Integrating Pre-Trained Speech and Language Models for End-to-End Speech Recognition
2312.03668
0
0

Abstract
Advances in machine learning have made it possible to perform various text and speech processing tasks, such as automatic speech recognition (ASR), in an end-to-end (E2E) manner. E2E approaches utilizing pre-trained models are gaining attention for conserving training data and resources. However, most of their applications in ASR involve only one of either a pre-trained speech or a language model. This paper proposes integrating a pre-trained speech representation model and a large language model (LLM) for E2E ASR. The proposed model enables the optimization of the entire ASR process, including acoustic feature extraction and acoustic and language modeling, by combining pre-trained models with a bridge network and also enables the application of remarkable developments in LLM utilization, such as parameter-efficient domain adaptation and inference optimization. Experimental results demonstrate that the proposed model achieves a performance comparable to that of modern E2E ASR models by utilizing powerful pre-training models with the proposed integrated approach.
Create account to get full access
Overview
- This paper presents an integration of pre-trained speech and language models for end-to-end speech recognition.
- The proposed approach leverages the strengths of both speech and language models to improve the performance of speech recognition systems.
- The researchers explore different ways of combining these pre-trained models to achieve better recognition accuracy.
Plain English Explanation
Speech recognition is the process of converting spoken audio into text. This can be a challenging task, as speech can be influenced by factors like accents, background noise, and individual speaking styles. To address these challenges, researchers have developed various techniques, including the use of speech models and language models.
In this paper, the authors propose a new approach that combines pre-trained speech and language models to create a more robust and accurate speech recognition system. The idea is to use the strengths of both models to improve the overall performance. For example, the speech model can help with understanding the acoustic patterns of the speech, while the language model can provide context and help correct any mistakes made by the speech model.
The researchers experiment with different ways of integrating these pre-trained models, such as using them together in a single neural network or passing the output of one model as input to the other. By doing this, they aim to create a more accurate and reliable speech recognition system that can handle a wide range of speech patterns and accents.
Technical Explanation
The paper presents an integration of pre-trained speech and language models for end-to-end speech recognition. The key elements of their approach include:
-
Speech Model: The researchers use a pre-trained speech recognition model to process the input audio and generate a sequence of predicted text.
-
Language Model: They also use a pre-trained language model to provide additional context and improve the accuracy of the predicted text.
-
Integration Strategies: The authors explore different ways of combining the speech and language models, such as:
- Feeding the output of the speech model directly into the language model.
- Jointly training the speech and language models in a single neural network.
- Using the language model to rescore the output of the speech model.
-
Experiments: The researchers conduct experiments on various speech recognition benchmarks to evaluate the performance of their integrated approach. They compare the results to standalone speech and language models, as well as other state-of-the-art speech recognition systems.
Critical Analysis
The paper presents a well-designed study that explores the potential benefits of integrating pre-trained speech and language models for speech recognition. The researchers have carefully considered different strategies for combining these models and have conducted a thorough evaluation on multiple datasets.
One potential limitation of the study is that it focuses on a relatively narrow set of integration strategies. There may be other ways of combining speech and language models that could further improve performance, such as multimodal approaches that incorporate additional sources of information (e.g., visual cues).
Additionally, the paper does not delve deeply into the underlying reasons why the integrated model outperforms the standalone models. It would be helpful to have a more detailed analysis of the strengths and weaknesses of each component model and how their integration addresses the limitations of individual models.
