Abstractive summarization from Audio Transcription

0
🛠️
Sign in to get full access
Overview
- This paper presents a method for generating abstractive summaries from audio transcriptions.
- The authors propose a novel approach that leverages large pre-trained language models to produce concise, informative summaries from spoken text.
- The technique aims to address the challenge of summarizing audio content, which is an important task for applications like meeting notes, lecture recordings, and podcasts.
Plain English Explanation
The researchers developed a system that can take a transcript of spoken audio (such as a recorded conversation or presentation) and automatically generate a summary of the key points. This is a challenging task because spoken language is often less structured and more conversational than written text, making it harder to extract the most important information.
To tackle this problem, the researchers used large language models - powerful AI systems that have been trained on massive amounts of text data to understand and generate human-like language. By fine-tuning these pre-trained models on the task of summarizing audio transcripts, the researchers were able to create a system that can produce concise, meaningful summaries.
The advantage of this approach is that it doesn't require manually creating summaries for a large training dataset, which can be time-consuming and expensive. Instead, the system learns to summarize based on the patterns and structure it discovers in the data, allowing it to generalize to new audio content.
The researchers evaluated their method on several benchmark datasets for speech summarization, and found that it outperformed previous state-of-the-art techniques. This suggests the approach could be a valuable tool for applications like meeting note-taking, lecture recording transcription, and podcast summarization.
Technical Explanation
The key innovation in this paper is the use of pre-trained language models for the task of abstractive speech summarization. The authors fine-tune these large, powerful models on datasets of audio transcripts paired with human-written summaries.
The fine-tuning process allows the model to learn the patterns and structures of effective summarization, even for the more informal and conversational language found in speech transcripts. This is in contrast to previous approaches that relied on hand-engineered features or seq2seq models trained from scratch.
The authors experiment with different model architectures and training regimes, including strategies for integrating pre-trained speech and language models and using multi-task learning to leverage additional related tasks.
Through extensive evaluations on benchmark datasets, the researchers demonstrate that their fine-tuned language model approach outperforms previous state-of-the-art methods for audio summarization in terms of both automatic metrics and human evaluation.
Critical Analysis
The paper provides a solid technical contribution by showing the effectiveness of large pre-trained language models for the task of abstractive speech summarization. The authors carefully design their experiments and provide thorough analysis of the results.
One limitation mentioned in the paper is the potential for bias in the training data, which could lead the model to produce summaries that reflect societal biases present in the text corpus used for pre-training. The authors suggest further research into debiasing techniques as an important direction.
Additionally, the paper does not explore the model's performance on more diverse or challenging audio content, such as accented speech, background noise, or multi-speaker conversations. Evaluating the robustness of the approach in these real-world scenarios would be a valuable area for future work.
Overall, the research presents a promising step towards more efficient and scalable audio summarization systems, with potential applications in domains like meeting transcription, lecture capture, and podcast production. Continued advancements in this area could significantly enhance the accessibility and utility of spoken content.
Conclusion
This paper introduces a novel approach for generating abstractive summaries from audio transcriptions by leveraging large pre-trained language models. The authors demonstrate that this technique outperforms previous state-of-the-art methods, highlighting its potential to improve the automation and efficiency of summarizing spoken content.
The key contributions of this work include the innovative use of transfer learning from pre-trained language models, as well as extensive evaluations that validate the effectiveness of the proposed approach. While the paper identifies some limitations and areas for future research, the findings suggest that this technique could be a valuable tool for a wide range of applications involving audio data, from meeting notes to podcast production.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Abstractive summarization from Audio Transcription
Ilia Derkach
Currently, large language models are gaining popularity, their achievements are used in many areas, ranging from text translation to generating answers to queries. However, the main problem with these new machine learning algorithms is that training such models requires large computing resources that only large IT companies have. To avoid this problem, a number of methods (LoRA, quantization) have been proposed so that existing models can be effectively fine-tuned for specific tasks. In this paper, we propose an E2E (end to end) audio summarization model using these techniques. In addition, this paper examines the effectiveness of these approaches to the problem under consideration and draws conclusions about the applicability of these methods.
