Synthesizing Scientific Summaries: An Extractive and Abstractive Approach

0
🤔
Sign in to get full access
Overview
- Automated summarization systems are needed to present key research findings from the vast array of available research papers.
- Summarizing scientific papers is challenging due to token length limits and compute requirements for long text.
- Existing approaches modify attention mechanisms or use discourse information to capture dependencies in papers.
- This paper proposes a hybrid methodology for research paper summarization using both extractive and abstractive techniques.
Plain English Explanation
The availability of a vast array of research papers in any field means we need automated systems that can summarize the key research and findings. Summarizing scientific papers is difficult because modern AI language models have limits on the length of text they can process, and it requires a lot of computing power to handle long documents.
Researchers have tried different approaches to this problem, like modifying the attention mechanisms of existing language models or using information about the structure of the paper to capture important connections.
In this paper, the authors propose a new hybrid method that combines extractive and abstractive summarization. The extractive part identifies the key findings, while the abstractive part uses the paper's introduction to capture the motivation for the research. They test different combinations of unsupervised and transformer-based models for this hybrid approach and evaluate the results.
The paper finds that certain configurations of the hybrid model can produce summaries that are even more abstractive than ones written by humans. The researchers plan to extend this methodology to summarizing other types of long documents in the future.
Technical Explanation
The authors propose a hybrid methodology for research paper summarization that combines an extractive and an abstractive approach.
The extractive component is used to identify the key findings reported in the paper. The authors experiment with two unsupervised models for this stage: TextRank and LexRank. These models analyze the structure and content of the paper to determine the most salient sentences.
The abstractive component leverages the paper's introduction, which typically captures the motivation and context for the research. The authors pair the extractive summaries with the introduction using two different transformer language models: BART and T5.
This results in four hybrid summarization combinations that the authors evaluate on three different metrics: ROUGE, BERTScore, and human evaluations. The experiments show that certain configurations of the hybrid model can produce summaries that are more abstractive than human-written ones.
Critical Analysis
The paper presents a well-designed study that explores the potential of hybrid summarization techniques for research papers. The authors thoughtfully combine extractive and abstractive approaches, leveraging both the key findings and the context provided in the introduction.
One potential limitation is that the evaluation is focused on summarization quality rather than practical utility. It would be interesting to see how these summaries perform in real-world applications, such as helping researchers quickly identify relevant papers or aiding students in understanding complex research.
Additionally, the paper does not delve into the cognitive biases or limitations that may arise from relying on automated summaries. As these systems become more advanced, it will be important to understand how they might amplify or introduce new biases, and how to mitigate such issues.
Overall, this research represents a promising step forward in the field of automated scientific paper summarization. Further exploration of hybrid approaches, as well as investigations into the real-world impacts and potential pitfalls, could yield valuable insights for improving research discoverability and comprehension.
Conclusion
This paper presents a novel hybrid approach to research paper summarization that combines extractive and abstractive techniques. The authors demonstrate that certain configurations of their model can produce summaries that are more abstractive than those written by humans.
The research highlights the potential of hybrid methods to address the challenges of summarizing long, complex scientific documents. By leveraging both the key findings and the contextual information in the paper, the authors have developed a promising framework for automated summarization.
As the authors note, extending this methodology to summarize other types of long-form documents could have broader implications for improving information access and comprehension. Further research in this direction, with a focus on real-world applications and potential biases, could lead to powerful tools for researchers, students, and the general public.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
Synthesizing Scientific Summaries: An Extractive and Abstractive Approach
Grishma Sharma, Aditi Paretkar, Deepak Sharma
The availability of a vast array of research papers in any area of study, necessitates the need of automated summarisation systems that can present the key research conducted and their corresponding findings. Scientific paper summarisation is a challenging task for various reasons including token length limits in modern transformer models and corresponding memory and compute requirements for long text. A significant amount of work has been conducted in this area, with approaches that modify the attention mechanisms of existing transformer models and others that utilise discourse information to capture long range dependencies in research papers. In this paper, we propose a hybrid methodology for research paper summarisation which incorporates an extractive and abstractive approach. We use the extractive approach to capture the key findings of research, and pair it with the introduction of the paper which captures the motivation for research. We use two models based on unsupervised learning for the extraction stage and two transformer language models, resulting in four combinations for our hybrid approach. The performances of the models are evaluated on three metrics and we present our findings in this paper. We find that using certain combinations of hyper parameters, it is possible for automated summarisation systems to exceed the abstractiveness of summaries written by humans. Finally, we state our future scope of research in extending this methodology to summarisation of generalised long documents.
