Reflective Policy Optimization
2406.03678
0
0
Abstract
On-policy reinforcement learning methods, like Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO), often demand extensive data per update, leading to sample inefficiency. This paper introduces Reflective Policy Optimization (RPO), a novel on-policy extension that amalgamates past and future state-action information for policy optimization. This approach empowers the agent for introspection, allowing modifications to its actions within the current state. Theoretical analysis confirms that policy performance is monotonically improved and contracts the solution space, consequently expediting the convergence procedure. Empirical results demonstrate RPO's feasibility and efficacy in two reinforcement learning benchmarks, culminating in superior sample efficiency. The source code of this work is available at https://github.com/Edgargan/RPO.
Create account to get full access
Overview
- This paper introduces Reflective Policy Optimization (RPO), a new reinforcement learning algorithm that aims to improve the sample efficiency and performance of existing policy optimization methods.
- The key idea behind RPO is to maintain a separate "reflective" policy that learns to mimic the behavior of the main policy, which is then used to guide the exploration process during training.
- The authors demonstrate that RPO outperforms several state-of-the-art policy optimization algorithms, including Transductive Off-Policy Proximal Policy Optimization, Simple Policy Optimization, DPO meets PPO: Reinforced Token Optimization (RLHF), Matrix Low-Rank Trust Region Policy Optimization, and ClothPPO: Proximal Policy Optimization Enhancing Framework for Robotic, on a variety of benchmark tasks.
Plain English Explanation
The paper introduces a new reinforcement learning algorithm called Reflective Policy Optimization (RPO). The key idea is to maintain a separate "reflective" policy that learns to mimic the behavior of the main policy. This reflective policy is then used to guide the exploration process during training, which helps the main policy learn more efficiently and perform better.
Reinforcement learning is a type of machine learning where an agent (such as a robot or a computer program) learns to make decisions by interacting with an environment and receiving rewards or punishments for its actions. Policy optimization algorithms, such as Proximal Policy Optimization (PPO), are used to train the agent's decision-making policy.
The authors of this paper noticed that existing policy optimization algorithms can struggle with sample efficiency, meaning they require a lot of training data to learn effective policies. The RPO algorithm aims to address this by maintaining a separate reflective policy that can help the main policy explore the environment more effectively, leading to faster and better learning.
The authors show that RPO outperforms several state-of-the-art policy optimization algorithms on a variety of benchmark tasks, demonstrating the potential of this new approach to improve the performance and sample efficiency of reinforcement learning systems.
Technical Explanation
The paper introduces a new reinforcement learning algorithm called Reflective Policy Optimization (RPO). The key idea behind RPO is to maintain a separate "reflective" policy that learns to mimic the behavior of the main policy. This reflective policy is then used to guide the exploration process during training, which helps the main policy learn more efficiently and perform better.
Specifically, the authors propose a two-stage training process for RPO. In the first stage, the main policy is trained using a standard policy optimization algorithm, such as Proximal Policy Optimization (PPO). In the second stage, a reflective policy is trained to mimic the behavior of the main policy, using a combination of behavioral cloning and inverse reinforcement learning.
During the main policy's training, the reflective policy is used to generate additional exploration trajectories, which are then used to update the main policy. The authors hypothesize that this reflective exploration process can lead to faster and more effective learning, as the main policy is guided towards regions of the state-action space that are more relevant to its final performance.
The authors evaluate RPO on a variety of benchmark tasks, including standard OpenAI Gym environments and more complex robotic control problems. They compare the performance of RPO to several state-of-the-art policy optimization algorithms, including Transductive Off-Policy Proximal Policy Optimization, Simple Policy Optimization, DPO meets PPO: Reinforced Token Optimization (RLHF), and Matrix Low-Rank Trust Region Policy Optimization. The results demonstrate that RPO outperforms these baselines in terms of both sample efficiency and final performance, highlighting the potential of this new approach to improve the effectiveness of reinforcement learning systems.
Critical Analysis
The paper presents a novel and promising approach to improving the sample efficiency and performance of policy optimization algorithms in reinforcement learning. The key idea of maintaining a separate reflective policy to guide exploration is an intriguing concept that has the potential to address some of the limitations of existing methods.
One potential limitation of the RPO approach is the added computational and training complexity of maintaining the reflective policy. The authors do not provide a detailed analysis of the overhead incurred by this additional component, which could be an important consideration for real-world applications with limited computational resources.
Additionally, the paper does not explore the robustness of the RPO algorithm to different types of environments or task complexities. It would be valuable to understand how the relative performance of RPO compares to other algorithms in more challenging or diverse settings, as this could help inform the broader applicability of the method.
Another area for further research could be investigating the interpretability and explainability of the reflective policy. Understanding the factors that influence the reflective policy's behavior and how it relates to the main policy's decision-making process could provide valuable insights and potentially lead to further improvements in the algorithm.
