Abstractive Text Summarization: State of the Art, Challenges, and Improvements

0
Sign in to get full access
Overview
- Provides a comprehensive review of the state-of-the-art in abstractive text summarization
- Discusses the key challenges and limitations of current approaches
- Suggests potential improvements and future research directions
Plain English Explanation
Abstractive text summarization is the process of generating a concise summary of a longer document using natural language generation techniques. This paper provides an in-depth overview of the current state of this field, including the key advancements and remaining challenges.
The paper begins by examining previous surveys on abstractive summarization, highlighting how this review builds upon and extends that prior work. It then delves into the core challenges facing abstractive summarization, such as the difficulty of accurately capturing the salient information and maintaining coherence and fluency in the generated summaries.
The paper also explores recent progress in abstractive summarization, including the development of advanced neural network architectures and the incorporation of techniques like reinforcement learning and multi-task learning. It discusses how these approaches have led to improvements in summary quality and the ability to handle longer and more complex input texts.
However, the paper also highlights ongoing limitations of current abstractive summarization models, such as their tendency to generate generic or repetitive content, and their sensitivity to the specific data they were trained on. The paper suggests that addressing these challenges will be a key focus of future research in this field.
Technical Explanation
The paper provides an overview of the state-of-the-art in abstractive text summarization, including a discussion of previous surveys on the topic and the key challenges facing the field.
One of the main challenges highlighted in the paper is the difficulty of accurately capturing the salient information from the input text and generating a coherent, fluent summary. The paper also notes issues with current models, such as their tendency to produce generic or repetitive content and their sensitivity to the training data.
The paper then reviews recent advancements in abstractive summarization, including the use of advanced neural network architectures and techniques like reinforcement learning and multi-task learning. These approaches have led to improvements in summary quality and the ability to handle longer, more complex input texts.
However, the paper also discusses the ongoing limitations of current abstractive summarization models, suggesting that addressing these challenges will be a key focus of future research in this field.
Critical Analysis
The paper provides a comprehensive and well-structured review of the current state of abstractive text summarization. It effectively highlights the key challenges and limitations of existing approaches, while also acknowledging the significant progress that has been made in recent years.
One potential area for further exploration mentioned in the paper is the need to improve the robustness and generalization of abstractive summarization models, so they can handle a wider range of input texts and maintain consistent performance. Additionally, the paper suggests that developing a better understanding of the cognitive processes involved in human summarization could inform the design of more effective artificial summarization systems.
Overall, the paper provides a valuable resource for researchers and practitioners working in the field of text summarization, offering a detailed analysis of the current state of the art and a roadmap for future research and development.
Conclusion
This paper offers a comprehensive review of the field of abstractive text summarization, highlighting both the significant progress that has been made and the remaining challenges that need to be addressed. By outlining the key advancements and limitations of current approaches, the paper provides a useful framework for guiding future research and development in this important area of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Abstractive Text Summarization: State of the Art, Challenges, and Improvements
Hassan Shakil, Ahmad Farooq, Jugal Kalita
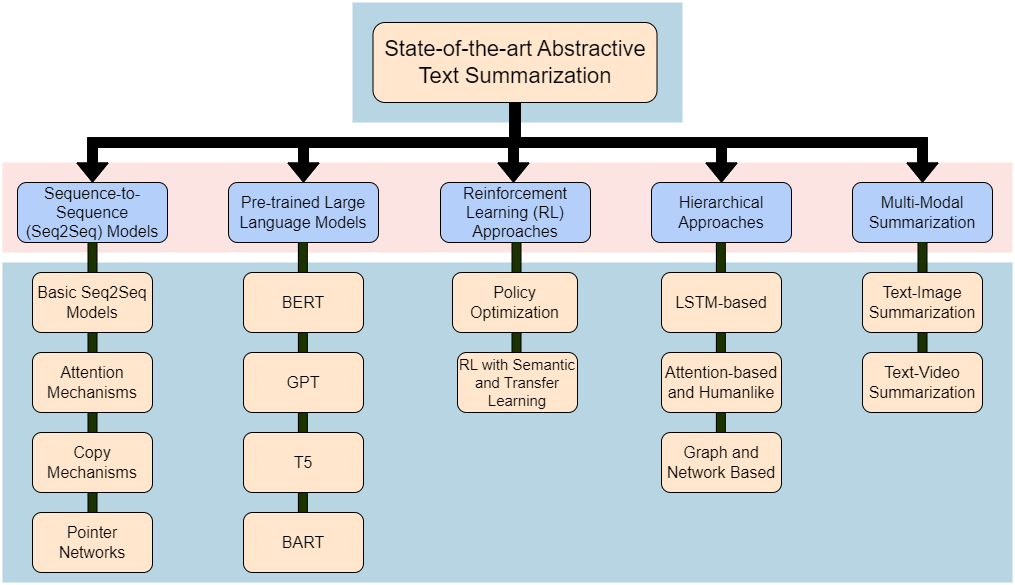
Specifically focusing on the landscape of abstractive text summarization, as opposed to extractive techniques, this survey presents a comprehensive overview, delving into state-of-the-art techniques, prevailing challenges, and prospective research directions. We categorize the techniques into traditional sequence-to-sequence models, pre-trained large language models, reinforcement learning, hierarchical methods, and multi-modal summarization. Unlike prior works that did not examine complexities, scalability and comparisons of techniques in detail, this review takes a comprehensive approach encompassing state-of-the-art methods, challenges, solutions, comparisons, limitations and charts out future improvements - providing researchers an extensive overview to advance abstractive summarization research. We provide vital comparison tables across techniques categorized - offering insights into model complexity, scalability and appropriate applications. The paper highlights challenges such as inadequate meaning representation, factual consistency, controllable text summarization, cross-lingual summarization, and evaluation metrics, among others. Solutions leveraging knowledge incorporation and other innovative strategies are proposed to address these challenges. The paper concludes by highlighting emerging research areas like factual inconsistency, domain-specific, cross-lingual, multilingual, and long-document summarization, as well as handling noisy data. Our objective is to provide researchers and practitioners with a structured overview of the domain, enabling them to better understand the current landscape and identify potential areas for further research and improvement.
Read more9/5/2024
🤔
0
Synthesizing Scientific Summaries: An Extractive and Abstractive Approach
Grishma Sharma, Aditi Paretkar, Deepak Sharma
The availability of a vast array of research papers in any area of study, necessitates the need of automated summarisation systems that can present the key research conducted and their corresponding findings. Scientific paper summarisation is a challenging task for various reasons including token length limits in modern transformer models and corresponding memory and compute requirements for long text. A significant amount of work has been conducted in this area, with approaches that modify the attention mechanisms of existing transformer models and others that utilise discourse information to capture long range dependencies in research papers. In this paper, we propose a hybrid methodology for research paper summarisation which incorporates an extractive and abstractive approach. We use the extractive approach to capture the key findings of research, and pair it with the introduction of the paper which captures the motivation for research. We use two models based on unsupervised learning for the extraction stage and two transformer language models, resulting in four combinations for our hybrid approach. The performances of the models are evaluated on three metrics and we present our findings in this paper. We find that using certain combinations of hyper parameters, it is possible for automated summarisation systems to exceed the abstractiveness of summaries written by humans. Finally, we state our future scope of research in extending this methodology to summarisation of generalised long documents.
Read more7/30/2024