Read more8/12/2024
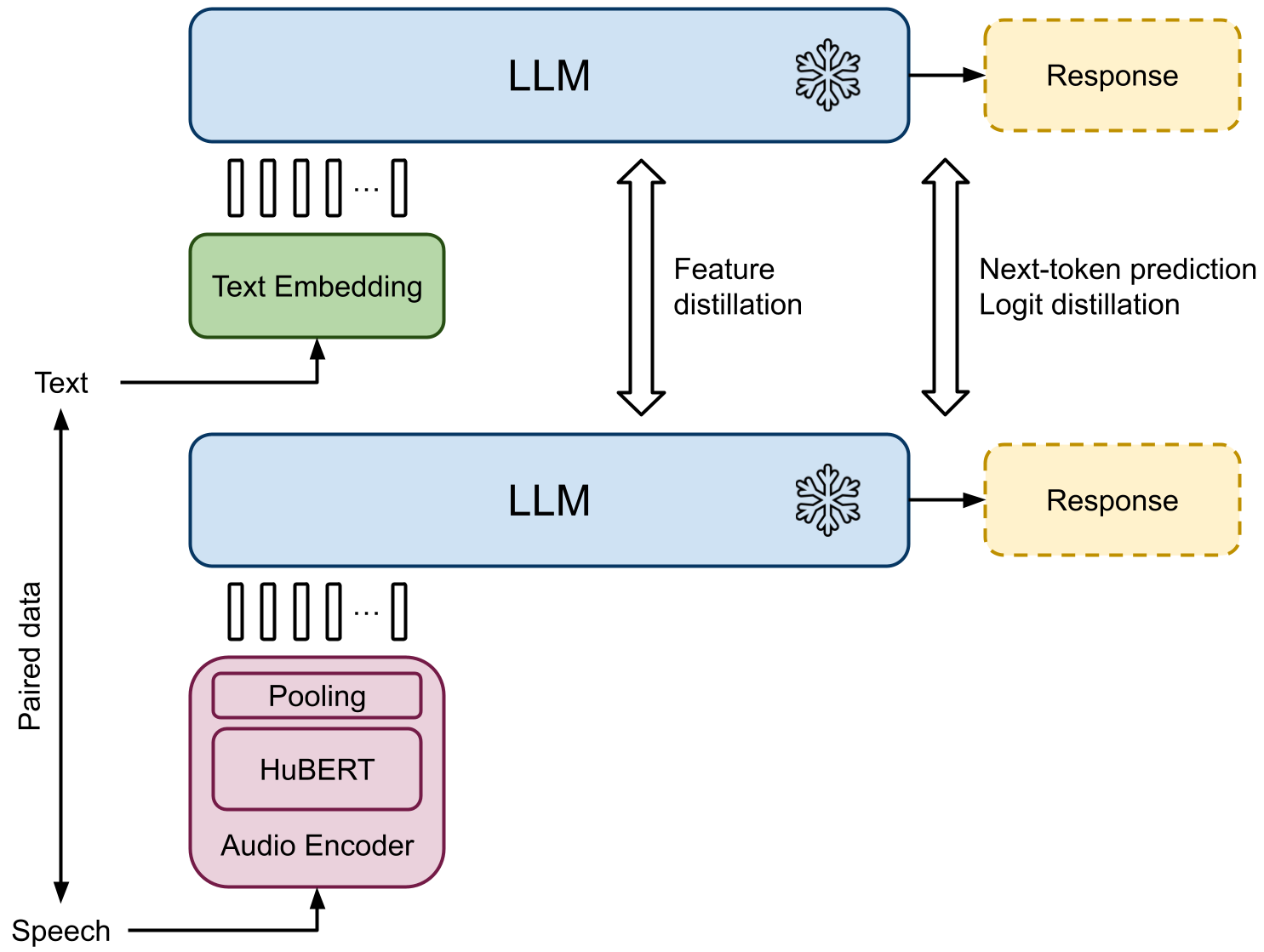
0
Prompting Large Language Models with Audio for General-Purpose Speech Summarization
Wonjune Kang, Deb Roy
In this work, we introduce a framework for speech summarization that leverages the processing and reasoning capabilities of large language models (LLMs). We propose an end-to-end system that combines an instruction-tuned LLM with an audio encoder that converts speech into token representations that the LLM can interpret. Using a dataset with paired speech-text data, the overall system is trained to generate consistent responses to prompts with the same semantic information regardless of the input modality. The resulting framework allows the LLM to process speech inputs in the same way as text, enabling speech summarization by simply prompting the LLM. Unlike prior approaches, our method is able to summarize spoken content from any arbitrary domain, and it can produce summaries in different styles by varying the LLM prompting strategy. Experiments demonstrate that our approach outperforms a cascade baseline of speech recognition followed by LLM text processing.
Read more6/11/2024

0
Sentence-wise Speech Summarization: Task, Datasets, and End-to-End Modeling with LM Knowledge Distillation
Kohei Matsuura, Takanori Ashihara, Takafumi Moriya, Masato Mimura, Takatomo Kano, Atsunori Ogawa, Marc Delcroix
This paper introduces a novel approach called sentence-wise speech summarization (Sen-SSum), which generates text summaries from a spoken document in a sentence-by-sentence manner. Sen-SSum combines the real-time processing of automatic speech recognition (ASR) with the conciseness of speech summarization. To explore this approach, we present two datasets for Sen-SSum: Mega-SSum and CSJ-SSum. Using these datasets, our study evaluates two types of Transformer-based models: 1) cascade models that combine ASR and strong text summarization models, and 2) end-to-end (E2E) models that directly convert speech into a text summary. While E2E models are appealing to develop compute-efficient models, they perform worse than cascade models. Therefore, we propose knowledge distillation for E2E models using pseudo-summaries generated by the cascade models. Our experiments show that this proposed knowledge distillation effectively improves the performance of the E2E model on both datasets.
Read more8/2/2024
🗣️
0
Cross-Lingual Conversational Speech Summarization with Large Language Models
Max Nelson, Shannon Wotherspoon, Francis Keith, William Hartmann, Matthew Snover
Cross-lingual conversational speech summarization is an important problem, but suffers from a dearth of resources. While transcriptions exist for a number of languages, translated conversational speech is rare and datasets containing summaries are non-existent. We build upon the existing Fisher and Callhome Spanish-English Speech Translation corpus by supplementing the translations with summaries. The summaries are generated using GPT-4 from the reference translations and are treated as ground truth. The task is to generate similar summaries in the presence of transcription and translation errors. We build a baseline cascade-based system using open-source speech recognition and machine translation models. We test a range of LLMs for summarization and analyze the impact of transcription and translation errors. Adapting the Mistral-7B model for this task performs significantly better than off-the-shelf models and matches the performance of GPT-4.
Read more8/14/2024