Read more7/30/2024
0
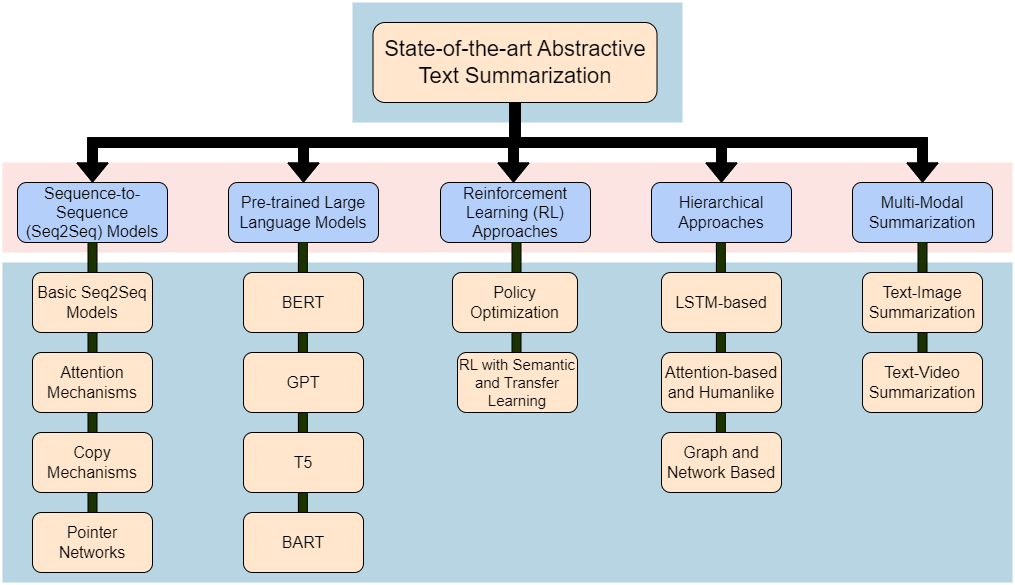
Abstractive Text Summarization: State of the Art, Challenges, and Improvements
Hassan Shakil, Ahmad Farooq, Jugal Kalita
Specifically focusing on the landscape of abstractive text summarization, as opposed to extractive techniques, this survey presents a comprehensive overview, delving into state-of-the-art techniques, prevailing challenges, and prospective research directions. We categorize the techniques into traditional sequence-to-sequence models, pre-trained large language models, reinforcement learning, hierarchical methods, and multi-modal summarization. Unlike prior works that did not examine complexities, scalability and comparisons of techniques in detail, this review takes a comprehensive approach encompassing state-of-the-art methods, challenges, solutions, comparisons, limitations and charts out future improvements - providing researchers an extensive overview to advance abstractive summarization research. We provide vital comparison tables across techniques categorized - offering insights into model complexity, scalability and appropriate applications. The paper highlights challenges such as inadequate meaning representation, factual consistency, controllable text summarization, cross-lingual summarization, and evaluation metrics, among others. Solutions leveraging knowledge incorporation and other innovative strategies are proposed to address these challenges. The paper concludes by highlighting emerging research areas like factual inconsistency, domain-specific, cross-lingual, multilingual, and long-document summarization, as well as handling noisy data. Our objective is to provide researchers and practitioners with a structured overview of the domain, enabling them to better understand the current landscape and identify potential areas for further research and improvement.
Read more9/5/2024

0
Summarizing long regulatory documents with a multi-step pipeline
Mika Sie, Ruby Beek, Michiel Bots, Sjaak Brinkkemper, Albert Gatt
Due to their length and complexity, long regulatory texts are challenging to summarize. To address this, a multi-step extractive-abstractive architecture is proposed to handle lengthy regulatory documents more effectively. In this paper, we show that the effectiveness of a two-step architecture for summarizing long regulatory texts varies significantly depending on the model used. Specifically, the two-step architecture improves the performance of decoder-only models. For abstractive encoder-decoder models with short context lengths, the effectiveness of an extractive step varies, whereas for long-context encoder-decoder models, the extractive step worsens their performance. This research also highlights the challenges of evaluating generated texts, as evidenced by the differing results from human and automated evaluations. Most notably, human evaluations favoured language models pretrained on legal text, while automated metrics rank general-purpose language models higher. The results underscore the importance of selecting the appropriate summarization strategy based on model architecture and context length.