0
A Systematic Survey of Text Summarization: From Statistical Methods to Large Language Models
Haopeng Zhang, Philip S. Yu, Jiawei Zhang
Text summarization research has undergone several significant transformations with the advent of deep neural networks, pre-trained language models (PLMs), and recent large language models (LLMs). This survey thus provides a comprehensive review of the research progress and evolution in text summarization through the lens of these paradigm shifts. It is organized into two main parts: (1) a detailed overview of datasets, evaluation metrics, and summarization methods before the LLM era, encompassing traditional statistical methods, deep learning approaches, and PLM fine-tuning techniques, and (2) the first detailed examination of recent advancements in benchmarking, modeling, and evaluating summarization in the LLM era. By synthesizing existing literature and presenting a cohesive overview, this survey also discusses research trends, open challenges, and proposes promising research directions in summarization, aiming to guide researchers through the evolving landscape of summarization research.
Read more6/18/2024

0
CADS: A Systematic Literature Review on the Challenges of Abstractive Dialogue Summarization
Frederic Kirstein, Jan Philip Wahle, Bela Gipp, Terry Ruas
Abstractive dialogue summarization is the task of distilling conversations into informative and concise summaries. Although reviews have been conducted on this topic, there is a lack of comprehensive work detailing the challenges of dialogue summarization, unifying the differing understanding of the task, and aligning proposed techniques, datasets, and evaluation metrics with the challenges. This article summarizes the research on Transformer-based abstractive summarization for English dialogues by systematically reviewing 1262 unique research papers published between 2019 and 2024, relying on the Semantic Scholar and DBLP databases. We cover the main challenges present in dialog summarization (i.e., language, structure, comprehension, speaker, salience, and factuality) and link them to corresponding techniques such as graph-based approaches, additional training tasks, and planning strategies, which typically overly rely on BART-based encoder-decoder models. We find that while some challenges, like language, have seen considerable progress, mainly due to training methods, others, such as comprehension, factuality, and salience, remain difficult and hold significant research opportunities. We investigate how these approaches are typically assessed, covering the datasets for the subdomains of dialogue (e.g., meeting, medical), the established automatic metrics and human evaluation approaches for assessing scores and annotator agreement. We observe that only a few datasets span across all subdomains. The ROUGE metric is the most used, while human evaluation is frequently reported without sufficient detail on inner-annotator agreement and annotation guidelines. Additionally, we discuss the possible implications of the recently explored large language models and conclude that despite a potential shift in relevance and difficulty, our described challenge taxonomy remains relevant.
Read more6/13/2024