Abstracted Gaussian Prototypes for One-Shot Concept Learning

0

Sign in to get full access
Overview
- This paper proposes a method for one-shot concept learning using abstracted Gaussian prototypes.
- The approach aims to model how humans learn new concepts from limited data by leveraging prototype representations.
- The model is evaluated on the Omniglot challenge, a benchmark for few-shot learning.
Plain English Explanation
The researchers in this paper are interested in how humans can learn new concepts or ideas from just a few examples. This is called "one-shot" or "few-shot" learning, and it's something that AI systems often struggle with compared to humans.
The key idea behind the researchers' approach is to use "prototypes" - abstract representations that capture the key features of a concept. For example, if you were learning the concept of a "chair," you might form a mental prototype that captures the essential attributes like having a seat, back, and legs. The researchers hypothesize that humans leverage these prototypical representations when learning new concepts from limited data.
To implement this in an AI system, the researchers use a type of machine learning model called a Variational Autoencoder (VAE). This allows the system to learn an abstract, Gaussian-distributed representation for each concept, which acts as a prototype. When presented with a new example of a concept, the model can quickly compare it to the learned prototypes to classify it.
The researchers evaluate their approach on the Omniglot Challenge, a benchmark for few-shot learning that involves recognizing handwritten characters from different alphabets. By using the abstracted Gaussian prototypes, the model is able to perform well on this challenging task, suggesting it may capture something fundamental about how humans learn new concepts.
Technical Explanation
The core of the researchers' approach is a Variational Autoencoder (VAE) that learns Gaussian-distributed prototypes for each concept. The VAE consists of an encoder network that maps input images to a latent representation, and a decoder network that reconstructs the input from the latent space.
Crucially, the latent representation is constrained to be Gaussian distributed, with each concept modeled as a Gaussian prototype in the latent space. This allows the model to quickly compare new examples to the learned prototypes and classify them accordingly.
During training, the model is presented with examples from various concepts (e.g. characters from different alphabets in the Omniglot dataset). The VAE learns to encode these examples into the Gaussian prototypes in the latent space, while also reconstructing the original inputs. This encourages the model to learn abstract, generalizable representations for each concept.
At test time, the model is presented with a new example of a concept, along with a small number of "support" examples. It encodes the new example and compares it to the prototypes learned for the support examples, classifying it as the closest matching concept.
The researchers find that this approach outperforms other few-shot learning methods on the Omniglot challenge, demonstrating the power of the abstracted Gaussian prototypes for rapid concept learning.
Critical Analysis
The researchers present a compelling approach to few-shot learning that is inspired by how humans learn new concepts. By using Gaussian prototypes in the latent space of a VAE, the model is able to quickly adapt to new examples and classify them based on their similarity to the learned concept representations.
However, the paper does not fully explore the limitations or potential downsides of this approach. For example, the Gaussian assumption may not be appropriate for all types of concepts, and the model's performance could suffer if the true distribution of the concepts deviates significantly from a Gaussian.
Additionally, the paper does not discuss how the model would scale to learning a large number of diverse concepts, or how it might handle concepts with significant within-class variation. These are important considerations for building AI systems that can truly learn like humans do.
Overall, this research is a promising step towards more human-like concept learning in AI, but further work is needed to fully understand the strengths, weaknesses, and broader applicability of this approach.
Conclusion
The researchers in this paper have proposed a novel method for one-shot concept learning that leverages abstracted Gaussian prototypes. By learning these prototypical representations using a Variational Autoencoder, the model is able to quickly classify new examples of concepts based on their similarity to the learned prototypes.
This work represents an important step towards developing AI systems that can learn like humans do, by forming generalizable representations of concepts from limited data. While the approach has promising results on the Omniglot challenge, further research is needed to understand its broader applicability and potential limitations.
Nonetheless, this research provides valuable insights into the role of prototypes in human concept learning, and demonstrates how such principles can be incorporated into machine learning models to enhance their few-shot learning capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Abstracted Gaussian Prototypes for One-Shot Concept Learning
Chelsea Zou, Kenneth J. Kurtz
We introduce a cluster-based generative image segmentation framework to encode higher-level representations of visual concepts based on one-shot learning inspired by the Omniglot Challenge. The inferred parameters of each component of a Gaussian Mixture Model (GMM) represent a distinct topological subpart of a visual concept. Sampling new data from these parameters generates augmented subparts to build a more robust prototype for each concept, i.e., the Abstracted Gaussian Prototype (AGP). This framework addresses one-shot classification tasks using a cognitively-inspired similarity metric and addresses one-shot generative tasks through a novel AGP-VAE pipeline employing variational autoencoders (VAEs) to generate new class variants. Results from human judges reveal that the generative pipeline produces novel examples and classes of visual concepts that are broadly indistinguishable from those made by humans. The proposed framework leads to impressive but not state-of-the-art classification accuracy; thus, the contribution is two-fold: 1) the system is uniquely low in theoretical and computational complexity and operates in a completely standalone manner compared while existing approaches draw heavily on pre-training or knowledge engineering; and 2) in contrast with competing neural network models, the AGP approach addresses the importance of breadth of task capability emphasized in the Omniglot challenge (i.e., successful performance on generative tasks). These two points are critical as we advance toward an understanding of how learning/reasoning systems can produce viable, robust, and flexible concepts based on literally nothing more than a single example.