Conclusion
This paper presents a promising approach for improving the performance of speech recognition systems by integrating pre-trained speech and language models. The researchers have demonstrated the effectiveness of their integrated model on various benchmarks, showcasing the potential benefits of combining complementary sources of information for speech recognition tasks.
The findings of this study could have important implications for the development of more accurate and robust speech recognition systems, which could have applications in a wide range of domains, from voice assistants to transcription services. Further research in this area, exploring additional integration strategies and evaluating the approach on more diverse datasets, could lead to even greater advancements in the field of speech recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
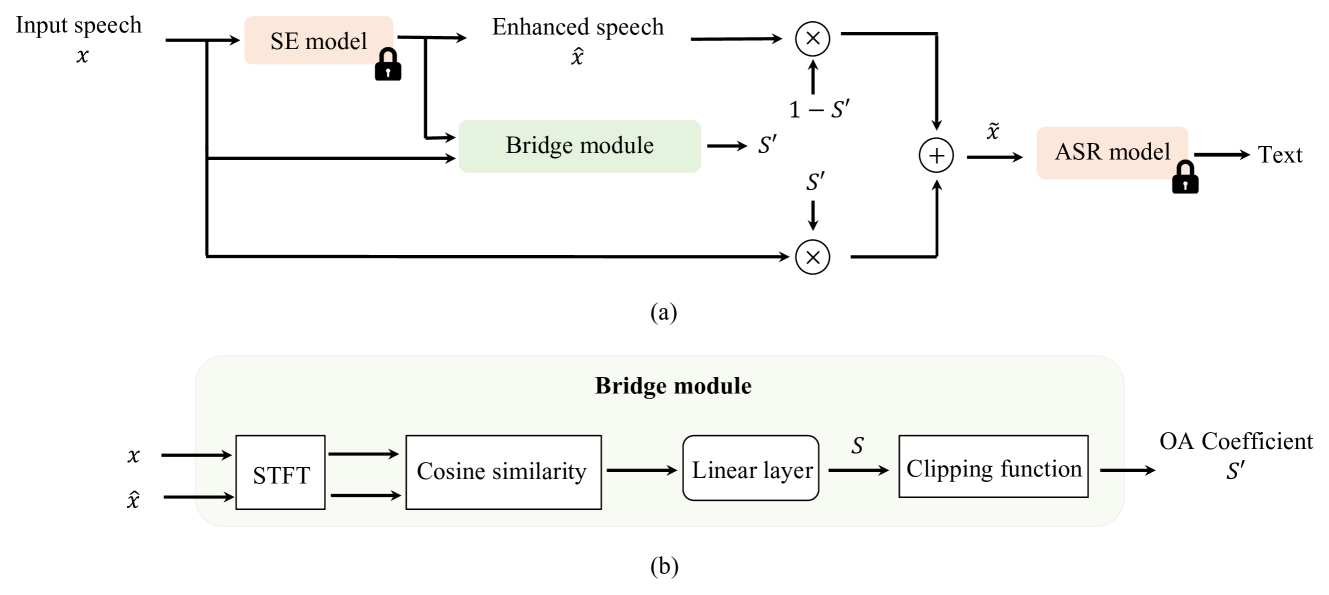
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
0
0
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
6/19/2024
🗣️
Enhancing CTC-based speech recognition with diverse modeling units
Shiyi Han, Zhihong Lei, Mingbin Xu, Xingyu Na, Zhen Huang
0
0
In recent years, the evolution of end-to-end (E2E) automatic speech recognition (ASR) models has been remarkable, largely due to advances in deep learning architectures like transformer. On top of E2E systems, researchers have achieved substantial accuracy improvement by rescoring E2E model's N-best hypotheses with a phoneme-based model. This raises an interesting question about where the improvements come from other than the system combination effect. We examine the underlying mechanisms driving these gains and propose an efficient joint training approach, where E2E models are trained jointly with diverse modeling units. This methodology does not only align the strengths of both phoneme and grapheme-based models but also reveals that using these diverse modeling units in a synergistic way can significantly enhance model accuracy. Our findings offer new insights into the optimal integration of heterogeneous modeling units in the development of more robust and accurate ASR systems.
6/12/2024
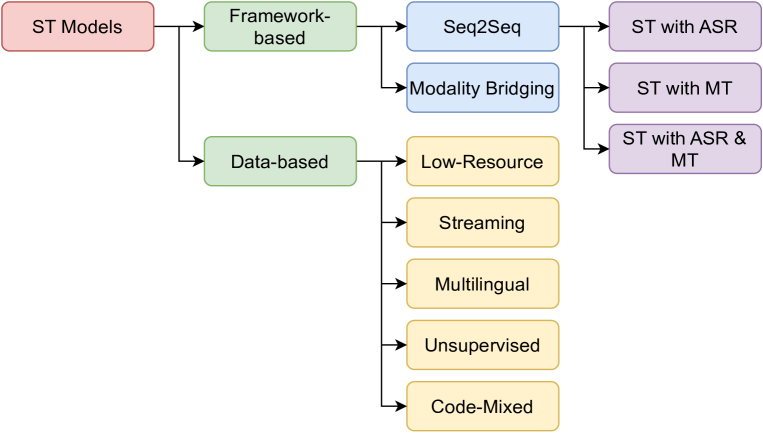
End-to-End Speech-to-Text Translation: A Survey
Nivedita Sethiya, Chandresh Kumar Maurya
0
0
Speech-to-text translation pertains to the task of converting speech signals in a language to text in another language. It finds its application in various domains, such as hands-free communication, dictation, video lecture transcription, and translation, to name a few. Automatic Speech Recognition (ASR), as well as Machine Translation(MT) models, play crucial roles in traditional ST translation, enabling the conversion of spoken language in its original form to written text and facilitating seamless cross-lingual communication. ASR recognizes spoken words, while MT translates the transcribed text into the target language. Such disintegrated models suffer from cascaded error propagation and high resource and training costs. As a result, researchers have been exploring end-to-end (E2E) models for ST translation. However, to our knowledge, there is no comprehensive review of existing works on E2E ST. The present survey, therefore, discusses the work in this direction. Our attempt has been to provide a comprehensive review of models employed, metrics, and datasets used for ST tasks, providing challenges and future research direction with new insights. We believe this review will be helpful to researchers working on various applications of ST models.
6/11/2024
Zero-Shot End-To-End Spoken Question Answering In Medical Domain
Yanis Labrak, Adel Moumen, Richard Dufour, Mickael Rouvier
0
0
In the rapidly evolving landscape of spoken question-answering (SQA), the integration of large language models (LLMs) has emerged as a transformative development. Conventional approaches often entail the use of separate models for question audio transcription and answer selection, resulting in significant resource utilization and error accumulation. To tackle these challenges, we explore the effectiveness of end-to-end (E2E) methodologies for SQA in the medical domain. Our study introduces a novel zero-shot SQA approach, compared to traditional cascade systems. Through a comprehensive evaluation conducted on a new open benchmark of 8 medical tasks and 48 hours of synthetic audio, we demonstrate that our approach requires up to 14.7 times fewer resources than a combined 1.3B parameters LLM with a 1.55B parameters ASR model while improving average accuracy by 0.5%. These findings underscore the potential of E2E methodologies for SQA in resource-constrained contexts.
6/11/2024