. The results suggest these techniques could be useful tools for practitioners working on data organization and clustering problems.
Conclusion
This paper explores new acquisition functions for active correlation clustering, a technique for grouping data into meaningful clusters by actively querying a user for labels on selected data points. The authors propose several acquisition functions that aim to identify the most informative data points to label, with the goal of improving the efficiency and effectiveness of the active clustering process.
The authors' evaluation on real-world datasets demonstrates that their proposed acquisition functions generally outperform existing methods in terms of clustering accuracy and the number of queries required. This suggests these techniques could be valuable tools for researchers and practitioners working on problems that involve organizing data into meaningful categories.
While the paper provides a thorough empirical analysis, there are a few potential limitations and avenues for future research, such as exploring different types of constraints, extending the methods to batch-query settings, and conducting theoretical analysis. Overall, this work represents an important contribution to the field of active correlation clustering and data organization more broadly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Information-Theoretic Active Correlation Clustering
Linus Aronsson, Morteza Haghir Chehreghani
We study correlation clustering where the pairwise similarities are not known in advance. For this purpose, we employ active learning to query pairwise similarities in a cost-efficient way. We propose a number of effective information-theoretic acquisition functions based on entropy and information gain. We extensively investigate the performance of our methods in different settings and demonstrate their superior performance compared to the alternatives.
Read more5/24/2024
🔗
0
Hierarchical Correlation Clustering and Tree Preserving Embedding
Morteza Haghir Chehreghani, Mostafa Haghir Chehreghani
We propose a hierarchical correlation clustering method that extends the well-known correlation clustering to produce hierarchical clusters applicable to both positive and negative pairwise dissimilarities. Then, in the following, we study unsupervised representation learning with such hierarchical correlation clustering. For this purpose, we first investigate embedding the respective hierarchy to be used for tree preserving embedding and feature extraction. Thereafter, we study the extension of minimax distance measures to correlation clustering, as another representation learning paradigm. Finally, we demonstrate the performance of our methods on several datasets.
Read more6/13/2024
0
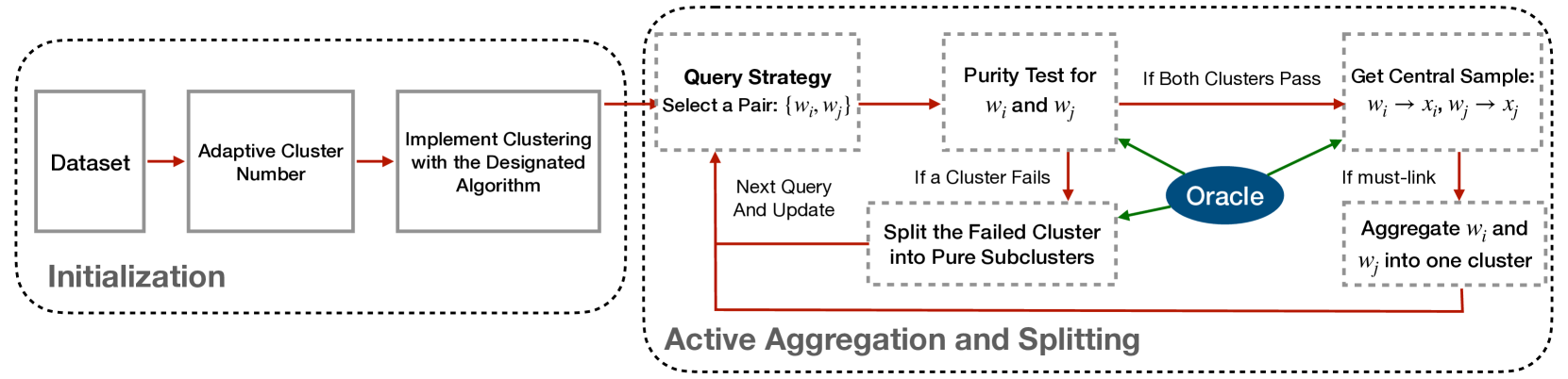
A3S: A General Active Clustering Method with Pairwise Constraints
Xun Deng, Junlong Liu, Han Zhong, Fuli Feng, Chen Shen, Xiangnan He, Jieping Ye, Zheng Wang
Active clustering aims to boost the clustering performance by integrating human-annotated pairwise constraints through strategic querying. Conventional approaches with semi-supervised clustering schemes encounter high query costs when applied to large datasets with numerous classes. To address these limitations, we propose a novel Adaptive Active Aggregation and Splitting (A3S) framework, falling within the cluster-adjustment scheme in active clustering. A3S features strategic active clustering adjustment on the initial cluster result, which is obtained by an adaptive clustering algorithm. In particular, our cluster adjustment is inspired by the quantitative analysis of Normalized mutual information gain under the information theory framework and can provably improve the clustering quality. The proposed A3S framework significantly elevates the performance and scalability of active clustering. In extensive experiments across diverse real-world datasets, A3S achieves desired results with significantly fewer human queries compared with existing methods.
Read more7/16/2024
🔗
0
Multilayer Correlation Clustering
Atsushi Miyauchi, Florian Adriaens, Francesco Bonchi, Nikolaj Tatti
In this paper, we establish Multilayer Correlation Clustering, a novel generalization of Correlation Clustering (Bansal et al., FOCS '02) to the multilayer setting. In this model, we are given a series of inputs of Correlation Clustering (called layers) over the common set $V$. The goal is then to find a clustering of $V$ that minimizes the $ell_p$-norm ($pgeq 1$) of the disagreements vector, which is defined as the vector (with dimension equal to the number of layers), each element of which represents the disagreements of the clustering on the corresponding layer. For this generalization, we first design an $O(Llog n)$-approximation algorithm, where $L$ is the number of layers, based on the well-known region growing technique. We then study an important special case of our problem, namely the problem with the probability constraint. For this case, we first give an $(alpha+2)$-approximation algorithm, where $alpha$ is any possible approximation ratio for the single-layer counterpart. For instance, we can take $alpha=2.5$ in general (Ailon et al., JACM '08) and $alpha=1.73+epsilon$ for the unweighted case (Cohen-Addad et al., FOCS '23). Furthermore, we design a $4$-approximation algorithm, which improves the above approximation ratio of $alpha+2=4.5$ for the general probability-constraint case. Computational experiments using real-world datasets demonstrate the effectiveness of our proposed algorithms.
Read more4/26/2024