Read more9/2/2024
0
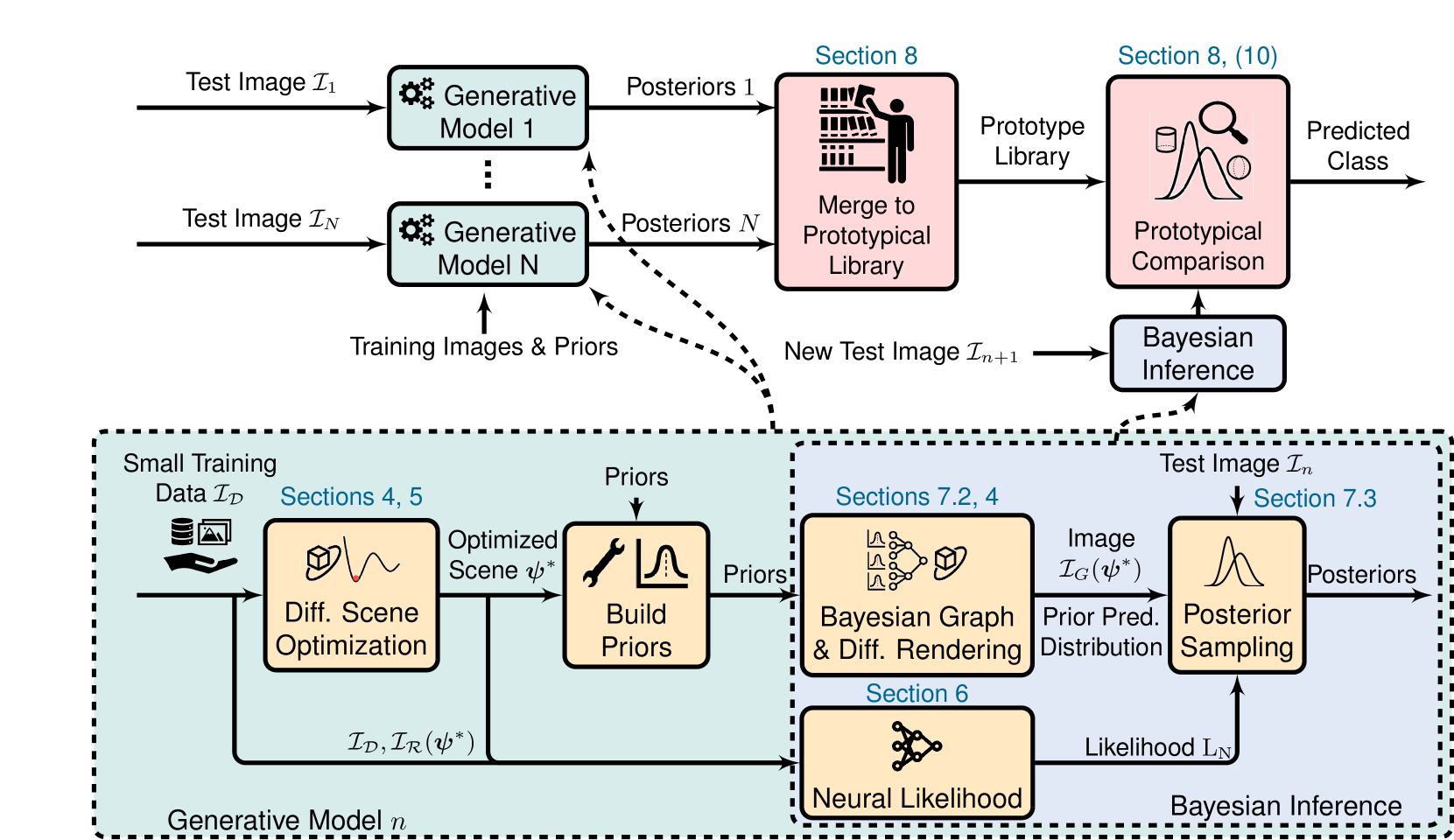
Bayesian Inverse Graphics for Few-Shot Concept Learning
Octavio Arriaga, Jichen Guo, Rebecca Adam, Sebastian Houben, Frank Kirchner
Humans excel at building generalizations of new concepts from just one single example. Contrary to this, current computer vision models typically require large amount of training samples to achieve a comparable accuracy. In this work we present a Bayesian model of perception that learns using only minimal data, a prototypical probabilistic program of an object. Specifically, we propose a generative inverse graphics model of primitive shapes, to infer posterior distributions over physically consistent parameters from one or several images. We show how this representation can be used for downstream tasks such as few-shot classification and pose estimation. Our model outperforms existing few-shot neural-only classification algorithms and demonstrates generalization across varying lighting conditions, backgrounds, and out-of-distribution shapes. By design, our model is uncertainty-aware and uses our new differentiable renderer for optimizing global scene parameters through gradient descent, sampling posterior distributions over object parameters with Markov Chain Monte Carlo (MCMC), and using a neural based likelihood function.