Overall, the Reflective Policy Optimization approach presented in this paper is a promising contribution to the field of reinforcement learning, and the authors have demonstrated its effectiveness on several benchmark tasks. Further exploration of the method's scalability, robustness, and interpretability could help solidify its position as a valuable tool for improving the performance and sample efficiency of reinforcement learning systems.
Conclusion
This paper introduces Reflective Policy Optimization (RPO), a new reinforcement learning algorithm that maintains a separate "reflective" policy to guide the exploration process of the main policy. The key idea is that the reflective policy, trained to mimic the behavior of the main policy, can help the main policy learn more efficiently and perform better on a variety of tasks.
The authors show that RPO outperforms several state-of-the-art policy optimization algorithms, including Transductive Off-Policy Proximal Policy Optimization, Simple Policy Optimization, DPO meets PPO: Reinforced Token Optimization (RLHF), Matrix Low-Rank Trust Region Policy Optimization, and ClothPPO: Proximal Policy Optimization Enhancing Framework for Robotic, on a range of benchmark tasks. This suggests that the RPO approach has the potential to significantly improve the sample efficiency and performance of reinforcement learning systems, which could have important implications for real-world applications.
While the paper presents a promising new technique, there are still some open questions and potential limitations that warrant further investigation, such as the computational overhead of the reflective policy, the robustness of the approach to different environments and task complexities, and the interpretability of the reflective policy's decision-making process. Addressing these areas could help solidify the position of Reflective Policy Optimization as a valuable tool for advancing the state of the art in reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Transductive Off-policy Proximal Policy Optimization
Yaozhong Gan, Renye Yan, Xiaoyang Tan, Zhe Wu, Junliang Xing
0
0
Proximal Policy Optimization (PPO) is a popular model-free reinforcement learning algorithm, esteemed for its simplicity and efficacy. However, due to its inherent on-policy nature, its proficiency in harnessing data from disparate policies is constrained. This paper introduces a novel off-policy extension to the original PPO method, christened Transductive Off-policy PPO (ToPPO). Herein, we provide theoretical justification for incorporating off-policy data in PPO training and prudent guidelines for its safe application. Our contribution includes a novel formulation of the policy improvement lower bound for prospective policies derived from off-policy data, accompanied by a computationally efficient mechanism to optimize this bound, underpinned by assurances of monotonic improvement. Comprehensive experimental results across six representative tasks underscore ToPPO's promising performance.
6/7/2024
🛠️
Simple Policy Optimization
Zhengpeng Xie
0
0
PPO (Proximal Policy Optimization) algorithm has demonstrated excellent performance in many fields, and it is considered as a simple version of TRPO (Trust Region Policy Optimization) algorithm. However, the ratio clipping operation in PPO may not always effectively enforce the trust region constraints, this can be a potential factor affecting the stability of the algorithm. In this paper, we propose Simple Policy Optimization (SPO) algorithm, which introduces a novel clipping method for KL divergence between the old and current policies. Extensive experimental results in Atari 2600 environments indicate that, compared to the mainstream variants of PPO, SPO achieves better sample efficiency, extremely low KL divergence, and higher policy entropy, and is robust to the increase in network depth or complexity. More importantly, SPO maintains the simplicity of an unconstrained first-order algorithm. Our code is available at https://github.com/MyRepositories-hub/Simple-Policy-Optimization.
4/30/2024

DPO Meets PPO: Reinforced Token Optimization for RLHF
Han Zhong, Guhao Feng, Wei Xiong, Li Zhao, Di He, Jiang Bian, Liwei Wang
0
0
In the classical Reinforcement Learning from Human Feedback (RLHF) framework, Proximal Policy Optimization (PPO) is employed to learn from sparse, sentence-level rewards -- a challenging scenario in traditional deep reinforcement learning. Despite the great successes of PPO in the alignment of state-of-the-art closed-source large language models (LLMs), its open-source implementation is still largely sub-optimal, as widely reported by numerous research studies. To address these issues, we introduce a framework that models RLHF problems as a Markov decision process (MDP), enabling the capture of fine-grained token-wise information. Furthermore, we provide theoretical insights that demonstrate the superiority of our MDP framework over the previous sentence-level bandit formulation. Under this framework, we introduce an algorithm, dubbed as Reinforced Token Optimization (texttt{RTO}), which learns the token-wise reward function from preference data and performs policy optimization based on this learned token-wise reward signal. Theoretically, texttt{RTO} is proven to have the capability of finding the near-optimal policy sample-efficiently. For its practical implementation, texttt{RTO} innovatively integrates Direct Preference Optimization (DPO) and PPO. DPO, originally derived from sparse sentence rewards, surprisingly provides us with a token-wise characterization of response quality, which is seamlessly incorporated into our subsequent PPO training stage. Extensive real-world alignment experiments verify the effectiveness of the proposed approach.
