Accelerating Distributed MoE Training and Inference with Lina

0
🏋️
Sign in to get full access
Overview
- Scaling model parameters can improve model quality, but at the cost of high computational overhead.
- Sparsely activated Mixture of Experts (MoE) models can provide a more efficient alternative, with sub-linear scaling of computation cost as the model size increases.
- However, distributed MoE training and inference can be inefficient due to the high communication overhead from the all-to-all operations.
Plain English Explanation
Machine learning models can be made more powerful by increasing the number of parameters (the internal variables that the model learns from data). However, this increase in model size also requires more computational power to train and run the model, which can be costly and inefficient.
An alternative approach is to use Mixture of Experts (MoE) models, where the model is divided into smaller "expert" components that are selectively activated based on the input. This allows for larger overall model sizes without a proportional increase in computational cost.
However, the way these MoE models are distributed and run across multiple computers or devices can still be inefficient, mainly due to the way the different expert components need to communicate with each other during the computation process. This communication, known as "all-to-all" communication, can become a bottleneck that slows down both the training and the inference (the process of using the trained model to make predictions) of the MoE models.
Technical Explanation
The paper makes two main contributions to address the inefficiencies in distributed MoE training and inference:
-
Systematic Analysis of All-to-All Overhead: The researchers thoroughly analyze the causes of the all-to-all communication bottleneck in both the training and inference phases of distributed MoE models. They identify the key factors that lead to this inefficiency.
-
Lina System Design: The researchers propose a new system called Lina that addresses the all-to-all bottleneck. Lina opportunistically prioritizes all-to-all operations over concurrent allreduce operations whenever possible, using tensor partitioning techniques. This helps improve the overall efficiency of the all-to-all communication. Lina also dynamically schedules resources during inference to balance the transfer size and bandwidth of all-to-all operations, as the popularity of different experts can be highly skewed in practice.
The researchers evaluate Lina on an A100 GPU testbed and show that it can reduce the training step time by up to 1.73x and the 95th percentile inference time by an average of 1.63x compared to state-of-the-art systems.
Critical Analysis
The paper provides a thorough analysis of the all-to-all communication bottleneck in distributed MoE models and presents a novel system design to address it. However, the researchers do not discuss potential limitations or areas for further research in-depth.
One potential concern is the generalizability of the Lina system - it's unclear how well it would scale to even larger MoE models or different hardware configurations beyond the A100 GPU testbed used in the experiments. Additionally, the paper does not explore the impact of Lina on other important metrics, such as model accuracy or training stability, beyond the improvements in training and inference time.
Further research could investigate the tradeoffs and potential pitfalls of the Lina approach, as well as explore alternative techniques for improving the efficiency of distributed MoE models.
Conclusion
This paper makes an important contribution to the field of efficient large-scale machine learning by addressing a key bottleneck in the deployment of Mixture of Experts models. The Lina system design demonstrates the potential for significant performance improvements in both the training and inference of these models, which could enable the use of even larger and more powerful models in practical applications. While the paper does not explore all the potential limitations, it provides a solid foundation for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Accelerating Distributed MoE Training and Inference with Lina
Jiamin Li, Yimin Jiang, Yibo Zhu, Cong Wang, Hong Xu
Scaling model parameters improves model quality at the price of high computation overhead. Sparsely activated models, usually in the form of Mixture of Experts (MoE) architecture, have sub-linear scaling of computation cost with model size, thus providing opportunities to train and serve a larger model at lower cost than their dense counterparts. However, distributed MoE training and inference is inefficient, mainly due to the interleaved all-to-all communication during model computation. This paper makes two main contributions. First, we systematically analyze all-to-all overhead in distributed MoE and present the main causes for it to be the bottleneck in training and inference, respectively. Second, we design and build Lina to address the all-to-all bottleneck head-on. Lina opportunistically prioritizes all-to-all over the concurrent allreduce whenever feasible using tensor partitioning, so all-to-all and training step time is improved. Lina further exploits the inherent pattern of expert selection to dynamically schedule resources during inference, so that the transfer size and bandwidth of all-to-all across devices are balanced amid the highly skewed expert popularity in practice. Experiments on an A100 GPU testbed show that Lina reduces the training step time by up to 1.73x and reduces the 95%ile inference time by an average of 1.63x over the state-of-the-art systems.
Read more4/30/2024

0
Lancet: Accelerating Mixture-of-Experts Training via Whole Graph Computation-Communication Overlapping
Chenyu Jiang, Ye Tian, Zhen Jia, Shuai Zheng, Chuan Wu, Yida Wang
The Mixture-of-Expert (MoE) technique plays a crucial role in expanding the size of DNN model parameters. However, it faces the challenge of extended all-to-all communication latency during the training process. Existing methods attempt to mitigate this issue by overlapping all-to-all with expert computation. Yet, these methods frequently fall short of achieving sufficient overlap, consequently restricting the potential for performance enhancements. In our study, we extend the scope of this challenge by considering overlap at the broader training graph level. During the forward pass, we enable non-MoE computations to overlap with all-to-all through careful partitioning and pipelining. In the backward pass, we achieve overlap with all-to-all by scheduling gradient weight computations. We implement these techniques in Lancet, a system using compiler-based optimization to automatically enhance MoE model training. Our extensive evaluation reveals that Lancet significantly reduces the time devoted to non-overlapping communication, by as much as 77%. Moreover, it achieves a notable end-to-end speedup of up to 1.3 times when compared to the state-of-the-art solutions.