Read more9/16/2024
🖼️
0
Mixture of Gaussian-distributed Prototypes with Generative Modelling for Interpretable and Trustworthy Image Recognition
Chong Wang, Yuanhong Chen, Fengbei Liu, Yuyuan Liu, Davis James McCarthy, Helen Frazer, Gustavo Carneiro
Prototypical-part methods, e.g., ProtoPNet, enhance interpretability in image recognition by linking predictions to training prototypes, thereby offering intuitive insights into their decision-making. Existing methods, which rely on a point-based learning of prototypes, typically face two critical issues: 1) the learned prototypes have limited representation power and are not suitable to detect Out-of-Distribution (OoD) inputs, reducing their decision trustworthiness; and 2) the necessary projection of the learned prototypes back into the space of training images causes a drastic degradation in the predictive performance. Furthermore, current prototype learning adopts an aggressive approach that considers only the most active object parts during training, while overlooking sub-salient object regions which still hold crucial classification information. In this paper, we present a new generative paradigm to learn prototype distributions, termed as Mixture of Gaussian-distributed Prototypes (MGProto). The distribution of prototypes from MGProto enables both interpretable image classification and trustworthy recognition of OoD inputs. The optimisation of MGProto naturally projects the learned prototype distributions back into the training image space, thereby addressing the performance degradation caused by prototype projection. Additionally, we develop a novel and effective prototype mining strategy that considers not only the most active but also sub-salient object parts. To promote model compactness, we further propose to prune MGProto by removing prototypes with low importance priors. Experiments on CUB-200-2011, Stanford Cars, Stanford Dogs, and Oxford-IIIT Pets datasets show that MGProto achieves state-of-the-art image recognition and OoD detection performances, while providing encouraging interpretability results.
Read more6/6/2024

0
ProtoGMM: Multi-prototype Gaussian-Mixture-based Domain Adaptation Model for Semantic Segmentation
Nazanin Moradinasab, Laura S. Shankman, Rebecca A. Deaton, Gary K. Owens, Donald E. Brown
Domain adaptive semantic segmentation aims to generate accurate and dense predictions for an unlabeled target domain by leveraging a supervised model trained on a labeled source domain. The prevalent self-training approach involves retraining the dense discriminative classifier of $p(class|pixel feature)$ using the pseudo-labels from the target domain. While many methods focus on mitigating the issue of noisy pseudo-labels, they often overlook the underlying data distribution p(pixel feature|class) in both the source and target domains. To address this limitation, we propose the multi-prototype Gaussian-Mixture-based (ProtoGMM) model, which incorporates the GMM into contrastive losses to perform guided contrastive learning. Contrastive losses are commonly executed in the literature using memory banks, which can lead to class biases due to underrepresented classes. Furthermore, memory banks often have fixed capacities, potentially restricting the model's ability to capture diverse representations of the target/source domains. An alternative approach is to use global class prototypes (i.e. averaged features per category). However, the global prototypes are based on the unimodal distribution assumption per class, disregarding within-class variation. To address these challenges, we propose the ProtoGMM model. This novel approach involves estimating the underlying multi-prototype source distribution by utilizing the GMM on the feature space of the source samples. The components of the GMM model act as representative prototypes. To achieve increased intra-class semantic similarity, decreased inter-class similarity, and domain alignment between the source and target domains, we employ multi-prototype contrastive learning between source distribution and target samples. The experiments show the effectiveness of our method on UDA benchmarks.
Read more6/28/2024