4/30/2024
Matrix Low-Rank Trust Region Policy Optimization
Sergio Rozada, Antonio G. Marques
0
0
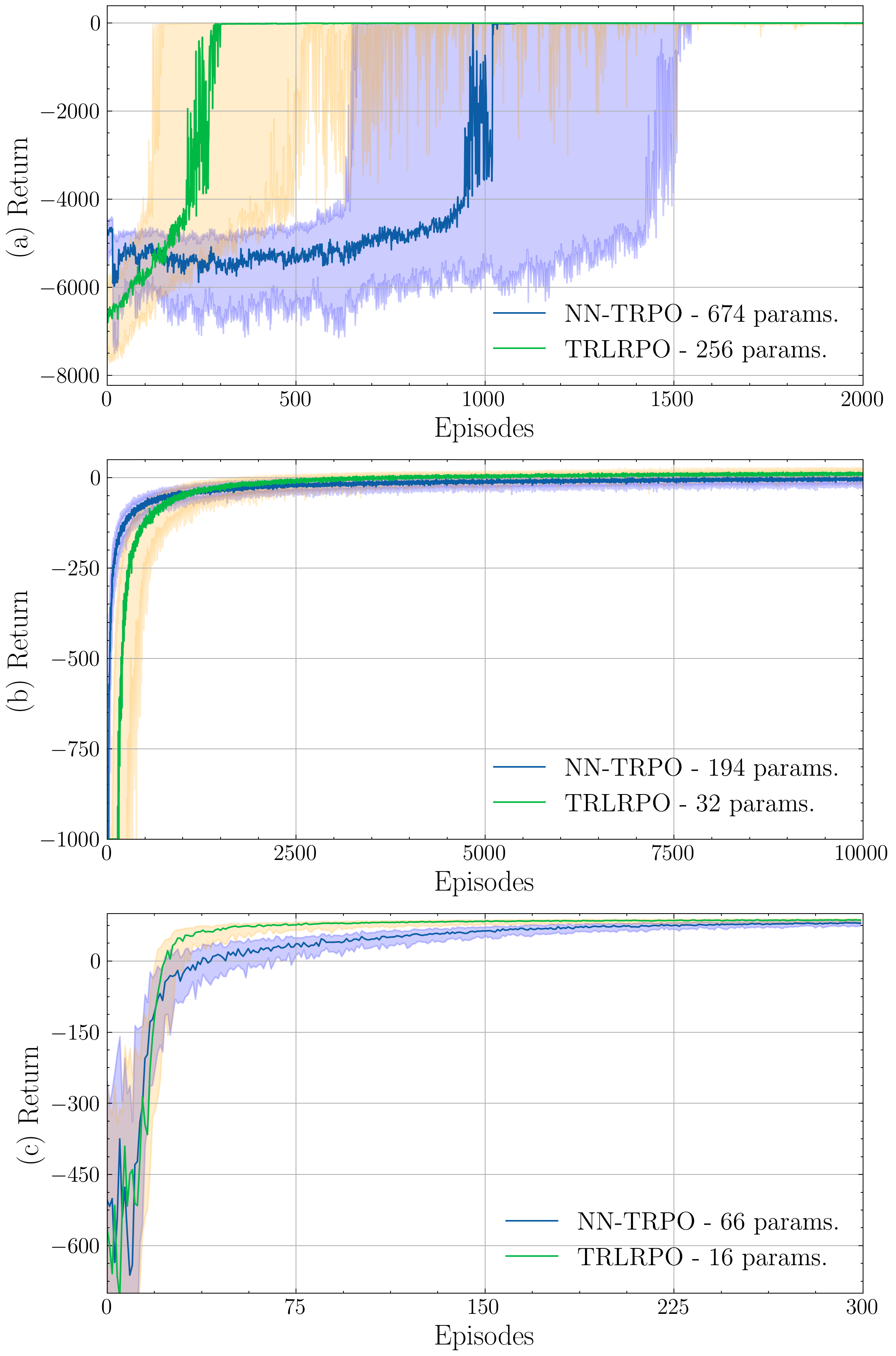
Most methods in reinforcement learning use a Policy Gradient (PG) approach to learn a parametric stochastic policy that maps states to actions. The standard approach is to implement such a mapping via a neural network (NN) whose parameters are optimized using stochastic gradient descent. However, PG methods are prone to large policy updates that can render learning inefficient. Trust region algorithms, like Trust Region Policy Optimization (TRPO), constrain the policy update step, ensuring monotonic improvements. This paper introduces low-rank matrix-based models as an efficient alternative for estimating the parameters of TRPO algorithms. By gathering the stochastic policy's parameters into a matrix and applying matrix-completion techniques, we promote and enforce low rank. Our numerical studies demonstrate that low-rank matrix-based policy models effectively reduce both computational and sample complexities compared to NN models, while maintaining comparable aggregated rewards.
5/29/2024