Read more5/1/2024
0
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda
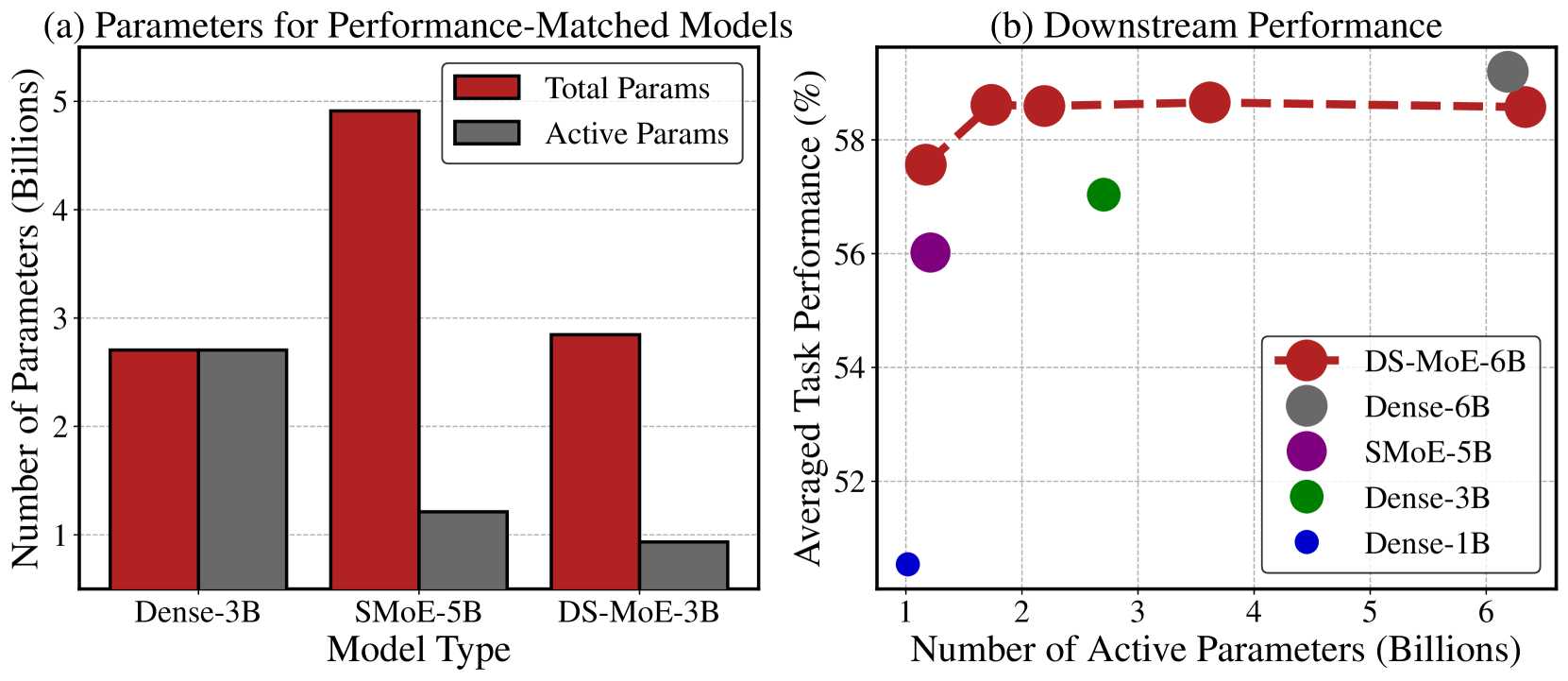
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
Read more4/9/2024
0
LocMoE: A Low-Overhead MoE for Large Language Model Training
Jing Li, Zhijie Sun, Xuan He, Li Zeng, Yi Lin, Entong Li, Binfan Zheng, Rongqian Zhao, Xin Chen
The Mixtures-of-Experts (MoE) model is a widespread distributed and integrated learning method for large language models (LLM), which is favored due to its ability to sparsify and expand models efficiently. However, the performance of MoE is limited by load imbalance and high latency of All-to-All communication, along with relatively redundant computation owing to large expert capacity. Load imbalance may result from existing routing policies that consistently tend to select certain experts. The frequent inter-node communication in the All-to-All procedure also significantly prolongs the training time. To alleviate the above performance problems, we propose a novel routing strategy that combines load balance and locality by converting partial inter-node communication to that of intra-node. Notably, we elucidate that there is a minimum threshold for expert capacity, calculated through the maximal angular deviation between the gating weights of the experts and the assigned tokens. We port these modifications on the PanGu-Sigma model based on the MindSpore framework with multi-level routing and conduct experiments on Ascend clusters. The experiment results demonstrate that the proposed LocMoE reduces training time per epoch by 12.68% to 22.24% compared to classical routers, such as hash router and switch router, without impacting the model accuracy.
Read more5/24/2024