Read more8/20/2024
0
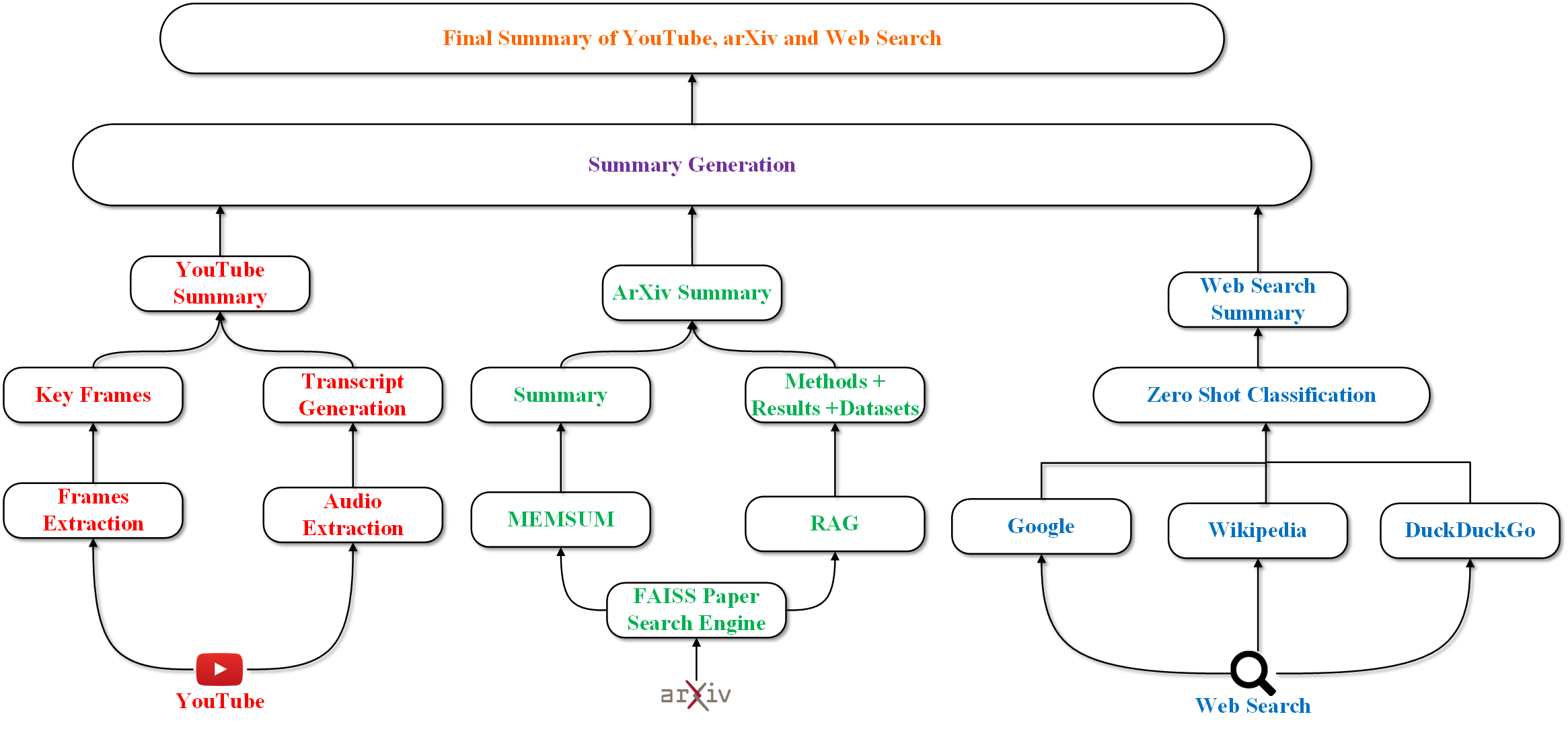
Converging Dimensions: Information Extraction and Summarization through Multisource, Multimodal, and Multilingual Fusion
Pranav Janjani, Mayank Palan, Sarvesh Shirude, Ninad Shegokar, Sunny Kumar, Faruk Kazi
Recent advances in large language models (LLMs) have led to new summarization strategies, offering an extensive toolkit for extracting important information. However, these approaches are frequently limited by their reliance on isolated sources of data. The amount of information that can be gathered is limited and covers a smaller range of themes, which introduces the possibility of falsified content and limited support for multilingual and multimodal data. The paper proposes a novel approach to summarization that tackles such challenges by utilizing the strength of multiple sources to deliver a more exhaustive and informative understanding of intricate topics. The research progresses beyond conventional, unimodal sources such as text documents and integrates a more diverse range of data, including YouTube playlists, pre-prints, and Wikipedia pages. The aforementioned varied sources are then converted into a unified textual representation, enabling a more holistic analysis. This multifaceted approach to summary generation empowers us to extract pertinent information from a wider array of sources. The primary tenet of this approach is to maximize information gain while minimizing information overlap and maintaining a high level of informativeness, which encourages the generation of highly coherent summaries.
Read more6/21/2024